 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTestAug: A Framework for Augmenting Capability-based NLP Tests
Oct 14, 2022
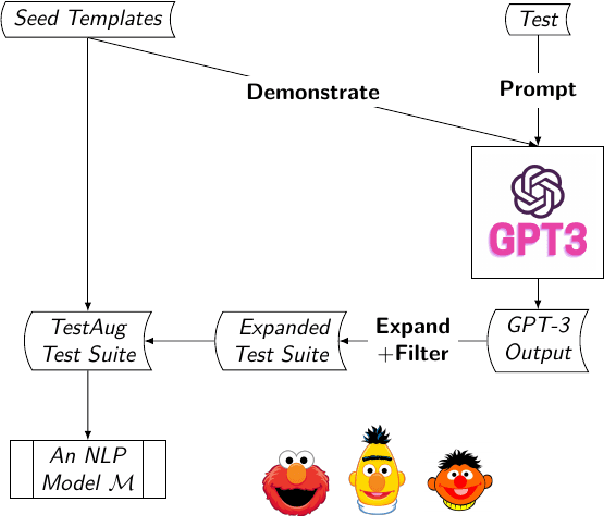

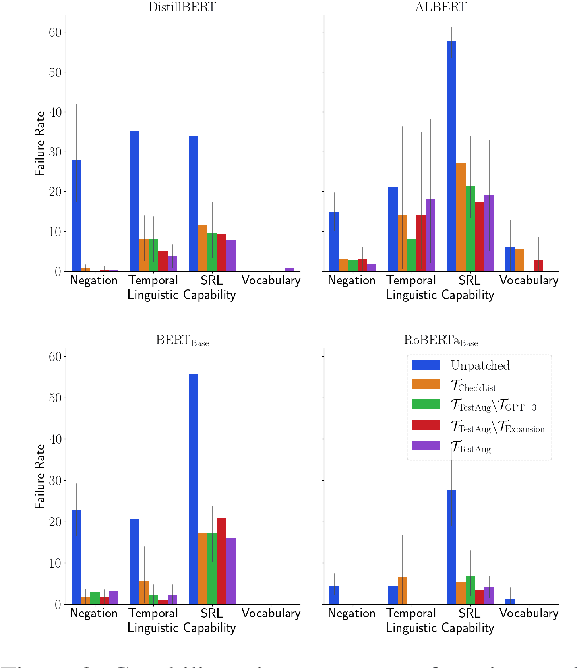
The recently proposed capability-based NLP testing allows model developers to test the functional capabilities of NLP models, revealing functional failures that cannot be detected by the traditional heldout mechanism. However, existing work on capability-based testing requires extensive manual efforts and domain expertise in creating the test cases. In this paper, we investigate a low-cost approach for the test case generation by leveraging the GPT-3 engine. We further propose to use a classifier to remove the invalid outputs from GPT-3 and expand the outputs into templates to generate more test cases. Our experiments show that TestAug has three advantages over the existing work on behavioral testing: (1) TestAug can find more bugs than existing work; (2) The test cases in TestAug are more diverse; and (3) TestAug largely saves the manual efforts in creating the test suites. The code and data for TestAug can be found at our project website (https://guanqun-yang.github.io/testaug/) and GitHub (https://github.com/guanqun-yang/testaug).
Few-Sample Named Entity Recognition for Security Vulnerability Reports by Fine-Tuning Pre-Trained Language Models
Aug 14, 2021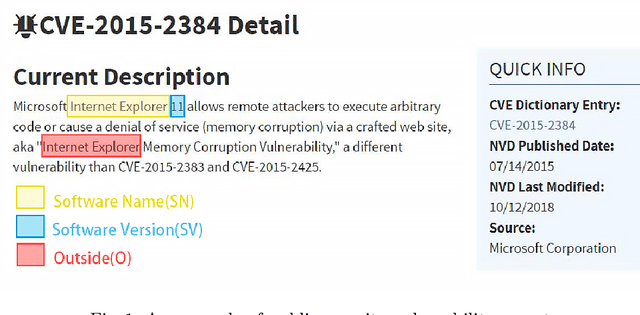
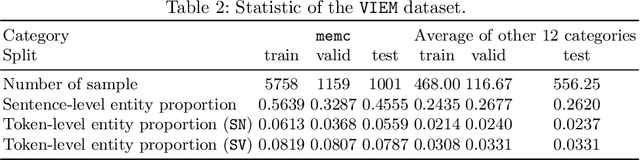
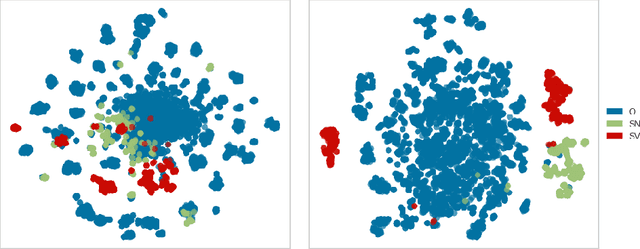
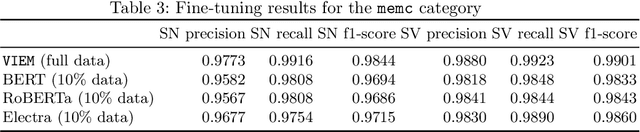
Public security vulnerability reports (e.g., CVE reports) play an important role in the maintenance of computer and network systems. Security companies and administrators rely on information from these reports to prioritize tasks on developing and deploying patches to their customers. Since these reports are unstructured texts, automatic information extraction (IE) can help scale up the processing by converting the unstructured reports to structured forms, e.g., software names and versions and vulnerability types. Existing works on automated IE for security vulnerability reports often rely on a large number of labeled training samples. However, creating massive labeled training set is both expensive and time consuming. In this work, for the first time, we propose to investigate this problem where only a small number of labeled training samples are available. In particular, we investigate the performance of fine-tuning several state-of-the-art pre-trained language models on our small training dataset. The results show that with pre-trained language models and carefully tuned hyperparameters, we have reached or slightly outperformed the state-of-the-art system on this task. Consistent with previous two-step process of first fine-tuning on main category and then transfer learning to others as in [7], if otherwise following our proposed approach, the number of required labeled samples substantially decrease in both stages: 90% reduction in fine-tuning from 5758 to 576,and 88.8% reduction in transfer learning with 64 labeled samples per category. Our experiments thus demonstrate the effectiveness of few-sample learning on NER for security vulnerability report. This result opens up multiple research opportunities for few-sample learning for security vulnerability reports, which is discussed in the paper. Code: https://github.com/guanqun-yang/FewVulnerability.