 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cost-Effective LLM-based Approach to Identify Wildlife Trafficking in Online Marketplaces
Apr 29, 2025Wildlife trafficking remains a critical global issue, significantly impacting biodiversity, ecological stability, and public health. Despite efforts to combat this illicit trade, the rise of e-commerce platforms has made it easier to sell wildlife products, putting new pressure on wild populations of endangered and threatened species. The use of these platforms also opens a new opportunity: as criminals sell wildlife products online, they leave digital traces of their activity that can provide insights into trafficking activities as well as how they can be disrupted. The challenge lies in finding these traces. Online marketplaces publish ads for a plethora of products, and identifying ads for wildlife-related products is like finding a needle in a haystack. Learning classifiers can automate ad identification, but creating them requires costly, time-consuming data labeling that hinders support for diverse ads and research questions. This paper addresses a critical challenge in the data science pipeline for wildlife trafficking analytics: generating quality labeled data for classifiers that select relevant data. While large language models (LLMs) can directly label advertisements, doing so at scale is prohibitively expensive. We propose a cost-effective strategy that leverages LLMs to generate pseudo labels for a small sample of the data and uses these labels to create specialized classification models. Our novel method automatically gathers diverse and representative samples to be labeled while minimizing the labeling costs. Our experimental evaluation shows that our classifiers achieve up to 95% F1 score, outperforming LLMs at a lower cost. We present real use cases that demonstrate the effectiveness of our approach in enabling analyses of different aspects of wildlife trafficking.
A Flexible and Scalable Approach for Collecting Wildlife Advertisements on the Web
Jul 26, 2024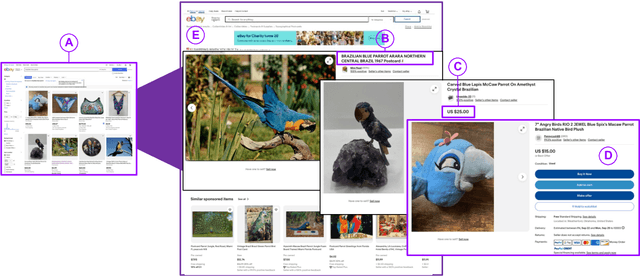
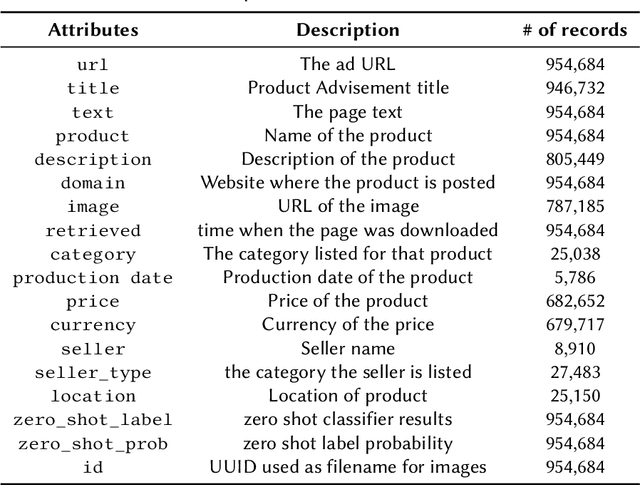

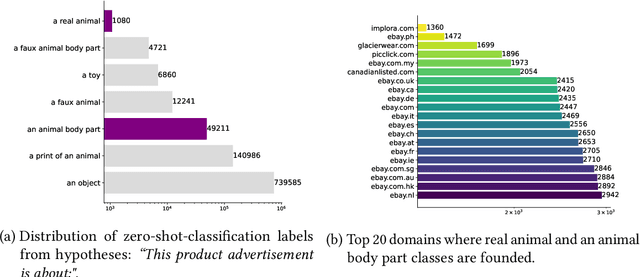
Wildlife traffickers are increasingly carrying out their activities in cyberspace. As they advertise and sell wildlife products in online marketplaces, they leave digital traces of their activity. This creates a new opportunity: by analyzing these traces, we can obtain insights into how trafficking networks work as well as how they can be disrupted. However, collecting such information is difficult. Online marketplaces sell a very large number of products and identifying ads that actually involve wildlife is a complex task that is hard to automate. Furthermore, given that the volume of data is staggering, we need scalable mechanisms to acquire, filter, and store the ads, as well as to make them available for analysis. In this paper, we present a new approach to collect wildlife trafficking data at scale. We propose a data collection pipeline that combines scoped crawlers for data discovery and acquisition with foundational models and machine learning classifiers to identify relevant ads. We describe a dataset we created using this pipeline which is, to the best of our knowledge, the largest of its kind: it contains almost a million ads obtained from 41 marketplaces, covering 235 species and 20 languages. The source code is publicly available at \url{https://github.com/VIDA-NYU/wildlife_pipeline}.