 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Approach To Gaussian Process Surrogate Evaluation With Coverage Guarantees
Jan 15, 2024Gaussian processes (GPs) are a Bayesian machine learning approach widely used to construct surrogate models for the uncertainty quantification of computer simulation codes in industrial applications. It provides both a mean predictor and an estimate of the posterior prediction variance, the latter being used to produce Bayesian credibility intervals. Interpreting these intervals relies on the Gaussianity of the simulation model as well as the well-specification of the priors which are not always appropriate. We propose to address this issue with the help of conformal prediction. In the present work, a method for building adaptive cross-conformal prediction intervals is proposed by weighting the non-conformity score with the posterior standard deviation of the GP. The resulting conformal prediction intervals exhibit a level of adaptivity akin to Bayesian credibility sets and display a significant correlation with the surrogate model local approximation error, while being free from the underlying model assumptions and having frequentist coverage guarantees. These estimators can thus be used for evaluating the quality of a GP surrogate model and can assist a decision-maker in the choice of the best prior for the specific application of the GP. The performance of the method is illustrated through a panel of numerical examples based on various reference databases. Moreover, the potential applicability of the method is demonstrated in the context of surrogate modeling of an expensive-to-evaluate simulator of the clogging phenomenon in steam generators of nuclear reactors.
Understanding black-box models with dependent inputs through a generalization of Hoeffding's decomposition
Oct 10, 2023One of the main challenges for interpreting black-box models is the ability to uniquely decompose square-integrable functions of non-mutually independent random inputs into a sum of functions of every possible subset of variables. However, dealing with dependencies among inputs can be complicated. We propose a novel framework to study this problem, linking three domains of mathematics: probability theory, functional analysis, and combinatorics. We show that, under two reasonable assumptions on the inputs (non-perfect functional dependence and non-degenerate stochastic dependence), it is always possible to decompose uniquely such a function. This ``canonical decomposition'' is relatively intuitive and unveils the linear nature of non-linear functions of non-linearly dependent inputs. In this framework, we effectively generalize the well-known Hoeffding decomposition, which can be seen as a particular case. Oblique projections of the black-box model allow for novel interpretability indices for evaluation and variance decomposition. Aside from their intuitive nature, the properties of these novel indices are studied and discussed. This result offers a path towards a more precise uncertainty quantification, which can benefit sensitivity analyses and interpretability studies, whenever the inputs are dependent. This decomposition is illustrated analytically, and the challenges to adopting these results in practice are discussed.
Machine learning with data assimilation and uncertainty quantification for dynamical systems: a review
Mar 18, 2023Data Assimilation (DA) and Uncertainty quantification (UQ) are extensively used in analysing and reducing error propagation in high-dimensional spatial-temporal dynamics. Typical applications span from computational fluid dynamics (CFD) to geoscience and climate systems. Recently, much effort has been given in combining DA, UQ and machine learning (ML) techniques. These research efforts seek to address some critical challenges in high-dimensional dynamical systems, including but not limited to dynamical system identification, reduced order surrogate modelling, error covariance specification and model error correction. A large number of developed techniques and methodologies exhibit a broad applicability across numerous domains, resulting in the necessity for a comprehensive guide. This paper provides the first overview of the state-of-the-art researches in this interdisciplinary field, covering a wide range of applications. This review aims at ML scientists who attempt to apply DA and UQ techniques to improve the accuracy and the interpretability of their models, but also at DA and UQ experts who intend to integrate cutting-edge ML approaches to their systems. Therefore, this article has a special focus on how ML methods can overcome the existing limits of DA and UQ, and vice versa. Some exciting perspectives of this rapidly developing research field are also discussed.
