 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Statistical Framework for Extreme Error Probability in High-Stakes Domains for Reliable Machine Learning
Mar 31, 2025Machine learning is vital in high-stakes domains, yet conventional validation methods rely on averaging metrics like mean squared error (MSE) or mean absolute error (MAE), which fail to quantify extreme errors. Worst-case prediction failures can have substantial consequences, but current frameworks lack statistical foundations for assessing their probability. In this work a new statistical framework, based on Extreme Value Theory (EVT), is presented that provides a rigorous approach to estimating worst-case failures. Applying EVT to synthetic and real-world datasets, this method is shown to enable robust estimation of catastrophic failure probabilities, overcoming the fundamental limitations of standard cross-validation. This work establishes EVT as a fundamental tool for assessing model reliability, ensuring safer AI deployment in new technologies where uncertainty quantification is central to decision-making or scientific analysis.
Deep Learning Domain Adaptation to Understand Physico-Chemical Processes from Fluorescence Spectroscopy Small Datasets: Application to Ageing of Olive Oil
Jun 22, 2024



Fluorescence spectroscopy is a fundamental tool in life sciences and chemistry, widely used for applications such as environmental monitoring, food quality control, and biomedical diagnostics. However, analysis of spectroscopic data with deep learning, in particular of fluorescence excitation-emission matrices (EEMs), presents significant challenges due to the typically small and sparse datasets available. Furthermore, the analysis of EEMs is difficult due to their high dimensionality and overlapping spectral features. This study proposes a new approach that exploits domain adaptation with pretrained vision models, alongside a novel interpretability algorithm to address these challenges. Thanks to specialised feature engineering of the neural networks described in this work, we are now able to provide deeper insights into the physico-chemical processes underlying the data. The proposed approach is demonstrated through the analysis of the oxidation process in extra virgin olive oil (EVOO) during ageing, showing its effectiveness in predicting quality indicators and identifying the spectral bands, and thus the molecules involved in the process. This work describes a significantly innovative approach in the use of deep learning for spectroscopy, transforming it from a black box into a tool for understanding complex biological and chemical processes.
Intepretative Deep Learning using Domain Adaptation for Fluorescence Spectroscopy
Jun 14, 2024Fluorescence spectroscopy is a fundamental tool in life sciences and chemistry, widely used for applications such as environmental monitoring, food quality control, and biomedical diagnostics. However, analysis of spectroscopic data with deep learning, in particular of fluorescence excitation-emission matrices (EEMs), presents significant challenges due mainly to the typically small and sparse datasets available. Furthermore, the analysis of EEMs is difficult due to their high dimensionality and overlapping spectral features. This study proposes a new approach that exploits domain adaptation with pretrained vision models, alongside a novel interpretability algorithm to address these challenges. Thanks to specialised feature engineering of the neural networks described in this work, we are now able to provide deeper and meaningful insights into the physico-chemical processes underlying the data. The proposed approach is demonstrated through the analysis of the oxidation process in extra virgin olive oil (EVOO), showing its effectiveness in predicting quality indicators and identifying relevant spectral bands. This work describes significantly innovative results in the use of deep learning for spectroscopy, transforming it from a black box into a tool for understanding complex biological and chemical processes.
Symbrain: A large-scale dataset of MRI images for neonatal brain symmetry analysis
Jan 22, 2024This paper presents an annotated dataset of brain MRI images designed to advance the field of brain symmetry study. Magnetic resonance imaging (MRI) has gained interest in analyzing brain symmetry in neonatal infants, and challenges remain due to the vast size differences between fetal and adult brains. Classification methods for brain structural MRI use scales and visual cues to assess hemisphere symmetry, which can help diagnose neonatal patients by comparing hemispheres and anatomical regions of interest in the brain. Using the Developing Human Connectome Project dataset, this work presents a dataset comprising cerebral images extracted as slices across selected portions of interest for clinical evaluation . All the extracted images are annotated with the brain's midline. All the extracted images are annotated with the brain's midline. From the assumption that a decrease in symmetry is directly related to possible clinical pathologies, the dataset can contribute to a more precise diagnosis because it can be used to train deep learning model application in neonatal cerebral MRI anomaly detection from postnatal infant scans thanks to computer vision. Such models learn to identify and classify anomalies by identifying potential asymmetrical patterns in medical MRI images. Furthermore, this dataset can contribute to the research and development of methods using the relative symmetry of the two brain hemispheres for crucial diagnosis and treatment planning.
Shedding Light on the Ageing of Extra Virgin Olive Oil: Probing the Impact of Temperature with Fluorescence Spectroscopy and Machine Learning Techniques
Sep 21, 2023



