 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSIM: A Copula-based similarity index sensitive to local changes for Image quality assessment
Oct 02, 2024


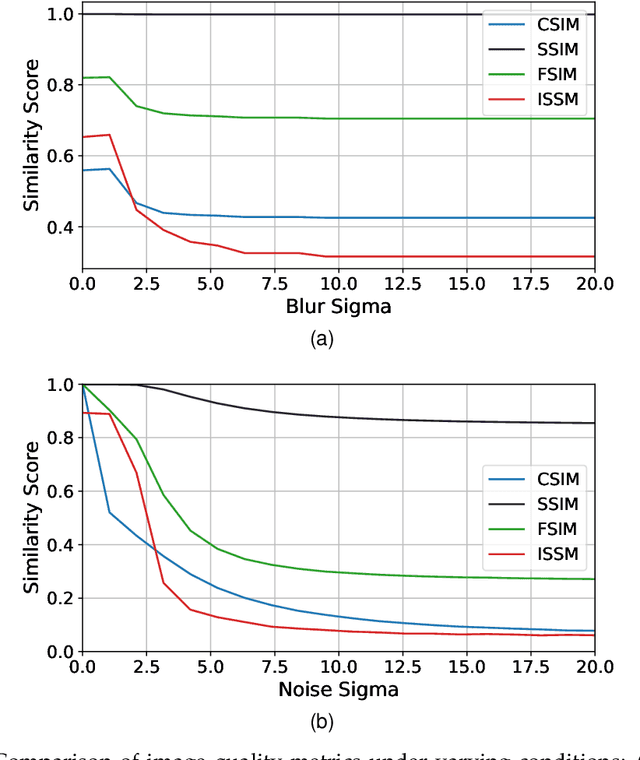
Image similarity metrics play an important role in computer vision applications, as they are used in image processing, computer vision and machine learning. Furthermore, those metrics enable tasks such as image retrieval, object recognition and quality assessment, essential in fields like healthcare, astronomy and surveillance. Existing metrics, such as PSNR, MSE, SSIM, ISSM and FSIM, often face limitations in terms of either speed, complexity or sensitivity to small changes in images. To address these challenges, a novel image similarity metric, namely CSIM, that combines real-time while being sensitive to subtle image variations is investigated in this paper. The novel metric uses Gaussian Copula from probability theory to transform an image into vectors of pixel distribution associated to local image patches. These vectors contain, in addition to intensities and pixel positions, information on the dependencies between pixel values, capturing the structural relationships within the image. By leveraging the properties of Copulas, CSIM effectively models the joint distribution of pixel intensities, enabling a more nuanced comparison of image patches making it more sensitive to local changes compared to other metrics. Experimental results demonstrate that CSIM outperforms existing similarity metrics in various image distortion scenarios, including noise, compression artifacts and blur. The metric's ability to detect subtle differences makes it suitable for applications requiring high precision, such as medical imaging, where the detection of minor anomalies can be of a high importance. The results obtained in this work can be reproduced from this Github repository: https://github.com/safouaneelg/copulasimilarity.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024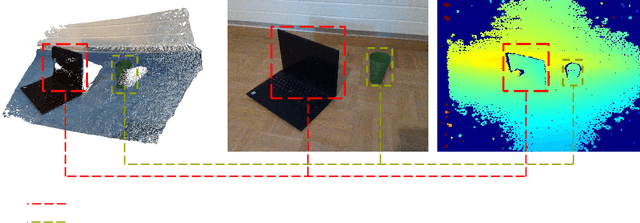



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.