 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuffle Vision Transformer: Lightweight, Fast and Efficient Recognition of Driver Facial Expression
Sep 05, 2024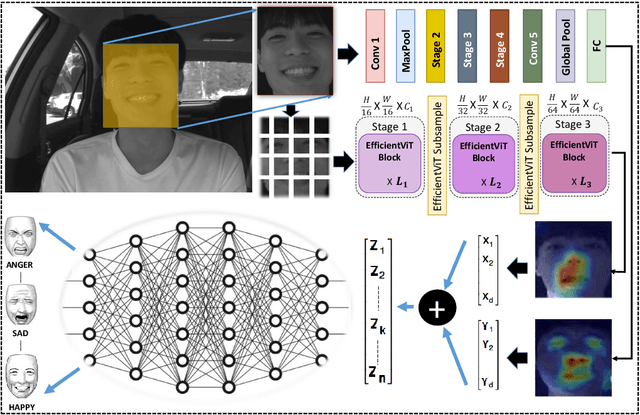

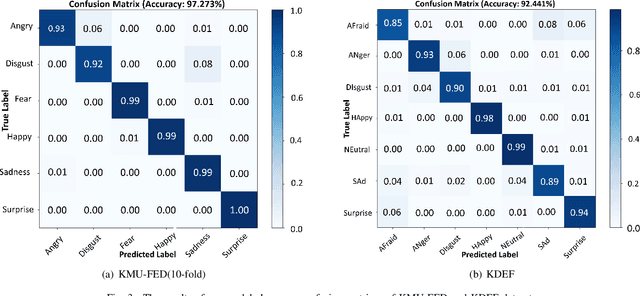

Existing methods for driver facial expression recognition (DFER) are often computationally intensive, rendering them unsuitable for real-time applications. In this work, we introduce a novel transfer learning-based dual architecture, named ShuffViT-DFER, which elegantly combines computational efficiency and accuracy. This is achieved by harnessing the strengths of two lightweight and efficient models using convolutional neural network (CNN) and vision transformers (ViT). We efficiently fuse the extracted features to enhance the performance of the model in accurately recognizing the facial expressions of the driver. Our experimental results on two benchmarking and public datasets, KMU-FED and KDEF, highlight the validity of our proposed method for real-time application with superior performance when compared to state-of-the-art methods.