 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetful Forests: high performance learning data structures for streaming data under concept drift
Dec 15, 2022Database research can help machine learning performance in many ways. One way is to design better data structures. This paper combines the use of incremental computation and sequential and probabilistic filtering to enable "forgetful" tree-based learning algorithms to cope with concept drift data (i.e., data whose function from input to classification changes over time). The forgetful algorithms described in this paper achieve high time performance while maintaining high quality predictions on streaming data. Specifically, the algorithms are up to 24 times faster than state-of-the-art incremental algorithms with at most a 2% loss of accuracy, or at least twice faster without any loss of accuracy. This makes such structures suitable for high volume streaming applications.
AlphaMLDigger: A Novel Machine Learning Solution to Explore Excess Return on Investment
Jun 22, 2022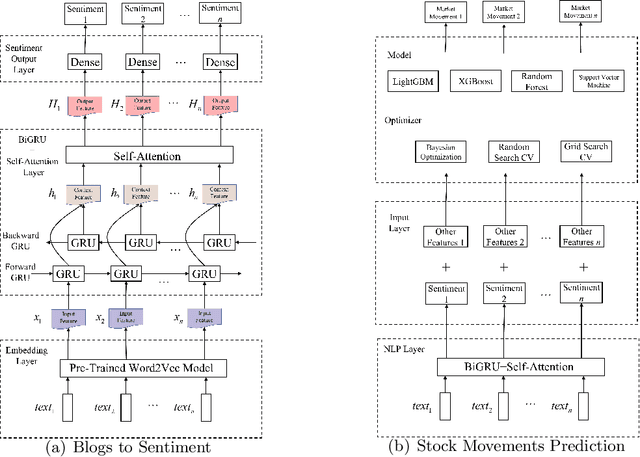

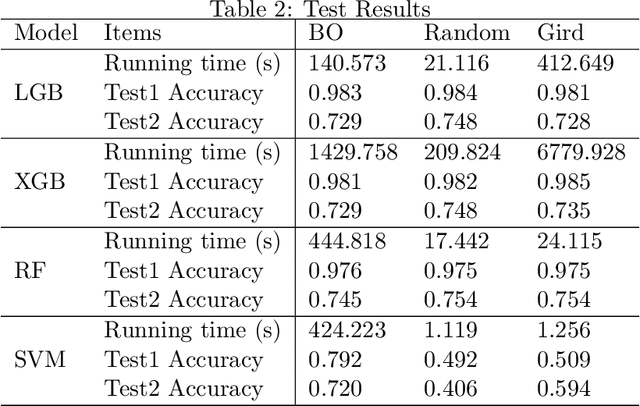
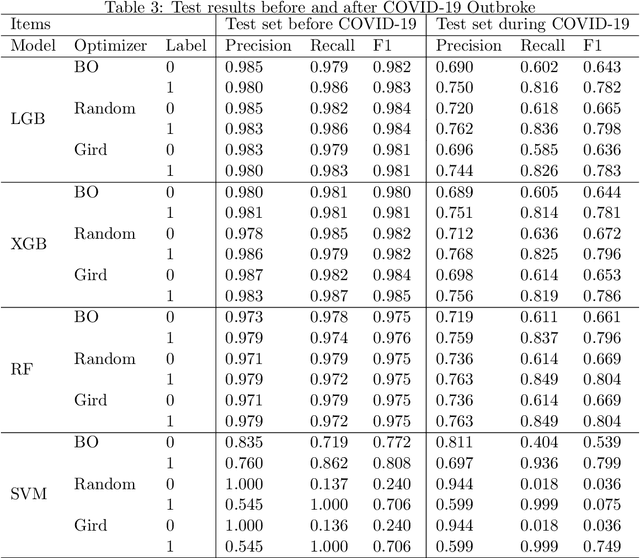
How to quickly and automatically mine effective information and serve investment decisions has attracted more and more attention from academia and industry. And new challenges have been raised with the global pandemic. This paper proposes a two-phase AlphaMLDigger that effectively finds excessive returns in the highly fluctuated market. In phase 1, a deep sequential NLP model is proposed to transfer blogs on Sina Microblog to market sentiment. In phase 2, the predicted market sentiment is combined with social network indicator features and stock market history features to predict the stock movements with different Machine Learning models and optimizers. The results show that our AlphaMLDigger achieves higher accuracy in the test set than previous works and is robust to the negative impact of COVID-19 to some extent.