 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Information for Improving Spatial Relationships in Text-to-Image Generation
Sep 19, 2025
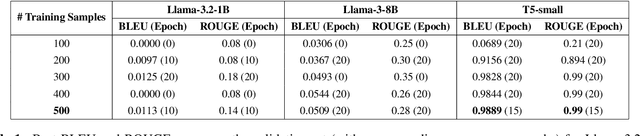
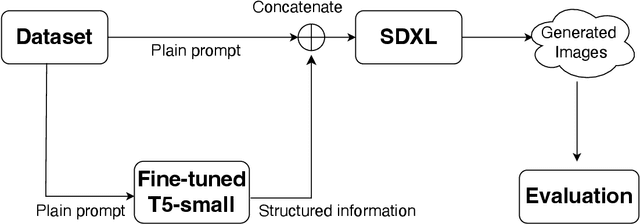

Text-to-image (T2I) generation has advanced rapidly, yet faithfully capturing spatial relationships described in natural language prompts remains a major challenge. Prior efforts have addressed this issue through prompt optimization, spatially grounded generation, and semantic refinement. This work introduces a lightweight approach that augments prompts with tuple-based structured information, using a fine-tuned language model for automatic conversion and seamless integration into T2I pipelines. Experimental results demonstrate substantial improvements in spatial accuracy, without compromising overall image quality as measured by Inception Score. Furthermore, the automatically generated tuples exhibit quality comparable to human-crafted tuples. This structured information provides a practical and portable solution to enhance spatial relationships in T2I generation, addressing a key limitation of current large-scale generative systems.
Large Language Models Reasoning Abilities Under Non-Ideal Conditions After RL-Fine-Tuning
Aug 06, 2025Reinforcement learning (RL) has become a key technique for enhancing the reasoning abilities of large language models (LLMs), with policy-gradient algorithms dominating the post-training stage because of their efficiency and effectiveness. However, most existing benchmarks evaluate large-language-model reasoning under idealized settings, overlooking performance in realistic, non-ideal scenarios. We identify three representative non-ideal scenarios with practical relevance: summary inference, fine-grained noise suppression, and contextual filtering. We introduce a new research direction guided by brain-science findings that human reasoning remains reliable under imperfect inputs. We formally define and evaluate these challenging scenarios. We fine-tune three LLMs and a state-of-the-art large vision-language model (LVLM) using RL with a representative policy-gradient algorithm and then test their performance on eight public datasets. Our results reveal that while RL fine-tuning improves baseline reasoning under idealized settings, performance declines significantly across all three non-ideal scenarios, exposing critical limitations in advanced reasoning capabilities. Although we propose a scenario-specific remediation method, our results suggest current methods leave these reasoning deficits largely unresolved. This work highlights that the reasoning abilities of large models are often overstated and underscores the importance of evaluating models under non-ideal scenarios. The code and data will be released at XXXX.
A Generic Method for Fine-grained Category Discovery in Natural Language Texts
Jun 18, 2024


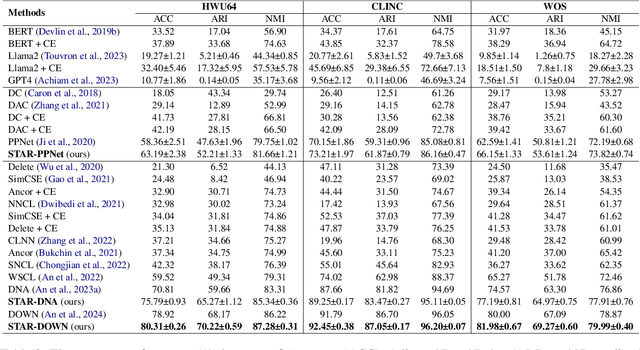
Fine-grained category discovery using only coarse-grained supervision is a cost-effective yet challenging task. Previous training methods focus on aligning query samples with positive samples and distancing them from negatives. They often neglect intra-category and inter-category semantic similarities of fine-grained categories when navigating sample distributions in the embedding space. Furthermore, some evaluation techniques that rely on pre-collected test samples are inadequate for real-time applications. To address these shortcomings, we introduce a method that successfully detects fine-grained clusters of semantically similar texts guided by a novel objective function. The method uses semantic similarities in a logarithmic space to guide sample distributions in the Euclidean space and to form distinct clusters that represent fine-grained categories. We also propose a centroid inference mechanism to support real-time applications. The efficacy of the method is both theoretically justified and empirically confirmed on three benchmark tasks. The proposed objective function is integrated in multiple contrastive learning based neural models. Its results surpass existing state-of-the-art approaches in terms of Accuracy, Adjusted Rand Index and Normalized Mutual Information of the detected fine-grained categories. Code and data will be available at https://github.com/XX upon publication.
