 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling missing values in healthcare data: A systematic review of deep learning-based imputation techniques
Paper and Code
Oct 15, 2022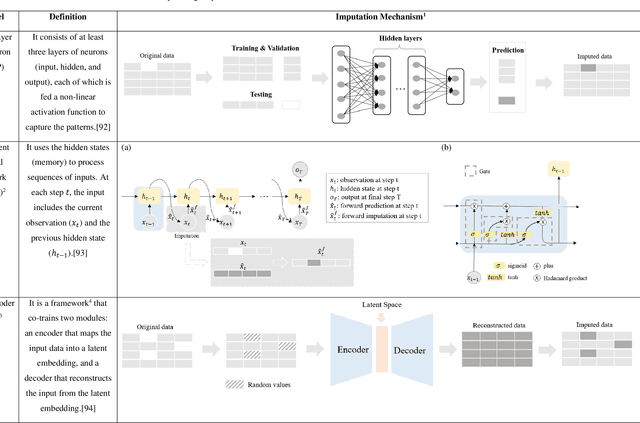
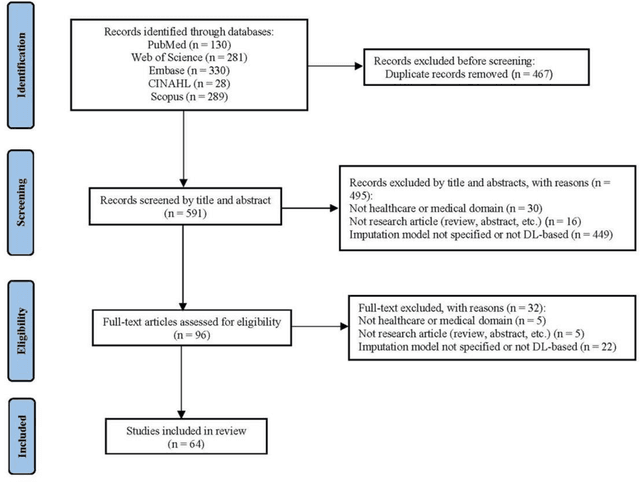
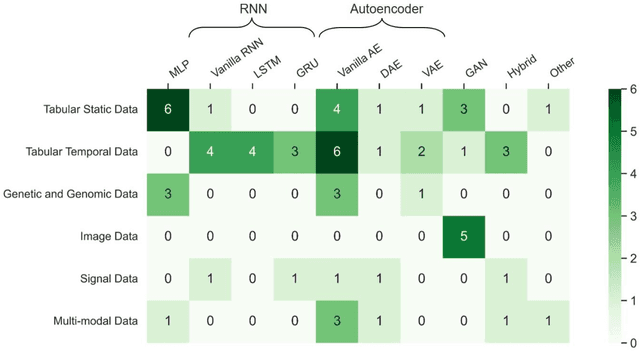
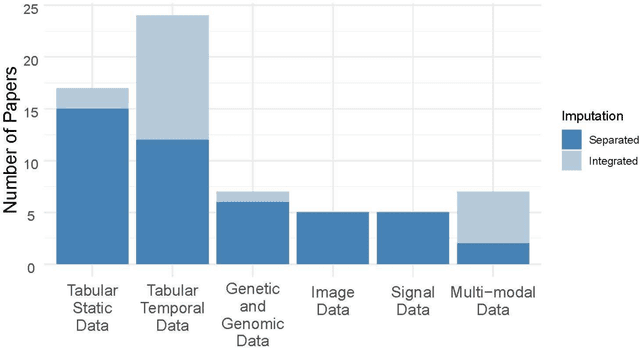
Objective: The proper handling of missing values is critical to delivering reliable estimates and decisions, especially in high-stakes fields such as clinical research. The increasing diversity and complexity of data have led many researchers to develop deep learning (DL)-based imputation techniques. We conducted a systematic review to evaluate the use of these techniques, with a particular focus on data types, aiming to assist healthcare researchers from various disciplines in dealing with missing values. Methods: We searched five databases (MEDLINE, Web of Science, Embase, CINAHL, and Scopus) for articles published prior to August 2021 that applied DL-based models to imputation. We assessed selected publications from four perspectives: health data types, model backbone (i.e., main architecture), imputation strategies, and comparison with non-DL-based methods. Based on data types, we created an evidence map to illustrate the adoption of DL models. Results: We included 64 articles, of which tabular static (26.6%, 17/64) and temporal data (37.5%, 24/64) were the most frequently investigated. We found that model backbone(s) differed among data types as well as the imputation strategy. The "integrated" strategy, that is, the imputation task being solved concurrently with downstream tasks, was popular for tabular temporal (50%, 12/24) and multi-modal data (71.4%, 5/7), but limited for other data types. Moreover, DL-based imputation methods yielded better imputation accuracy in most studies, compared with non-DL-based methods. Conclusion: DL-based imputation models can be customized based on data type, addressing the corresponding missing patterns, and its associated "integrated" strategy can enhance the efficacy of imputation, especially in scenarios where data is complex. Future research may focus on the portability and fairness of DL-based models for healthcare data imputation.