 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTile and Slide : A New Framework for Scaling NeRF from Local to Global 3D Earth Observation
Jul 02, 2025Neural Radiance Fields (NeRF) have recently emerged as a paradigm for 3D reconstruction from multiview satellite imagery. However, state-of-the-art NeRF methods are typically constrained to small scenes due to the memory footprint during training, which we study in this paper. Previous work on large-scale NeRFs palliate this by dividing the scene into NeRFs. This paper introduces Snake-NeRF, a framework that scales to large scenes. Our out-of-core method eliminates the need to load all images and networks simultaneously, and operates on a single device. We achieve this by dividing the region of interest into NeRFs that 3D tile without overlap. Importantly, we crop the images with overlap to ensure each NeRFs is trained with all the necessary pixels. We introduce a novel $2\times 2$ 3D tile progression strategy and segmented sampler, which together prevent 3D reconstruction errors along the tile edges. Our experiments conclude that large satellite images can effectively be processed with linear time complexity, on a single GPU, and without compromise in quality.
SAT-NGP : Unleashing Neural Graphics Primitives for Fast Relightable Transient-Free 3D reconstruction from Satellite Imagery
Mar 27, 2024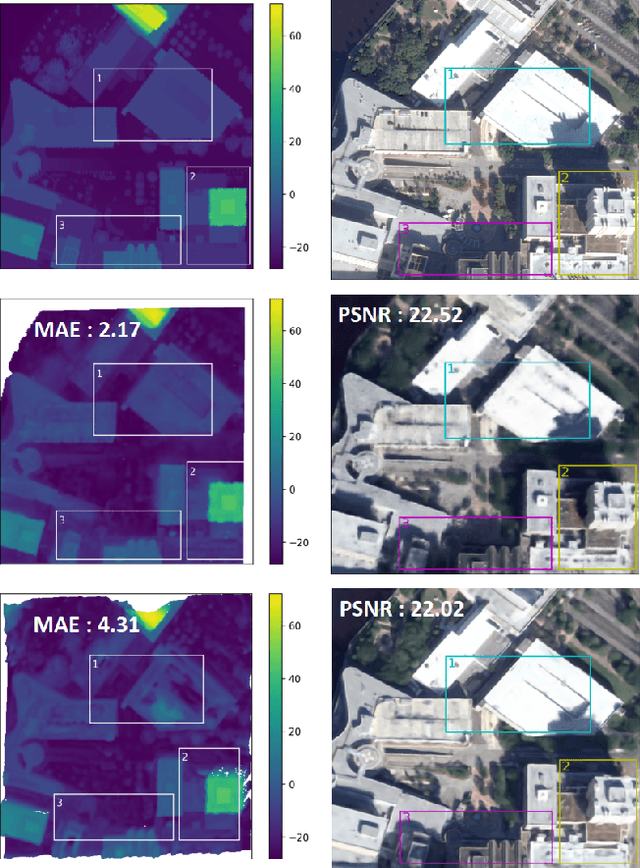
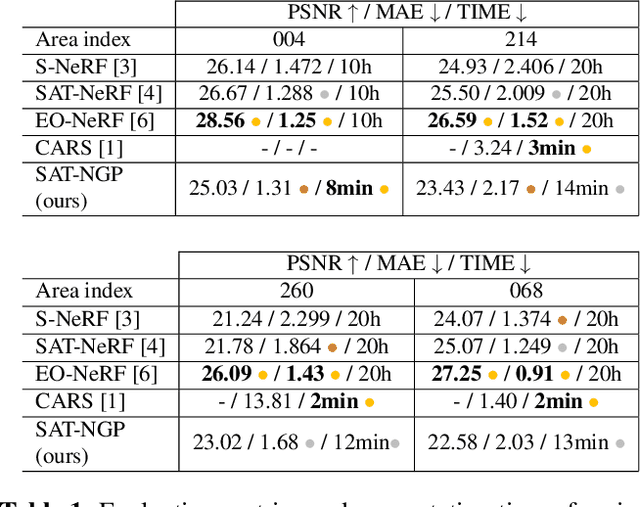

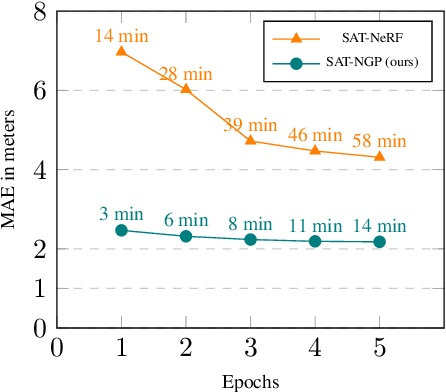
Current stereo-vision pipelines produce high accuracy 3D reconstruction when using multiple pairs or triplets of satellite images. However, these pipelines are sensitive to the changes between images that can occur as a result of multi-date acquisitions. Such variations are mainly due to variable shadows, reflexions and transient objects (cars, vegetation). To take such changes into account, Neural Radiance Fields (NeRF) have recently been applied to multi-date satellite imagery. However, Neural methods are very compute-intensive, taking dozens of hours to learn, compared with minutes for standard stereo-vision pipelines. Following the ideas of Instant Neural Graphics Primitives we propose to use an efficient sampling strategy and multi-resolution hash encoding to accelerate the learning. Our model, Satellite Neural Graphics Primitives (SAT-NGP) decreases the learning time to 15 minutes while maintaining the quality of the 3D reconstruction.
An evaluation of Deep Learning based stereo dense matching dataset shift from aerial images and a large scale stereo dataset
Feb 19, 2024



