 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak NAS Predictors Are All You Need
Paper and Code

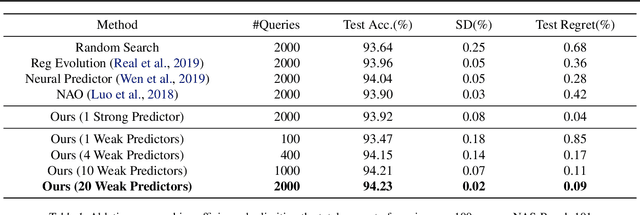
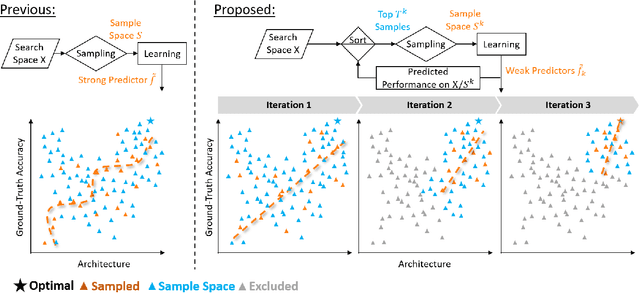

Neural Architecture Search (NAS) finds the best network architecture by exploring the architecture-to-performance manifold. It often trains and evaluates a large number of architectures, causing tremendous computation costs. Recent predictor-based NAS approaches attempt to solve this problem with two key steps: sampling some architecture-performance pairs and fitting a proxy accuracy predictor. Given limited samples, these predictors, however, are far from accurate to locate top architectures. In this paper, we shift the paradigm from finding a complicated predictor that covers the whole architecture space to a set of weaker predictors that progressively move towards the high-performance sub-space. It is based on the key property of the proposed weak predictors that their probabilities of sampling better architectures keep increasing. We thus only sample a few well-performed architectures guided by the previously learned predictor and estimate a new better weak predictor. By this coarse-to-fine iteration, the ranking of sampling space is refined gradually, which helps find the optimal architectures eventually. Experiments demonstrate that our method costs fewer samples to find the top-performance architectures on NAS-Bench-101 and NAS-Bench-201, and it achieves the state-of-the-art ImageNet performance on the NASNet search space. The code is available at https://github.com/VITA-Group/WeakNAS