 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Group Status on the Variability of Group Representations in LLM-generated Text
Paper and Code

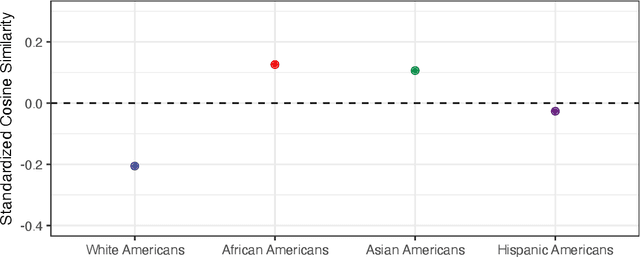


Large Language Models (LLMs) have become pervasive in everyday life, yet their inner workings remain opaque. While scholarly efforts have demonstrated LLMs' propensity to reproduce biases in their training data, they have primarily focused on the association of social groups with stereotypic attributes. In this paper, we extend this line of inquiry to investigate a bias akin to the social-psychological phenomenon where socially dominant groups are perceived to be less homogeneous than socially subordinate groups as it is reproduced by LLMs. We had ChatGPT, a state-of-the-art LLM, generate a diversity of texts about intersectional group identities and compared text homogeneity. We consistently find that LLMs portray African, Asian, and Hispanic Americans as more homogeneous than White Americans. They also portray women as more homogeneous than men, but these differences are small. Finally, we find that the effect of gender differs across racial/ethnic groups such that the effect of gender is consistent within African and Hispanic Americans but not within Asian and White Americans. We speculate possible sources of this bias in LLMs and posit that the bias has the potential to amplify biases in future LLM training and to reinforce stereotypes.