Dense matching is crucial for 3D scene reconstruction since it enables the recovery of scene 3D geometry from image acquisition. Deep Learning (DL)-based methods have shown effectiveness in the special case of epipolar stereo disparity estimation in the computer vision community. DL-based methods depend heavily on the quality and quantity of training datasets. However, generating ground-truth disparity maps for real scenes remains a challenging task in the photogrammetry community. To address this challenge, we propose a method for generating ground-truth disparity maps directly from Light Detection and Ranging (LiDAR) and images to produce a large and diverse dataset for six aerial datasets across four different areas and two areas with different resolution images. We also introduce a LiDAR-to-image co-registration refinement to the framework that takes special precautions regarding occlusions and refrains from disparity interpolation to avoid precision loss. Evaluating 11 dense matching methods across datasets with diverse scene types, image resolutions, and geometric configurations, which are deeply investigated in dataset shift, GANet performs best with identical training and testing data, and PSMNet shows robustness across different datasets, and we proposed the best strategy for training with a limit dataset. We will also provide the dataset and training models; more information can be found at https://github.com/whuwuteng/Aerial_Stereo_Dataset.
Mobile Mapping Mesh Change Detection and Update
Mar 13, 2023



Mobile mapping, in particular, Mobile Lidar Scanning (MLS) is increasingly widespread to monitor and map urban scenes at city scale with unprecedented resolution and accuracy. The resulting point cloud sampling of the scene geometry can be meshed in order to create a continuous representation for different applications: visualization, simulation, navigation, etc. Because of the highly dynamic nature of these urban scenes, long term mapping should rely on frequent map updates. A trivial solution is to simply replace old data with newer data each time a new acquisition is made. However it has two drawbacks: 1) the old data may be of higher quality (resolution, precision) than the new and 2) the coverage of the scene might be different in various acquisitions, including varying occlusions. In this paper, we propose a fully automatic pipeline to address these two issues by formulating the problem of merging meshes with different quality, coverage and acquisition time. Our method is based on a combined distance and visibility based change detection, a time series analysis to assess the sustainability of changes, a mesh mosaicking based on a global boolean optimization and finally a stitching of the resulting mesh pieces boundaries with triangle strips. Finally, our method is demonstrated on Robotcar and Stereopolis datasets.
