 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Structured Knowledge and Data: A Unified Framework with Finance Applications
Apr 01, 2026We develop Structured-Knowledge-Informed Neural Networks (SKINNs), a unified estimation framework that embeds theoretical, simulated, previously learned, or cross-domain insights as differentiable constraints within flexible neural function approximation. SKINNs jointly estimate neural network parameters and economically meaningful structural parameters in a single optimization problem, enforcing theoretical consistency not only on observed data but over a broader input domain through collocation, and therefore nesting approaches such as functional GMM, Bayesian updating, transfer learning, PINNs, and surrogate modeling. SKINNs define a class of M-estimators that are consistent and asymptotically normal with root-N convergence, sandwich covariance, and recovery of pseudo-true parameters under misspecification. We establish identification of structural parameters under joint flexibility, derive generalization and target-risk bounds under distributional shift in a convex proxy, and provide a restricted-optimal characterization of the weighting parameter that governs the bias-variance tradeoff. In an illustrative financial application to option pricing, SKINNs improve out-of-sample valuation and hedging performance, particularly at longer horizons and during high-volatility regimes, while recovering economically interpretable structural parameters with improved stability relative to conventional calibration. More broadly, SKINNs provide a general econometric framework for combining model-based reasoning with high-dimensional, data-driven estimation.
Peer-induced Fairness: A Causal Approach for Algorithmic Fairness Auditing
Aug 16, 2024With the EU AI Act effective from 1 August 2024, high-risk applications like credit scoring must adhere to stringent transparency and quality standards, including algorithmic fairness evaluations. Consequently, developing tools for auditing algorithmic fairness has become crucial. This paper addresses a key question: how can we scientifically audit algorithmic fairness? It is vital to determine whether adverse decisions result from algorithmic discrimination or the subjects' inherent limitations. We introduce a novel auditing framework, ``peer-induced fairness'', leveraging counterfactual fairness and advanced causal inference techniques within credit approval systems. Our approach assesses fairness at the individual level through peer comparisons, independent of specific AI methodologies. It effectively tackles challenges like data scarcity and imbalance, common in traditional models, particularly in credit approval. Model-agnostic and flexible, the framework functions as both a self-audit tool for stakeholders and an external audit tool for regulators, offering ease of integration. It also meets the EU AI Act's transparency requirements by providing clear feedback on whether adverse decisions stem from personal capabilities or discrimination. We demonstrate the framework's usefulness by applying it to SME credit approval, revealing significant bias: 41.51% of micro-firms face discrimination compared to non-micro firms. These findings highlight the framework's potential for diverse AI applications.
Peer-induced Fairness: A Causal Approach to Reveal Algorithmic Unfairness in Credit Approval
Aug 05, 2024This paper introduces a novel framework, "peer-induced fairness", to scientifically audit algorithmic fairness. It addresses a critical but often overlooked issue: distinguishing between adverse outcomes due to algorithmic discrimination and those resulting from individuals' insufficient capabilities. By utilizing counterfactual fairness and advanced causal inference techniques, such as the Single World Intervention Graph, this model-agnostic approach evaluates fairness at the individual level through peer comparisons and hypothesis testing. It also tackles challenges like data scarcity and imbalance, offering a flexible, plug-and-play self-audit tool for stakeholders and an external audit tool for regulators, while providing explainable feedback for those affected by unfavorable decisions.
