 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen majority rules, minority loses: bias amplification of gradient descent
May 19, 2025Despite growing empirical evidence of bias amplification in machine learning, its theoretical foundations remain poorly understood. We develop a formal framework for majority-minority learning tasks, showing how standard training can favor majority groups and produce stereotypical predictors that neglect minority-specific features. Assuming population and variance imbalance, our analysis reveals three key findings: (i) the close proximity between ``full-data'' and stereotypical predictors, (ii) the dominance of a region where training the entire model tends to merely learn the majority traits, and (iii) a lower bound on the additional training required. Our results are illustrated through experiments in deep learning for tabular and image classification tasks.
A second-order-like optimizer with adaptive gradient scaling for deep learning
Oct 08, 2024



In this empirical article, we introduce INNAprop, an optimization algorithm that combines the INNA method with the RMSprop adaptive gradient scaling. It leverages second-order information and rescaling while keeping the memory requirements of standard DL methods as AdamW or SGD with momentum.After having recalled our geometrical motivations, we provide quite extensive experiments. On image classification (CIFAR-10, ImageNet) and language modeling (GPT-2), INNAprop consistently matches or outperforms AdamW both in training speed and accuracy, with minimal hyperparameter tuning in large-scale settings. Our code is publicly available at \url{https://github.com/innaprop/innaprop}.
On the numerical reliability of nonsmooth autodiff: a MaxPool case study
Jan 05, 2024This paper considers the reliability of automatic differentiation (AD) for neural networks involving the nonsmooth MaxPool operation. We investigate the behavior of AD across different precision levels (16, 32, 64 bits) and convolutional architectures (LeNet, VGG, and ResNet) on various datasets (MNIST, CIFAR10, SVHN, and ImageNet). Although AD can be incorrect, recent research has shown that it coincides with the derivative almost everywhere, even in the presence of nonsmooth operations (such as MaxPool and ReLU). On the other hand, in practice, AD operates with floating-point numbers (not real numbers), and there is, therefore, a need to explore subsets on which AD can be numerically incorrect. These subsets include a bifurcation zone (where AD is incorrect over reals) and a compensation zone (where AD is incorrect over floating-point numbers but correct over reals). Using SGD for the training process, we study the impact of different choices of the nonsmooth Jacobian for the MaxPool function on the precision of 16 and 32 bits. These findings suggest that nonsmooth MaxPool Jacobians with lower norms help maintain stable and efficient test accuracy, whereas those with higher norms can result in instability and decreased performance. We also observe that the influence of MaxPool's nonsmooth Jacobians on learning can be reduced by using batch normalization, Adam-like optimizers, or increasing the precision level.
Nonsmooth automatic differentiation: a cheap gradient principle and other complexity results
Jun 01, 2022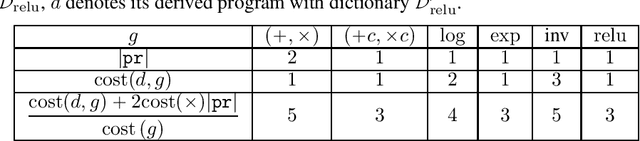
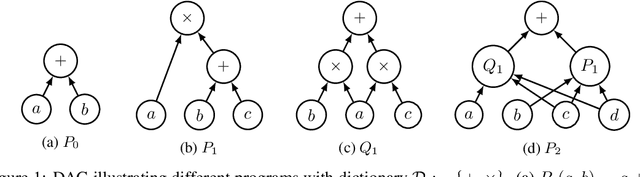
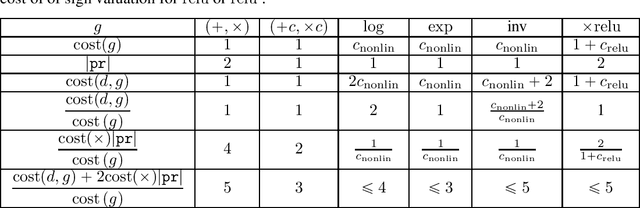
We provide a simple model to estimate the computational costs of the backward and forward modes of algorithmic differentiation for a wide class of nonsmooth programs. Prominent examples are the famous relu and convolutional neural networks together with their standard loss functions. Using the recent notion of conservative gradients, we then establish a "nonsmooth cheap gradient principle" for backpropagation encompassing most concrete applications. Nonsmooth backpropagation's cheapness contrasts with concurrent forward approaches which have, at this day, dimensional-dependent worst case estimates. In order to understand this class of methods, we relate the complexity of computing a large number of directional derivatives to that of matrix multiplication. This shows a fundamental limitation for improving forward AD for that task. Finally, while the fastest algorithms for computing a Clarke subgradient are linear in the dimension, it appears that computing two distinct Clarke (resp. lexicographic) subgradients for simple neural networks is NP-Hard.