Semantic Segmentation of Urban Textured Meshes Through Point Sampling
Feb 21, 2023Textured meshes are becoming an increasingly popular representation combining the 3D geometry and radiometry of real scenes. However, semantic segmentation algorithms for urban mesh have been little investigated and do not exploit all radiometric information. To address this problem, we adopt an approach consisting in sampling a point cloud from the textured mesh, then using a point cloud semantic segmentation algorithm on this cloud, and finally using the obtained semantic to segment the initial mesh. In this paper, we study the influence of different parameters such as the sampling method, the density of the extracted cloud, the features selected (color, normal, elevation) as well as the number of points used at each training period. Our result outperforms the state-of-the-art on the SUM dataset, earning about 4 points in OA and 18 points in mIoU.
* 9 pages, 6 figures, conference, presented at XXIV ISPRS Congress
A Survey and Benchmark of Automatic Surface Reconstruction from Point Clouds
Jan 31, 2023We survey and benchmark traditional and novel learning-based algorithms that address the problem of surface reconstruction from point clouds. Surface reconstruction from point clouds is particularly challenging when applied to real-world acquisitions, due to noise, outliers, non-uniform sampling and missing data. Traditionally, different handcrafted priors of the input points or the output surface have been proposed to make the problem more tractable. However, hyperparameter tuning for adjusting priors to different acquisition defects can be a tedious task. To this end, the deep learning community has recently addressed the surface reconstruction problem. In contrast to traditional approaches, deep surface reconstruction methods can learn priors directly from a training set of point clouds and corresponding true surfaces. In our survey, we detail how different handcrafted and learned priors affect the robustness of methods to defect-laden input and their capability to generate geometric and topologically accurate reconstructions. In our benchmark, we evaluate the reconstructions of several traditional and learning-based methods on the same grounds. We show that learning-based methods can generalize to unseen shape categories, but their training and test sets must share the same point cloud characteristics. We also provide the code and data to compete in our benchmark and to further stimulate the development of learning-based surface reconstruction https://github.com/raphaelsulzer/dsr-benchmark.
Learning Multi-View Aggregation In the Wild for Large-Scale 3D Semantic Segmentation
Apr 15, 2022

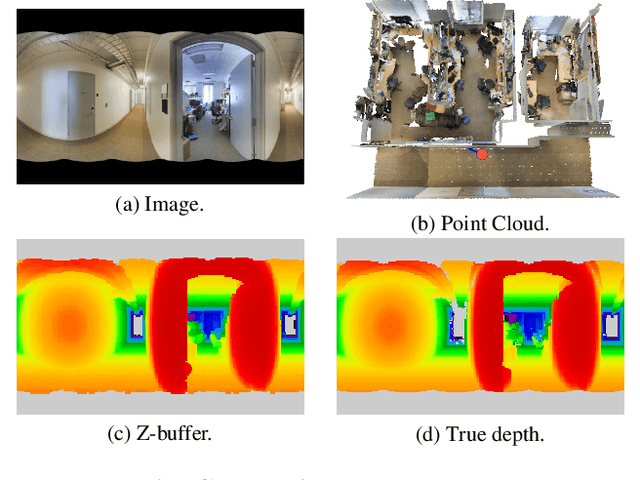

Recent works on 3D semantic segmentation propose to exploit the synergy between images and point clouds by processing each modality with a dedicated network and projecting learned 2D features onto 3D points. Merging large-scale point clouds and images raises several challenges, such as constructing a mapping between points and pixels, and aggregating features between multiple views. Current methods require mesh reconstruction or specialized sensors to recover occlusions, and use heuristics to select and aggregate available images. In contrast, we propose an end-to-end trainable multi-view aggregation model leveraging the viewing conditions of 3D points to merge features from images taken at arbitrary positions. Our method can combine standard 2D and 3D networks and outperforms both 3D models operating on colorized point clouds and hybrid 2D/3D networks without requiring colorization, meshing, or true depth maps. We set a new state-of-the-art for large-scale indoor/outdoor semantic segmentation on S3DIS (74.7 mIoU 6-Fold) and on KITTI-360 (58.3 mIoU). Our full pipeline is accessible at https://github.com/drprojects/DeepViewAgg, and only requires raw 3D scans and a set of images and poses.