Interpretable Fairness via Target Labels in Gaussian Process Models
Oct 18, 2018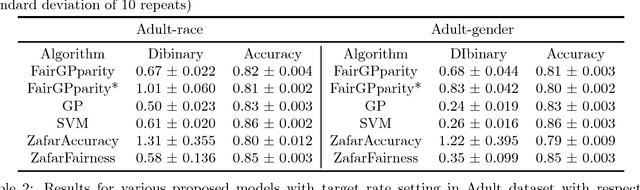
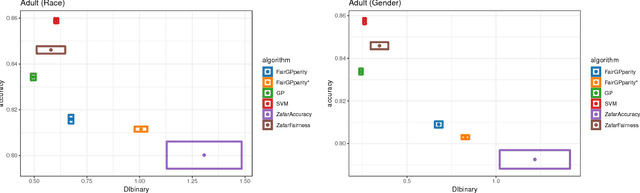
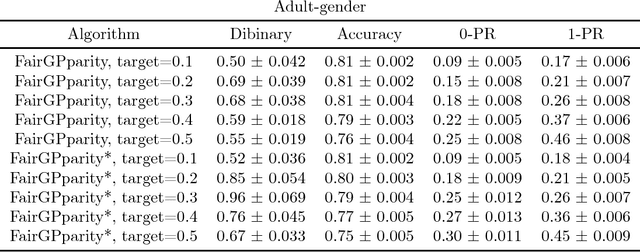
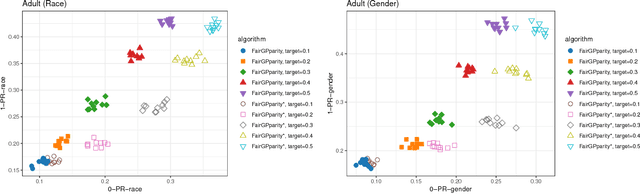
Addressing fairness in machine learning models has recently attracted a lot of attention, as it will ensure continued confidence of the general public in the deployment of machine learning systems. Here, we focus on mitigating harm of a biased system that offers much better quality outputs for certain groups than for others. We show that bias in the output can naturally be handled in Gaussian process classification (GPC) models by introducing a latent target output that will modulate the likelihood function. This simple formulation has several advantages: first, it is a unified framework for several notions of fairness (demographic parity, equalized odds, and equal opportunity); second, it allows encoding our knowledge of what the bias in outputs should be; and third, it can be solved by using off-the-shelf GPC packages.
Multivariate Gaussian and Student$-t$ Process Regression for Multi-output Prediction
Jan 18, 2018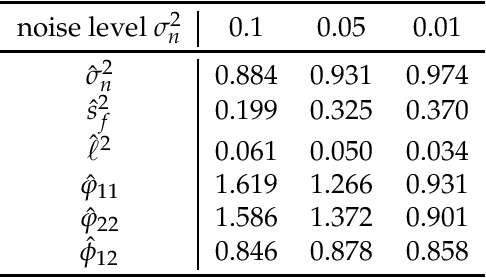
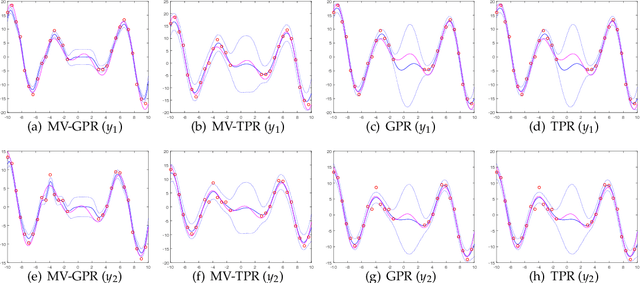
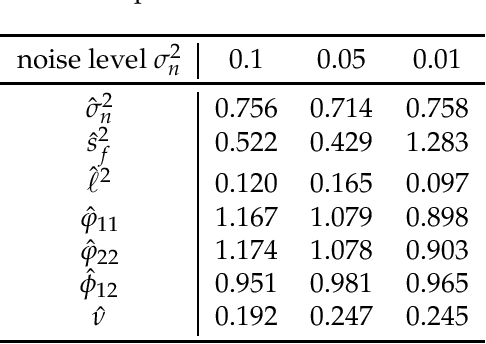
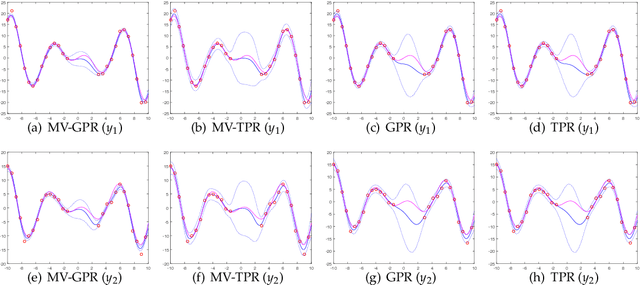
Gaussian process for vector-valued function model has been shown to be a useful method for multi-output prediction. The existing method for this model is to re-formulate the matrix-variate Gaussian distribution as a multivariate normal distribution. Although it is effective in many cases, re-formulation is not always workable and difficult to extend because not all matrix-variate distributions can be transformed to related multivariate distributions, such as the case for matrix-variate Student$-t$ distribution. In this paper, we propose a new derivation of multivariate Gaussian process regression (MV-GPR), where the model settings, derivations and computations are all directly performed in matrix form, rather than vectorizing the matrices as done in the existing methods. Furthermore, we introduce the multivariate Student$-t$ process and then derive a new method, multivariate Student$-t$ process regression (MV-TPR) for multi-output prediction. Both MV-GPR and MV-TPR have closed-form expressions for the marginal likelihoods and predictive distributions. The usefulness of the proposed methods is illustrated through several simulated examples. In particular, we verify empirically that MV-TPR has superiority for the datasets considered, including air quality prediction and bike rent prediction. At last, the proposed methods are shown to produce profitable investment strategies in the stock markets.
