 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEERO: Early Exit with Reject Option for Efficient Classification with limited budget
Feb 06, 2024The increasing complexity of advanced machine learning models requires innovative approaches to manage computational resources effectively. One such method is the Early Exit strategy, which allows for adaptive computation by providing a mechanism to shorten the processing path for simpler data instances. In this paper, we propose EERO, a new methodology to translate the problem of early exiting to a problem of using multiple classifiers with reject option in order to better select the exiting head for each instance. We calibrate the probabilities of exiting at the different heads using aggregation with exponential weights to guarantee a fixed budget .We consider factors such as Bayesian risk, budget constraints, and head-specific budget consumption. Experimental results, conducted using a ResNet-18 model and a ConvNext architecture on Cifar and ImageNet datasets, demonstrate that our method not only effectively manages budget allocation but also enhances accuracy in overthinking scenarios.
Objects Localisation from Motion with Constraints
Oct 28, 2018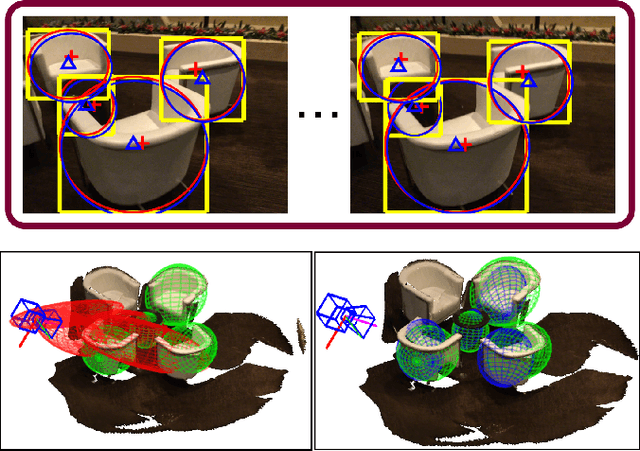
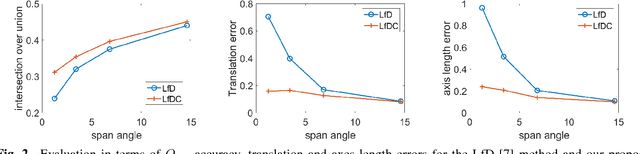
This paper presents a method to estimate the 3D object position and occupancy given a set of object detections in multiple images and calibrated cameras. This problem is modelled as the estimation of a set of quadrics given 2D conics fit to the object bounding boxes. Although a closed form solution has been recently proposed, the resulting quadrics can be inaccurate or even be non valid ellipsoids in presence of noisy and inaccurate detections. This effect is especially important in case of small baselines, resulting in dramatic failures. To cope with this problem, we propose a set of linear constraints by matching the centres of the reprojected quadrics with the centres of the observed conics. These constraints can be solved with a linear system thus providing a more computationally efficient solution with respect to a non-linear alternative. Experiments on real data show that the proposed approach improves significantly the accuracy and the validity of the ellipsoids.
Visual Graphs from Motion (VGfM): Scene understanding with object geometry reasoning
Jul 16, 2018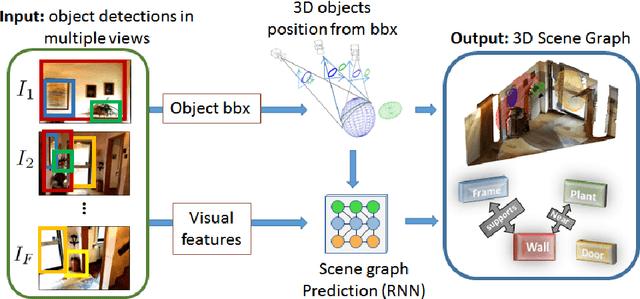
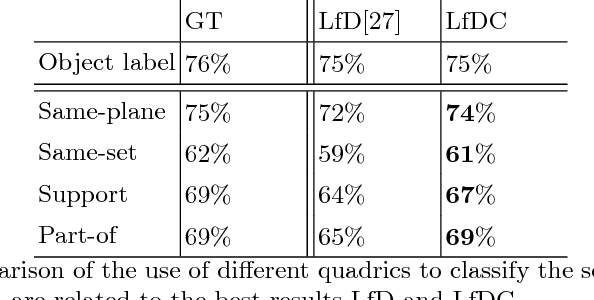

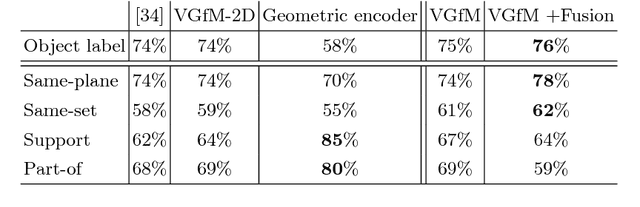
Recent approaches on visual scene understanding attempt to build a scene graph -- a computational representation of objects and their pairwise relationships. Such rich semantic representation is very appealing, yet difficult to obtain from a single image, especially when considering complex spatial arrangements in the scene. Differently, an image sequence conveys useful information using the multi-view geometric relations arising from camera motion. Indeed, in such cases, object relationships are naturally related to the 3D scene structure. To this end, this paper proposes a system that first computes the geometrical location of objects in a generic scene and then efficiently constructs scene graphs from video by embedding such geometrical reasoning. Such compelling representation is obtained using a new model where geometric and visual features are merged using an RNN framework. We report results on a dataset we created for the task of 3D scene graph generation in multiple views.