 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBarlow-Swin: Toward a novel siamese-based segmentation architecture using Swin-Transformers
Sep 08, 2025Medical image segmentation is a critical task in clinical workflows, particularly for the detection and delineation of pathological regions. While convolutional architectures like U-Net have become standard for such tasks, their limited receptive field restricts global context modeling. Recent efforts integrating transformers have addressed this, but often result in deep, computationally expensive models unsuitable for real-time use. In this work, we present a novel end-to-end lightweight architecture designed specifically for real-time binary medical image segmentation. Our model combines a Swin Transformer-like encoder with a U-Net-like decoder, connected via skip pathways to preserve spatial detail while capturing contextual information. Unlike existing designs such as Swin Transformer or U-Net, our architecture is significantly shallower and competitively efficient. To improve the encoder's ability to learn meaningful features without relying on large amounts of labeled data, we first train it using Barlow Twins, a self-supervised learning method that helps the model focus on important patterns by reducing unnecessary repetition in the learned features. After this pretraining, we fine-tune the entire model for our specific task. Experiments on benchmark binary segmentation tasks demonstrate that our model achieves competitive accuracy with substantially reduced parameter count and faster inference, positioning it as a practical alternative for deployment in real-time and resource-limited clinical environments. The code for our method is available at Github repository: https://github.com/mkianih/Barlow-Swin.
VisioFirm: Cross-Platform AI-assisted Annotation Tool for Computer Vision
Sep 04, 2025AI models rely on annotated data to learn pattern and perform prediction. Annotation is usually a labor-intensive step that require associating labels ranging from a simple classification label to more complex tasks such as object detection, oriented bounding box estimation, and instance segmentation. Traditional tools often require extensive manual input, limiting scalability for large datasets. To address this, we introduce VisioFirm, an open-source web application designed to streamline image labeling through AI-assisted automation. VisioFirm integrates state-of-the-art foundation models into an interface with a filtering pipeline to reduce human-in-the-loop efforts. This hybrid approach employs CLIP combined with pre-trained detectors like Ultralytics models for common classes and zero-shot models such as Grounding DINO for custom labels, generating initial annotations with low-confidence thresholding to maximize recall. Through this framework, when tested on COCO-type of classes, initial prediction have been proven to be mostly correct though the users can refine these via interactive tools supporting bounding boxes, oriented bounding boxes, and polygons. Additionally, VisioFirm has on-the-fly segmentation powered by Segment Anything accelerated through WebGPU for browser-side efficiency. The tool supports multiple export formats (YOLO, COCO, Pascal VOC, CSV) and operates offline after model caching, enhancing accessibility. VisioFirm demonstrates up to 90\% reduction in manual effort through benchmarks on diverse datasets, while maintaining high annotation accuracy via clustering of connected CLIP-based disambiguate components and IoU-graph for redundant detection suppression. VisioFirm can be accessed from \href{https://github.com/OschAI/VisioFirm}{https://github.com/OschAI/VisioFirm}.