How priors of initial hyperparameters affect Gaussian process regression models
Oct 25, 2017

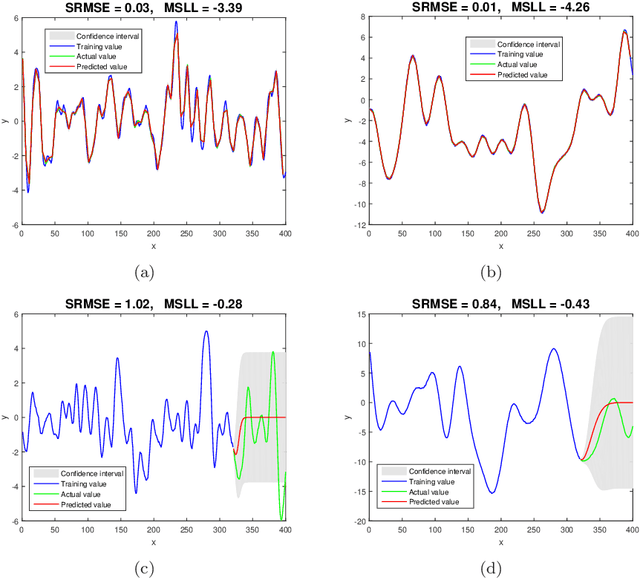
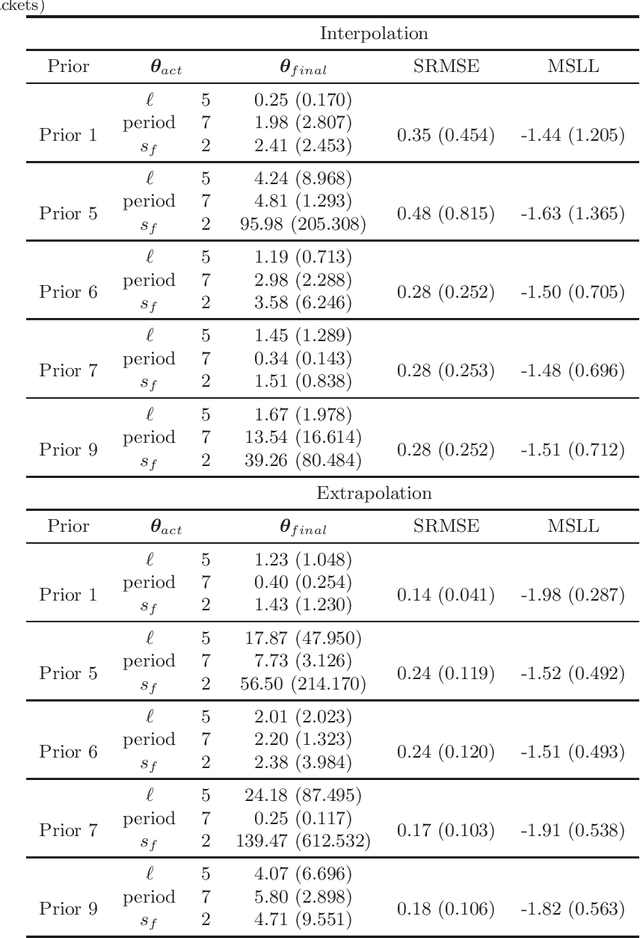
The hyperparameters in Gaussian process regression (GPR) model with a specified kernel are often estimated from the data via the maximum marginal likelihood. Due to the non-convexity of marginal likelihood with respect to the hyperparameters, the optimization may not converge to the global maxima. A common approach to tackle this issue is to use multiple starting points randomly selected from a specific prior distribution. As a result the choice of prior distribution may play a vital role in the predictability of this approach. However, there exists little research in the literature to study the impact of the prior distributions on the hyperparameter estimation and the performance of GPR. In this paper, we provide the first empirical study on this problem using simulated and real data experiments. We consider different types of priors for the initial values of hyperparameters for some commonly used kernels and investigate the influence of the priors on the predictability of GPR models. The results reveal that, once a kernel is chosen, different priors for the initial hyperparameters have no significant impact on the performance of GPR prediction, despite that the estimates of the hyperparameters are very different to the true values in some cases.