Fighting Against the Repetitive Training and Sample Dependency Problem in Few-shot Named Entity Recognition
Jun 08, 2024



Few-shot named entity recognition (NER) systems recognize entities using a few labeled training examples. The general pipeline consists of a span detector to identify entity spans in text and an entity-type classifier to assign types to entities. Current span detectors rely on extensive manual labeling to guide training. Almost every span detector requires initial training on basic span features followed by adaptation to task-specific features. This process leads to repetitive training of the basic span features among span detectors. Additionally, metric-based entity-type classifiers, such as prototypical networks, typically employ a specific metric that gauges the distance between the query sample and entity-type referents, ultimately assigning the most probable entity type to the query sample. However, these classifiers encounter the sample dependency problem, primarily stemming from the limited samples available for each entity-type referent. To address these challenges, we proposed an improved few-shot NER pipeline. First, we introduce a steppingstone span detector that is pre-trained on open-domain Wikipedia data. It can be used to initialize the pipeline span detector to reduce the repetitive training of basic features. Second, we leverage a large language model (LLM) to set reliable entity-type referents, eliminating reliance on few-shot samples of each type. Our model exhibits superior performance with fewer training steps and human-labeled data compared with baselines, as demonstrated through extensive experiments on various datasets. Particularly in fine-grained few-shot NER settings, our model outperforms strong baselines, including ChatGPT. We will publicly release the code, datasets, LLM outputs, and model checkpoints.
Deep Learning Empowered Type-II Codebook: New Perspectives for Enhancing CSI Feedback
May 14, 2023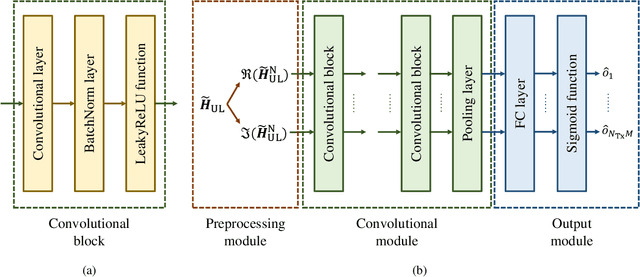
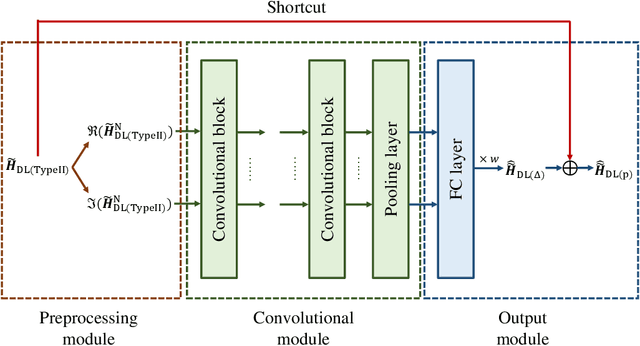
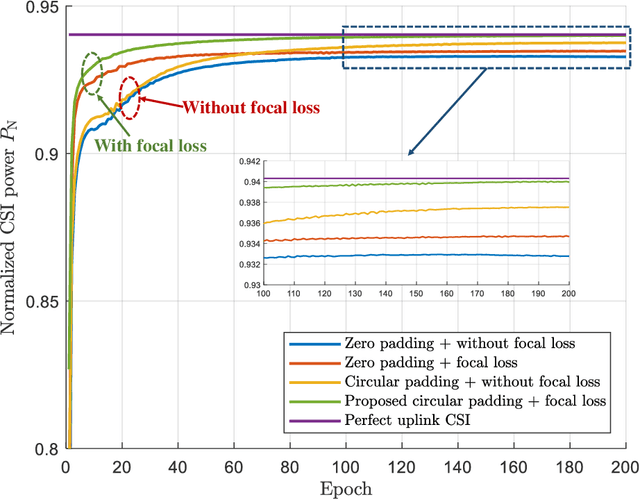
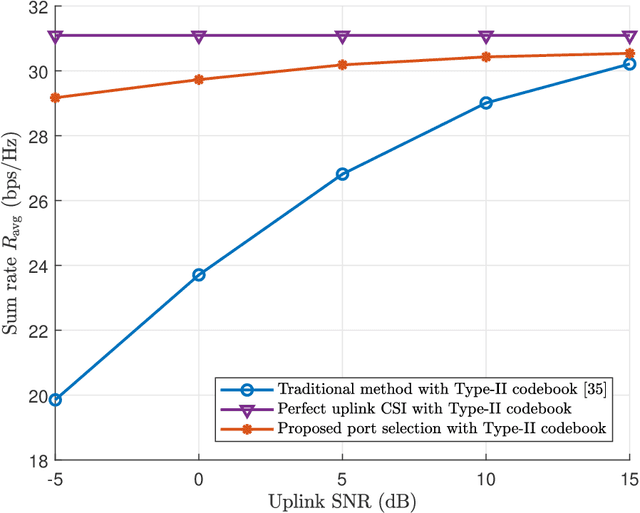
Deep learning based channel state information (CSI) feedback in frequency division duplex systems has drawn widespread attention in both academia and industry. In this paper, we focus on integrating the Type-II codebook in the wireless communication standards with deep learning to enhance the performance of CSI feedback. In contrast to the existing deep learning based studies on the Release 16 Type-II codebook, the Type-II codebook in Release 17 (R17) exploits the angular-delay-domain partial reciprocity