Quantile-constrained Wasserstein projections for robust interpretability of numerical and machine learning models
Sep 23, 2022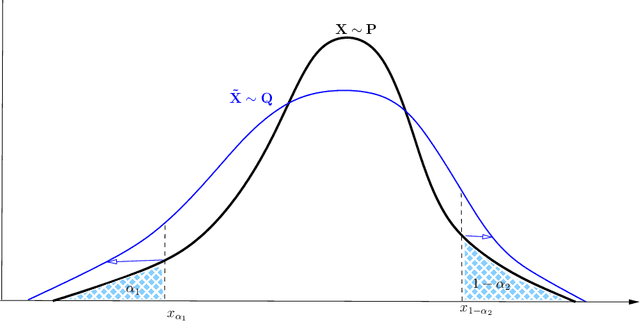

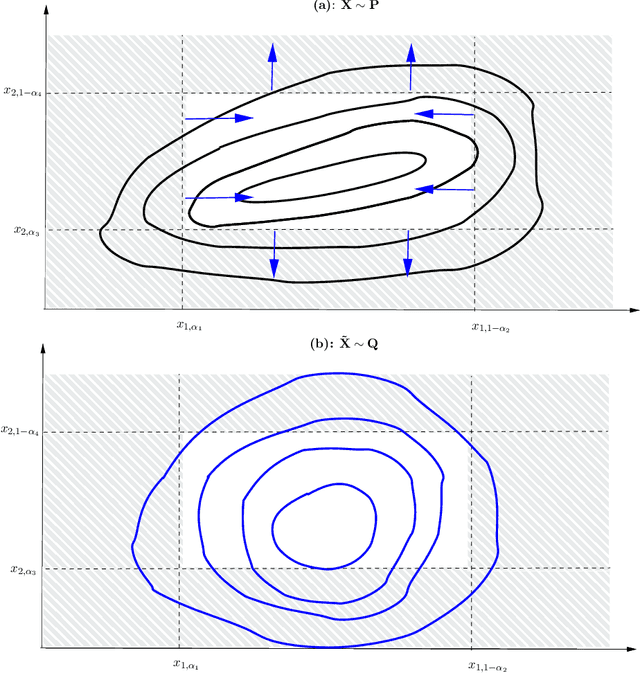
Robustness studies of black-box models is recognized as a necessary task for numerical models based on structural equations and predictive models learned from data. These studies must assess the model's robustness to possible misspecification of regarding its inputs (e.g., covariate shift). The study of black-box models, through the prism of uncertainty quantification (UQ), is often based on sensitivity analysis involving a probabilistic structure imposed on the inputs, while ML models are solely constructed from observed data. Our work aim at unifying the UQ and ML interpretability approaches, by providing relevant and easy-to-use tools for both paradigms. To provide a generic and understandable framework for robustness studies, we define perturbations of input information relying on quantile constraints and projections with respect to the Wasserstein distance between probability measures, while preserving their dependence structure. We show that this perturbation problem can be analytically solved. Ensuring regularity constraints by means of isotonic polynomial approximations leads to smoother perturbations, which can be more suitable in practice. Numerical experiments on real case studies, from the UQ and ML fields, highlight the computational feasibility of such studies and provide local and global insights on the robustness of black-box models to input perturbations.
Sample selection from a given dataset to validate machine learning models
Apr 27, 2021

The selection of a validation basis from a full dataset is often required in industrial use of supervised machine learning algorithm. This validation basis will serve to realize an independent evaluation of the machine learning model. To select this basis, we propose to adopt a "design of experiments" point of view, by using statistical criteria. We show that the "support points" concept, based on Maximum Mean Discrepancy criteria, is particularly relevant. An industrial test case from the company EDF illustrates the practical interest of the methodology.
Poincaré inequalities on intervals -- application to sensitivity analysis
Dec 12, 2016
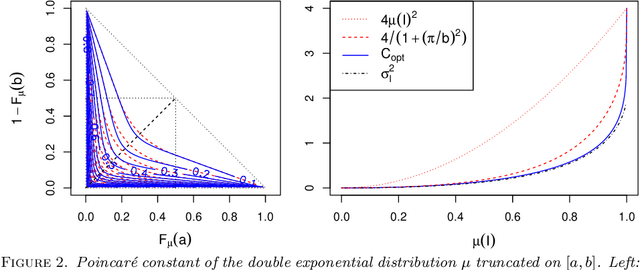
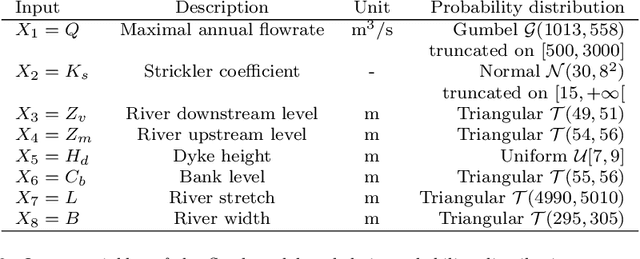
The development of global sensitivity analysis of numerical model outputs has recently raised new issues on 1-dimensional Poincar\'e inequalities. Typically two kind of sensitivity indices are linked by a Poincar\'e type inequality, which provide upper bounds of the most interpretable index by using the other one, cheaper to compute. This allows performing a low-cost screening of unessential variables. The efficiency of this screening then highly depends on the accuracy of the upper bounds in Poincar\'e inequalities. The novelty in the questions concern the wide range of probability distributions involved, which are often truncated on intervals. After providing an overview of the existing knowledge and techniques, we add some theory about Poincar\'e constants on intervals, with improvements for symmetric intervals. Then we exploit the spectral interpretation for computing exact value of Poincar\'e constants of any admissible distribution on a given interval. We give semi-analytical results for some frequent distributions (truncated exponential, triangular, truncated normal), and present a numerical method in the general case. Finally, an application is made to a hydrological problem, showing the benefits of the new results in Poincar\'e inequalities to sensitivity analysis.