CSIM: A Copula-based similarity index sensitive to local changes for Image quality assessment
Oct 02, 2024


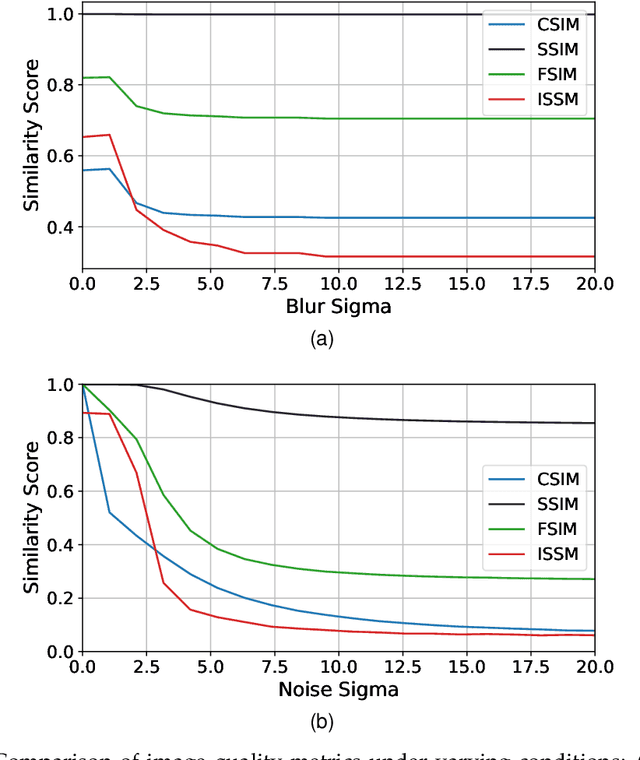
Image similarity metrics play an important role in computer vision applications, as they are used in image processing, computer vision and machine learning. Furthermore, those metrics enable tasks such as image retrieval, object recognition and quality assessment, essential in fields like healthcare, astronomy and surveillance. Existing metrics, such as PSNR, MSE, SSIM, ISSM and FSIM, often face limitations in terms of either speed, complexity or sensitivity to small changes in images. To address these challenges, a novel image similarity metric, namely CSIM, that combines real-time while being sensitive to subtle image variations is investigated in this paper. The novel metric uses Gaussian Copula from probability theory to transform an image into vectors of pixel distribution associated to local image patches. These vectors contain, in addition to intensities and pixel positions, information on the dependencies between pixel values, capturing the structural relationships within the image. By leveraging the properties of Copulas, CSIM effectively models the joint distribution of pixel intensities, enabling a more nuanced comparison of image patches making it more sensitive to local changes compared to other metrics. Experimental results demonstrate that CSIM outperforms existing similarity metrics in various image distortion scenarios, including noise, compression artifacts and blur. The metric's ability to detect subtle differences makes it suitable for applications requiring high precision, such as medical imaging, where the detection of minor anomalies can be of a high importance. The results obtained in this work can be reproduced from this Github repository: https://github.com/safouaneelg/copulasimilarity.
Class-Conditional self-reward mechanism for improved Text-to-Image models
May 22, 2024



Self-rewarding have emerged recently as a powerful tool in the field of Natural Language Processing (NLP), allowing language models to generate high-quality relevant responses by providing their own rewards during training. This innovative technique addresses the limitations of other methods that rely on human preferences. In this paper, we build upon the concept of self-rewarding models and introduce its vision equivalent for Text-to-Image generative AI models. This approach works by fine-tuning diffusion model on a self-generated self-judged dataset, making the fine-tuning more automated and with better data quality. The proposed mechanism makes use of other pre-trained models such as vocabulary based-object detection, image captioning and is conditioned by the a set of object for which the user might need to improve generated data quality. The approach has been implemented, fine-tuned and evaluated on stable diffusion and has led to a performance that has been evaluated to be at least 60\% better than existing commercial and research Text-to-image models. Additionally, the built self-rewarding mechanism allowed a fully automated generation of images, while increasing the visual quality of the generated images and also more efficient following of prompt instructions. The code used in this work is freely available on https://github.com/safouaneelg/SRT2I.
