 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Google AI Overviews: Activation, Source Quality, Claim Fidelity, and Publisher Impact
May 13, 2026Google AI Overviews (AIOs) are arguably the most widely encountered deployment of generative AI, reaching over 2 billion users who may not realize the answers they see are AI-generated. Where search engines have traditionally surfaced ranked sources and left users to evaluate them, AIOs synthesize and deliver a single answer - giving Google unprecedented editorial control over what users read and know. We present a large-scale longitudinal measurement study, issuing 55,393 trending queries across 19 topical categories over a 40-day window (March 13 - April 21, 2026). We report four main findings. First, overall AIO activation is 13.7%, rising to 64.7% for question-form queries, while politically sensitive topics see markedly lower rates. Second, AIO-cited domains are more credible than co-displayed first-page results, yet nearly 30% do not appear in those results at all, indicating a source selection mechanism distinct from Google's ranking algorithm. Third, decomposing responses into 98,020 atomic claims, 11.0% are unsupported by the cited pages - with omission the dominant failure mode - and source quality and claim fidelity are largely independent. Fourth, well over half of AIO-cited pages carry display advertising, meaning publishers lose revenue when AIOs suppress the click-through, even as Google's own sponsored ads continue to appear on the same page. Together, these findings document a rapid transformation of the online information ecosystem whose consequences for epistemic security remain poorly understood.
Visual Cues of Gender and Race are Associated with Stereotyping in Vision-Language Models
Mar 07, 2025Current research on bias in Vision Language Models (VLMs) has important limitations: it is focused exclusively on trait associations while ignoring other forms of stereotyping, it examines specific contexts where biases are expected to appear, and it conceptualizes social categories like race and gender as binary, ignoring the multifaceted nature of these identities. Using standardized facial images that vary in prototypicality, we test four VLMs for both trait associations and homogeneity bias in open-ended contexts. We find that VLMs consistently generate more uniform stories for women compared to men, with people who are more gender prototypical in appearance being represented more uniformly. By contrast, VLMs represent White Americans more uniformly than Black Americans. Unlike with gender prototypicality, race prototypicality was not related to stronger uniformity. In terms of trait associations, we find limited evidence of stereotyping-Black Americans were consistently linked with basketball across all models, while other racial associations (i.e., art, healthcare, appearance) varied by specific VLM. These findings demonstrate that VLM stereotyping manifests in ways that go beyond simple group membership, suggesting that conventional bias mitigation strategies may be insufficient to address VLM stereotyping and that homogeneity bias persists even when trait associations are less apparent in model outputs.
The Effect of Group Status on the Variability of Group Representations in LLM-generated Text
Jan 16, 2024
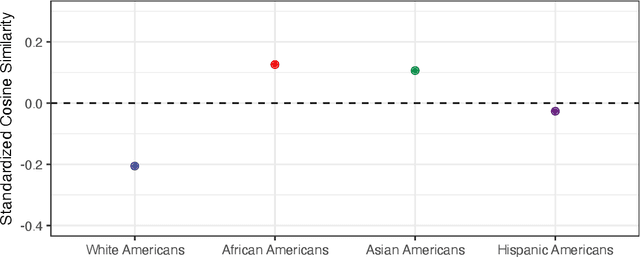


Large Language Models (LLMs) have become pervasive in everyday life, yet their inner workings remain opaque. While scholarly efforts have demonstrated LLMs' propensity to reproduce biases in their training data, they have primarily focused on the association of social groups with stereotypic attributes. In this paper, we extend this line of inquiry to investigate a bias akin to the social-psychological phenomenon where socially dominant groups are perceived to be less homogeneous than socially subordinate groups as it is reproduced by LLMs. We had ChatGPT, a state-of-the-art LLM, generate a diversity of texts about intersectional group identities and compared text homogeneity. We consistently find that LLMs portray African, Asian, and Hispanic Americans as more homogeneous than White Americans. They also portray women as more homogeneous than men, but these differences are small. Finally, we find that the effect of gender differs across racial/ethnic groups such that the effect of gender is consistent within African and Hispanic Americans but not within Asian and White Americans. We speculate possible sources of this bias in LLMs and posit that the bias has the potential to amplify biases in future LLM training and to reinforce stereotypes.
GPIRT: A Gaussian Process Model for Item Response Theory
Jun 17, 2020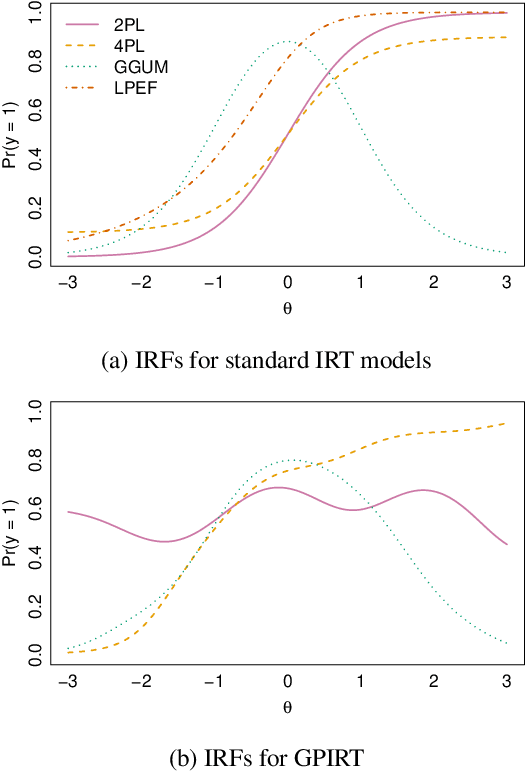



The goal of item response theoretic (IRT) models is to provide estimates of latent traits from binary observed indicators and at the same time to learn the item response functions (IRFs) that map from latent trait to observed response. However, in many cases observed behavior can deviate significantly from the parametric assumptions of traditional IRT models. Nonparametric IRT models overcome these challenges by relaxing assumptions about the form of the IRFs, but standard tools are unable to simultaneously estimate flexible IRFs and recover ability estimates for respondents. We propose a Bayesian nonparametric model that solves this problem by placing Gaussian process priors on the latent functions defining the IRFs. This allows us to simultaneously relax assumptions about the shape of the IRFs while preserving the ability to estimate latent traits. This in turn allows us to easily extend the model to further tasks such as active learning. GPIRT therefore provides a simple and intuitive solution to several longstanding problems in the IRT literature.