This work systematically investigates the oxidation of extra virgin olive oil (EVOO) under accelerated storage conditions with UV absorption and total fluorescence spectroscopy. With the large amount of data collected, it proposes a method to monitor the oil's quality based on machine learning applied to highly-aggregated data. EVOO is a high-quality vegetable oil that has earned worldwide reputation for its numerous health benefits and excellent taste. Despite its outstanding quality, EVOO degrades over time owing to oxidation, which can affect both its health qualities and flavour. Therefore, it is highly relevant to quantify the effects of oxidation on EVOO and develop methods to assess it that can be easily implemented under field conditions, rather than in specialized laboratories. The following study demonstrates that fluorescence spectroscopy has the capability to monitor the effect of oxidation and assess the quality of EVOO, even when the data are highly aggregated. It shows that complex laboratory equipment is not necessary to exploit fluorescence spectroscopy using the proposed method and that cost-effective solutions, which can be used in-field by non-scientists, could provide an easily-accessible assessment of the quality of EVOO.
Dataset of Fluorescence Spectra and Chemical Parameters of Olive Oils
Jan 10, 2023



This dataset encompasses fluorescence spectra and chemical parameters of 24 olive oil samples from the 2019-2020 harvest provided by the producer Conde de Benalua, Granada, Spain. The oils are characterized by different qualities: 10 extra virgin olive oil (EVOO), 8 virgin olive oil (VOO), and 6 lampante olive oil (LOO) samples. For each sample, the dataset includes fluorescence spectra obtained with two excitation wavelengths, oil quality, and five chemical parameters necessary for the quality assessment of olive oil. The fluorescence spectra were obtained by exciting the samples at 365 nm and 395 nm under identical conditions. The dataset includes the values of the following chemical parameters for each olive oil sample: acidity, peroxide value, K270, K232, ethyl esters, and the quality of the samples (EVOO, VOO, or LOO). The dataset offers a unique possibility for researchers in food technology to develop machine learning models based on fluorescence data for the quality assessment of olive oil due to the availability of both spectroscopic and chemical data. The dataset can be used, for example, to predict one or multiple chemical parameters or to classify samples based on their quality from fluorescence spectra.
New Metric Formulas that Include Measurement Errors in Machine Learning for Natural Sciences
Sep 30, 2022


