 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSIM: A Copula-based similarity index sensitive to local changes for Image quality assessment
Oct 02, 2024


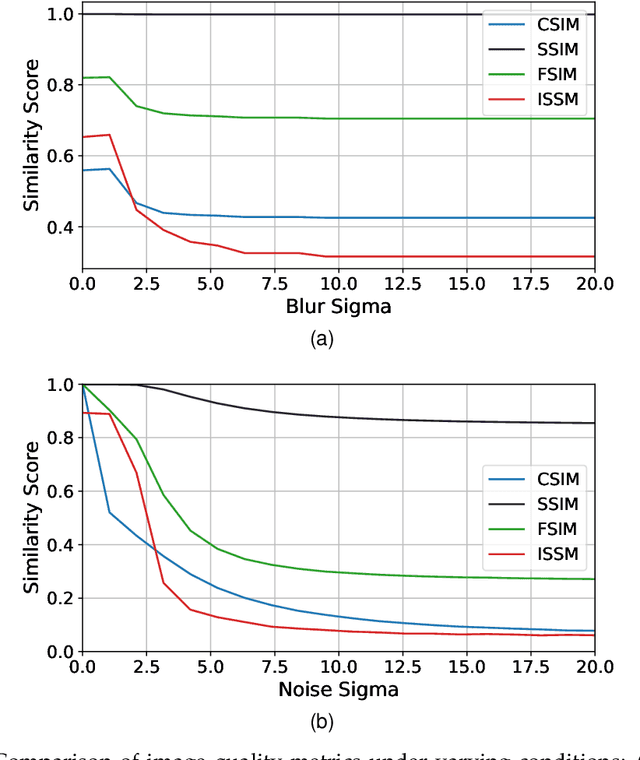
Image similarity metrics play an important role in computer vision applications, as they are used in image processing, computer vision and machine learning. Furthermore, those metrics enable tasks such as image retrieval, object recognition and quality assessment, essential in fields like healthcare, astronomy and surveillance. Existing metrics, such as PSNR, MSE, SSIM, ISSM and FSIM, often face limitations in terms of either speed, complexity or sensitivity to small changes in images. To address these challenges, a novel image similarity metric, namely CSIM, that combines real-time while being sensitive to subtle image variations is investigated in this paper. The novel metric uses Gaussian Copula from probability theory to transform an image into vectors of pixel distribution associated to local image patches. These vectors contain, in addition to intensities and pixel positions, information on the dependencies between pixel values, capturing the structural relationships within the image. By leveraging the properties of Copulas, CSIM effectively models the joint distribution of pixel intensities, enabling a more nuanced comparison of image patches making it more sensitive to local changes compared to other metrics. Experimental results demonstrate that CSIM outperforms existing similarity metrics in various image distortion scenarios, including noise, compression artifacts and blur. The metric's ability to detect subtle differences makes it suitable for applications requiring high precision, such as medical imaging, where the detection of minor anomalies can be of a high importance. The results obtained in this work can be reproduced from this Github repository: https://github.com/safouaneelg/copulasimilarity.
Shuffle Vision Transformer: Lightweight, Fast and Efficient Recognition of Driver Facial Expression
Sep 05, 2024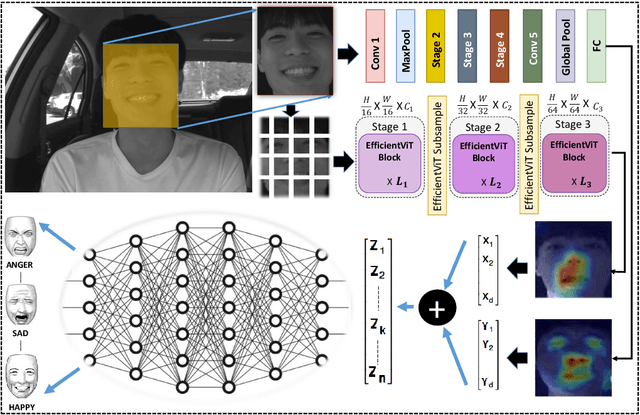

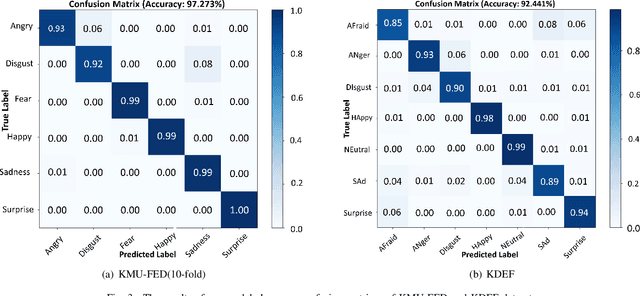

Existing methods for driver facial expression recognition (DFER) are often computationally intensive, rendering them unsuitable for real-time applications. In this work, we introduce a novel transfer learning-based dual architecture, named ShuffViT-DFER, which elegantly combines computational efficiency and accuracy. This is achieved by harnessing the strengths of two lightweight and efficient models using convolutional neural network (CNN) and vision transformers (ViT). We efficiently fuse the extracted features to enhance the performance of the model in accurately recognizing the facial expressions of the driver. Our experimental results on two benchmarking and public datasets, KMU-FED and KDEF, highlight the validity of our proposed method for real-time application with superior performance when compared to state-of-the-art methods.