 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonsmooth automatic differentiation: a cheap gradient principle and other complexity results
Paper and Code
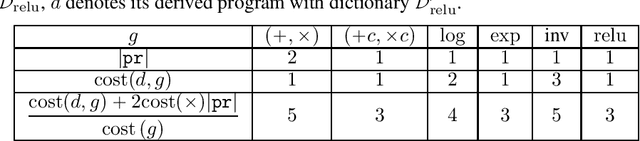
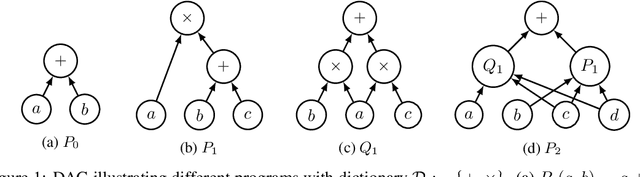
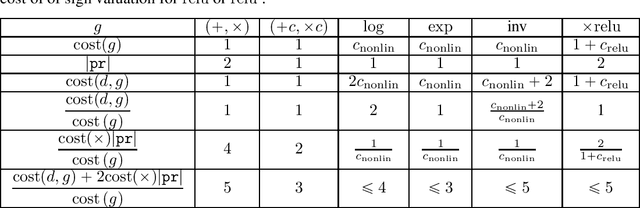
We provide a simple model to estimate the computational costs of the backward and forward modes of algorithmic differentiation for a wide class of nonsmooth programs. Prominent examples are the famous relu and convolutional neural networks together with their standard loss functions. Using the recent notion of conservative gradients, we then establish a "nonsmooth cheap gradient principle" for backpropagation encompassing most concrete applications. Nonsmooth backpropagation's cheapness contrasts with concurrent forward approaches which have, at this day, dimensional-dependent worst case estimates. In order to understand this class of methods, we relate the complexity of computing a large number of directional derivatives to that of matrix multiplication. This shows a fundamental limitation for improving forward AD for that task. Finally, while the fastest algorithms for computing a Clarke subgradient are linear in the dimension, it appears that computing two distinct Clarke (resp. lexicographic) subgradients for simple neural networks is NP-Hard.