The application of machine learning to physics problems is widely found in the scientific literature. Both regression and classification problems are addressed by a large array of techniques that involve learning algorithms. Unfortunately, the measurement errors of the data used to train machine learning models are almost always neglected. This leads to estimations of the performance of the models (and thus their generalisation power) that is too optimistic since it is always assumed that the target variables (what one wants to predict) are correct. In physics, this is a dramatic deficiency as it can lead to the belief that theories or patterns exist where, in reality, they do not. This paper addresses this deficiency by deriving formulas for commonly used metrics (both for regression and classification problems) that take into account measurement errors of target variables. The new formulas give an estimation of the metrics which is always more pessimistic than what is obtained with the classical ones, not taking into account measurement errors. The formulas given here are of general validity, completely model-independent, and can be applied without limitations. Thus, with statistical confidence, one can analyze the existence of relationships when dealing with measurements with errors of any kind. The formulas have wide applicability outside physics and can be used in all problems where measurement errors are relevant to the conclusions of studies.
Physico-chemical properties extraction from the fluorescence spectrum with 1D-convolutional neural networks: application to olive oil
Apr 09, 2022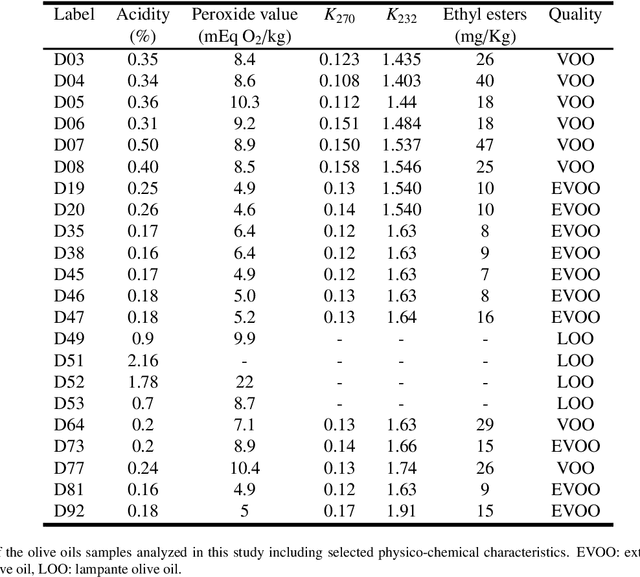

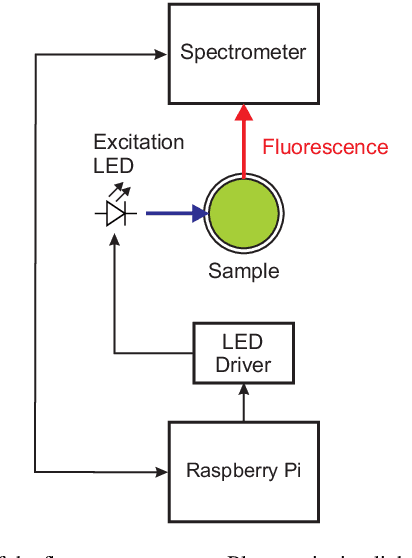

The olive oil sector produces a substantial impact in the Mediterranean's economy and lifestyle. Many studies exist which try to optimize the different steps in the olive oil's production process. One of the main challenges for olive oil producers is the ability to asses and control the quality during the production cycle. For this purpose, several parameters need to be determined, such as the acidity, the UV absorption or the ethyl esters content. To achieve this, samples must be sent to an approved laboratory for chemical analysis. This approach is expensive and cannot be performed very frequently, making quality control of olive oil a real challenge. This work explores a new approach based on fluorescence spectroscopy and artificial intelligence (namely, 1-D convolutional neural networks) to predict the five chemical quality indicators of olive oil (acidity, peroxide value, UV spectroscopic parameters $K_{270}$ and $K_{232}$, and ethyl esters) from simple fluorescence spectra. Fluorescence spectroscopy is a very attractive optical technique since it does not require sample preparation, is non destructive, and, as shown in this work, can be easily implemented in small and cost-effective sensors. The results indicate that the proposed approach gives exceptional results in the quality determination and would make the continuous quality control of olive oil during and after the production process a reality. Additionally, this novel methodology presents potential applications as a support for quality specifications of olive oil, as defined by the European regulation.
A Model-Agnostic Algorithm for Bayes Error Determination in Binary Classification
Jul 24, 2021