between uplink and downlink channels to select part of angular-delay-domain ports for measuring and feeding back the downlink CSI, where the performance of deep learning based conventional methods is limited due to the deficiency of sparse structures. To address this issue, we propose two new perspectives of adopting deep learning to improve the R17 Type-II codebook. Firstly, considering the low signal-to-noise ratio of uplink channels, deep learning is utilized to accurately select the dominant angular-delay-domain ports, where the focal loss is harnessed to solve the class imbalance problem. Secondly, we propose to adopt deep learning to reconstruct the downlink CSI based on the feedback of the R17 Type-II codebook at the base station, where the information of sparse structures can be effectively leveraged. Furthermore, a weighted shortcut module is designed to facilitate the accurate reconstruction, and a two-stage loss function that combines the mean squared error and sum rate is proposed for adapting to practical multi-user scenarios. Simulation results demonstrate that our proposed deep learning based port selection and CSI reconstruction methods can improve the sum rate performance compared with the traditional R17 Type-II codebook and deep learning benchmarks.
Anti-Overestimation Dialogue Policy Learning for Task-Completion Dialogue System
Jul 24, 2022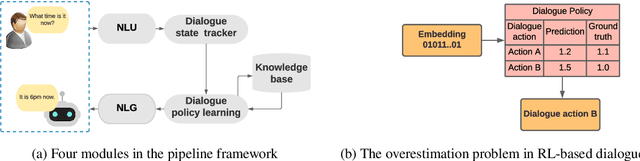



A dialogue policy module is an essential part of task-completion dialogue systems. Recently, increasing interest has focused on reinforcement learning (RL)-based dialogue policy. Its favorable performance and wise action decisions rely on an accurate estimation of action values. The overestimation problem is a widely known issue of RL since its estimate of the maximum action value is larger than the ground truth, which results in an unstable learning process and suboptimal policy. This problem is detrimental to RL-based dialogue policy learning. To mitigate this problem, this paper proposes a dynamic partial average estimator (DPAV) of the ground truth maximum action value. DPAV calculates the partial average between the predicted maximum action value and minimum action value, where the weights are dynamically adaptive and problem-dependent. We incorporate DPAV into a deep Q-network as the dialogue policy and show that our method can achieve better or comparable results compared to top baselines on three dialogue datasets of different domains with a lower computational load. In addition, we also theoretically prove the convergence and derive the upper and lower bounds of the bias compared with those of other methods.