Deep Surface Reconstruction from Point Clouds with Visibility Information
Feb 03, 2022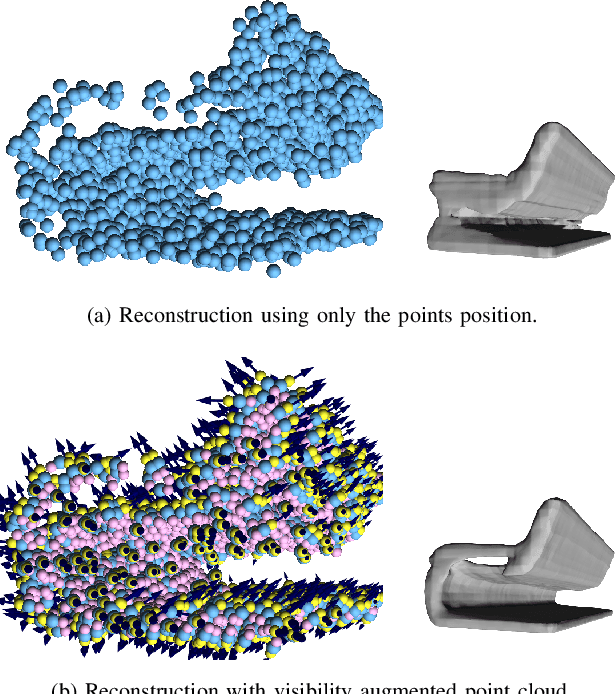


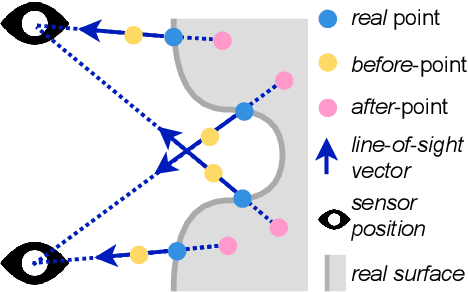
Most current neural networks for reconstructing surfaces from point clouds ignore sensor poses and only operate on raw point locations. Sensor visibility, however, holds meaningful information regarding space occupancy and surface orientation. In this paper, we present two simple ways to augment raw point clouds with visibility information, so it can directly be leveraged by surface reconstruction networks with minimal adaptation. Our proposed modifications consistently improve the accuracy of generated surfaces as well as the generalization ability of the networks to unseen shape domains. Our code and data is available at https://github.com/raphaelsulzer/dsrv-data.
Scalable Surface Reconstruction with Delaunay-Graph Neural Networks
Jul 15, 2021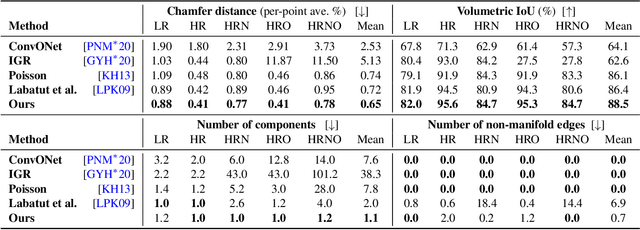
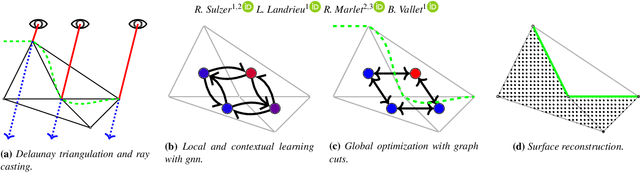

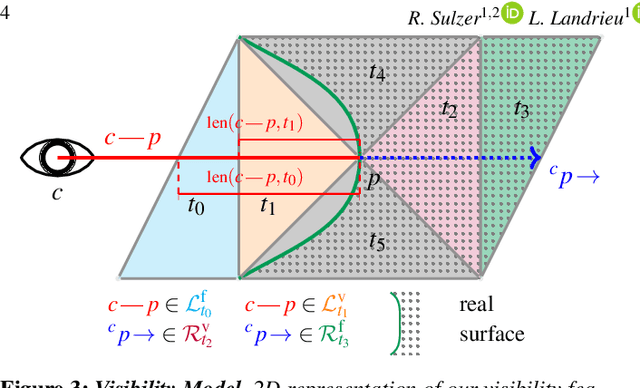
We introduce a novel learning-based, visibility-aware, surface reconstruction method for large-scale, defect-laden point clouds. Our approach can cope with the scale and variety of point cloud defects encountered in real-life Multi-View Stereo (MVS) acquisitions. Our method relies on a 3D Delaunay tetrahedralization whose cells are classified as inside or outside the surface by a graph neural network and an energy model solvable with a graph cut. Our model, making use of both local geometric attributes and line-of-sight visibility information, is able to learn a visibility model from a small amount of synthetic training data and generalizes to real-life acquisitions. Combining the efficiency of deep learning methods and the scalability of energy based models, our approach outperforms both learning and non learning-based reconstruction algorithms on two publicly available reconstruction benchmarks.