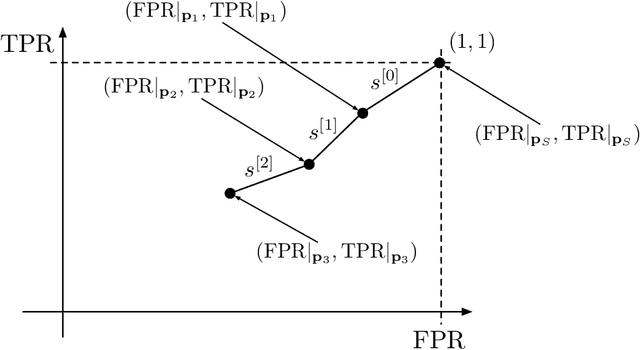
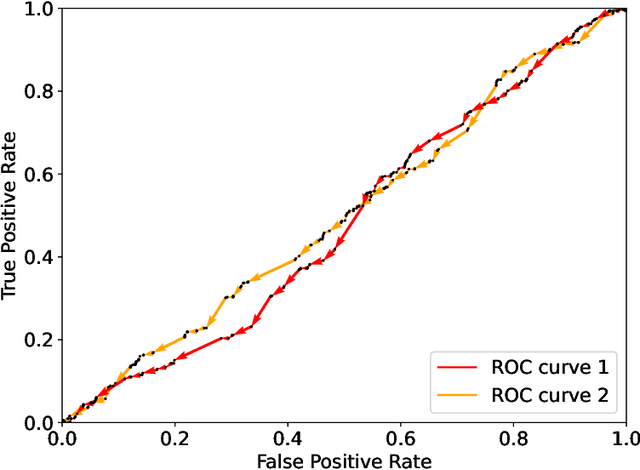
This paper presents the intrinsic limit determination algorithm (ILD Algorithm), a novel technique to determine the best possible performance, measured in terms of the AUC (area under the ROC curve) and accuracy, that can be obtained from a specific dataset in a binary classification problem with categorical features {\sl regardless} of the model used. This limit, namely the Bayes error, is completely independent of any model used and describes an intrinsic property of the dataset. The ILD algorithm thus provides important information regarding the prediction limits of any binary classification algorithm when applied to the considered dataset. In this paper the algorithm is described in detail, its entire mathematical framework is presented and the pseudocode is given to facilitate its implementation. Finally, an example with a real dataset is given.
Exploration of Spanish Olive Oil Quality with a Miniaturized Low-Cost Fluorescence Sensor and Machine Learning Techniques
Apr 09, 2021
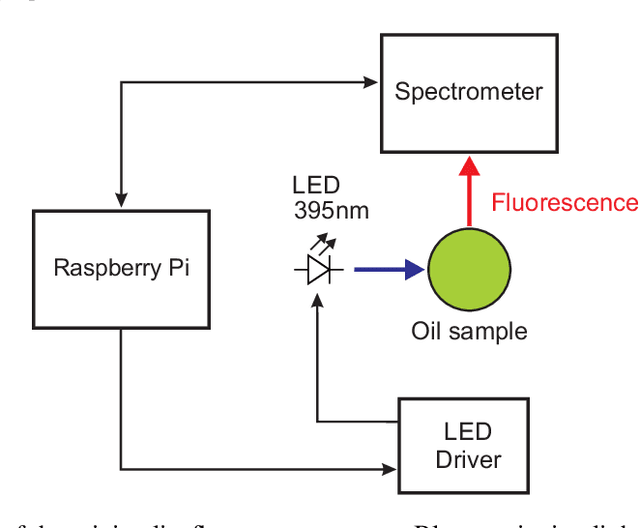


Extra virgin olive oil (EVOO) is the highest quality of olive oil and is characterized by highly beneficial nutritional properties. The large increase in both consumption and fraud, for example through adulteration, creates new challenges and an increasing demand for developing new quality assessment methodologies that are easier and cheaper to perform. As of today, the determination of olive oil quality is performed by producers through chemical analysis and organoleptic evaluation. The chemical analysis requires the advanced equipment and chemical knowledge of certified laboratories, and has therefore a limited accessibility. In this work a minimalist, portable and low-cost sensor is presented, which can perform olive oil quality assessment using fluorescence spectroscopy. The potential of the proposed technology is explored by analyzing several olive oils of different quality levels, EVOO, virgin olive oil (VOO), and lampante olive oil (LOO). The spectral data were analyzed using a large number of machine learning methods, including artificial neural networks. The analysis performed in this work demonstrates the possibility of performing classification of olive oil in the three mentioned classes with an accuracy of 100$\%$. These results confirm that this minimalist low-cost sensor has the potential of substituting expensive and complex chemical analysis.