FlightScope: A Deep Comprehensive Assessment of Aircraft Detection Algorithms in Satellite Imagery
Apr 03, 2024Object detection in remotely sensed satellite pictures is fundamental in many fields such as biophysical, and environmental monitoring. While deep learning algorithms are constantly evolving, they have been mostly implemented and tested on popular ground-based taken photos. This paper critically evaluates and compares a suite of advanced object detection algorithms customized for the task of identifying aircraft within satellite imagery. Using the large HRPlanesV2 dataset, together with a rigorous validation with the GDIT dataset, this research encompasses an array of methodologies including YOLO versions 5 and 8, Faster RCNN, CenterNet, RetinaNet, RTMDet, and DETR, all trained from scratch. This exhaustive training and validation study reveal YOLOv5 as the preeminent model for the specific case of identifying airplanes from remote sensing data, showcasing high precision and adaptability across diverse imaging conditions. This research highlight the nuanced performance landscapes of these algorithms, with YOLOv5 emerging as a robust solution for aerial object detection, underlining its importance through superior mean average precision, Recall, and Intersection over Union scores. The findings described here underscore the fundamental role of algorithm selection aligned with the specific demands of satellite imagery analysis and extend a comprehensive framework to evaluate model efficacy. The benchmark toolkit and codes, available via https://github.com/toelt-llc/FlightScope_Bench, aims to further exploration and innovation in the realm of remote sensing object detection, paving the way for improved analytical methodologies in satellite imagery applications.
FusionVision: A comprehensive approach of 3D object reconstruction and segmentation from RGB-D cameras using YOLO and fast segment anything
Feb 29, 2024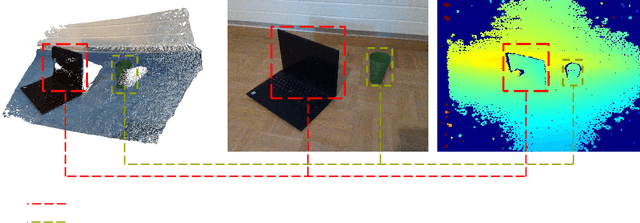



In the realm of computer vision, the integration of advanced techniques into the processing of RGB-D camera inputs poses a significant challenge, given the inherent complexities arising from diverse environmental conditions and varying object appearances. Therefore, this paper introduces FusionVision, an exhaustive pipeline adapted for the robust 3D segmentation of objects in RGB-D imagery. Traditional computer vision systems face limitations in simultaneously capturing precise object boundaries and achieving high-precision object detection on depth map as they are mainly proposed for RGB cameras. To address this challenge, FusionVision adopts an integrated approach by merging state-of-the-art object detection techniques, with advanced instance segmentation methods. The integration of these components enables a holistic (unified analysis of information obtained from both color \textit{RGB} and depth \textit{D} channels) interpretation of RGB-D data, facilitating the extraction of comprehensive and accurate object information. The proposed FusionVision pipeline employs YOLO for identifying objects within the RGB image domain. Subsequently, FastSAM, an innovative semantic segmentation model, is applied to delineate object boundaries, yielding refined segmentation masks. The synergy between these components and their integration into 3D scene understanding ensures a cohesive fusion of object detection and segmentation, enhancing overall precision in 3D object segmentation. The code and pre-trained models are publicly available at https://github.com/safouaneelg/FusionVision/.
Symbrain: A large-scale dataset of MRI images for neonatal brain symmetry analysis
Jan 22, 2024This paper presents an annotated dataset of brain MRI images designed to advance the field of brain symmetry study. Magnetic resonance imaging (MRI) has gained interest in analyzing brain symmetry in neonatal infants, and challenges remain due to the vast size differences between fetal and adult brains. Classification methods for brain structural MRI use scales and visual cues to assess hemisphere symmetry, which can help diagnose neonatal patients by comparing hemispheres and anatomical regions of interest in the brain. Using the Developing Human Connectome Project dataset, this work presents a dataset comprising cerebral images extracted as slices across selected portions of interest for clinical evaluation . All the extracted images are annotated with the brain's midline. All the extracted images are annotated with the brain's midline. From the assumption that a decrease in symmetry is directly related to possible clinical pathologies, the dataset can contribute to a more precise diagnosis because it can be used to train deep learning model application in neonatal cerebral MRI anomaly detection from postnatal infant scans thanks to computer vision. Such models learn to identify and classify anomalies by identifying potential asymmetrical patterns in medical MRI images. Furthermore, this dataset can contribute to the research and development of methods using the relative symmetry of the two brain hemispheres for crucial diagnosis and treatment planning.