* The presentation of this work at SGP 2021 is available at https://youtu.be/KIrCDGhS10o
A Synergistic Approach for Recovering Occlusion-Free Textured 3D Maps of Urban Facades from Heterogeneous Cartographic Data
Aug 29, 2013
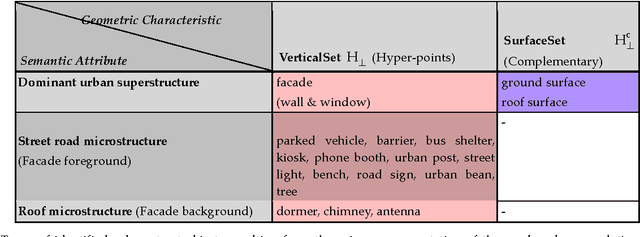
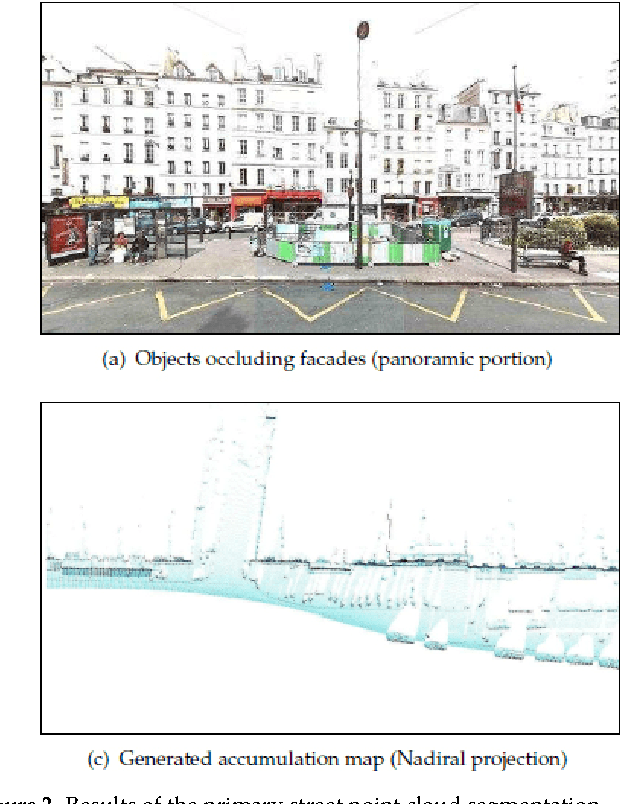
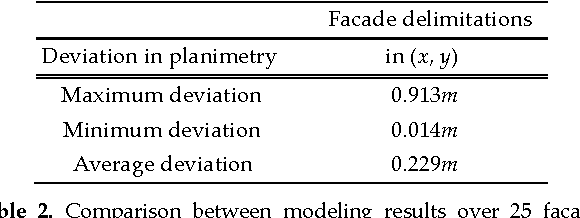
In this paper we present a practical approach for generating an occlusion-free textured 3D map of urban facades by the synergistic use of terrestrial images, 3D point clouds and area-based information. Particularly in dense urban environments, the high presence of urban objects in front of the facades causes significant difficulties for several stages in computational building modeling. Major challenges lie on the one hand in extracting complete 3D facade quadrilateral delimitations and on the other hand in generating occlusion-free facade textures. For these reasons, we describe a straightforward approach for completing and recovering facade geometry and textures by exploiting the data complementarity of terrestrial multi-source imagery and area-based information.