Paint4Poem: A Dataset for Artistic Visualization of Classical Chinese Poems
Sep 27, 2021

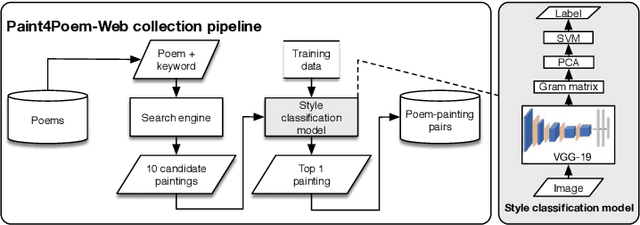
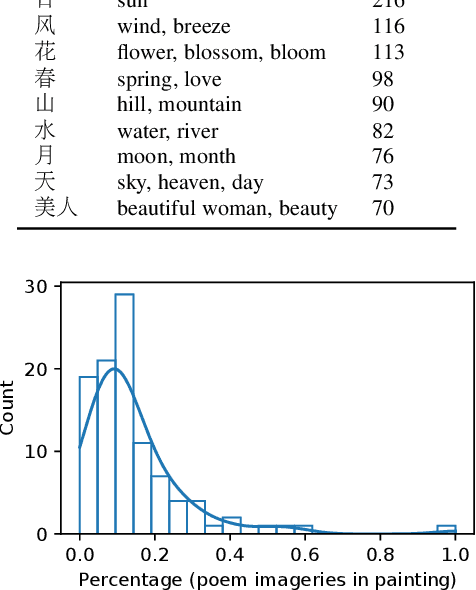
In this work we propose a new task: artistic visualization of classical Chinese poems, where the goal is to generatepaintings of a certain artistic style for classical Chinese poems. For this purpose, we construct a new dataset called Paint4Poem. Thefirst part of Paint4Poem consists of 301 high-quality poem-painting pairs collected manually from an influential modern Chinese artistFeng Zikai. As its small scale poses challenges for effectively training poem-to-painting generation models, we introduce the secondpart of Paint4Poem, which consists of 3,648 caption-painting pairs collected manually from Feng Zikai's paintings and 89,204 poem-painting pairs collected automatically from the web. We expect the former to help learning the artist painting style as it containshis most paintings, and the latter to help learning the semantic relevance between poems and paintings. Further, we analyze Paint4Poem regarding poem diversity, painting style, and the semantic relevance between poems and paintings. We create abenchmark for Paint4Poem: we train two representative text-to-image generation models: AttnGAN and MirrorGAN, and evaluate theirperformance regarding painting pictorial quality, painting stylistic relevance, and semantic relevance between poems and paintings.The results indicate that the models are able to generate paintings that have good pictorial quality and mimic Feng Zikai's style, but thereflection of poem semantics is limited. The dataset also poses many interesting research directions on this task, including transferlearning, few-shot learning, text-to-image generation for low-resource data etc. The dataset is publicly available.(https://github.com/paint4poem/paint4poem)
Successive Convex Approximation Based Off-Policy Optimization for Constrained Reinforcement Learning
May 26, 2021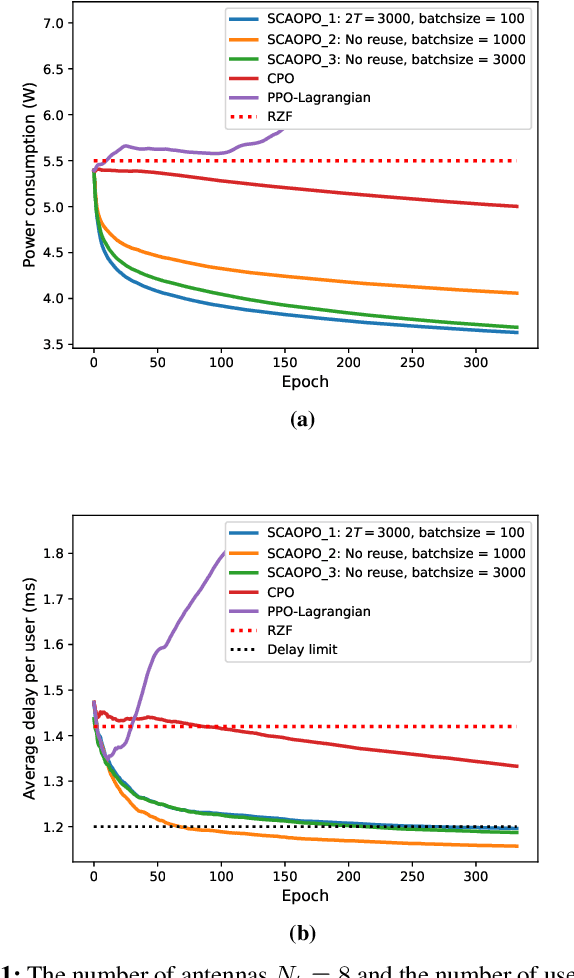
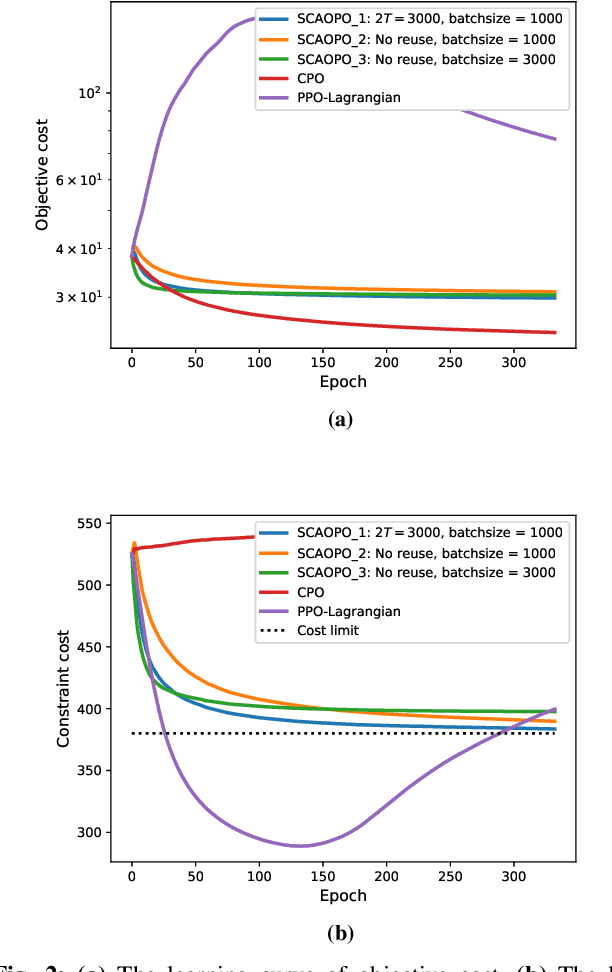
We propose a successive convex approximation based off-policy optimization (SCAOPO) algorithm to solve the general constrained reinforcement learning problem, which is formulated as a constrained Markov decision process (CMDP) in the context of average cost. The SCAOPO is based on solving a sequence of convex objective/feasibility optimization problems obtained by replacing the objective and constraint functions in the original problems with convex surrogate functions. At each iteration, the convex surrogate problem can be efficiently solved by Lagrange dual method even the policy is parameterized by a high-dimensional function. Moreover, the SCAOPO enables to reuse old experiences from previous updates, thereby significantly reducing the implementation cost when deployed in the real-world engineering systems that need to online learn the environment. In spite of the time-varying state distribution and the stochastic bias incurred by the off-policy learning, the SCAOPO with a feasible initial point can still provably converge to a Karush-Kuhn-Tucker (KKT) point of the original problem almost surely.