 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Inference with Self-Supervised Early Exits
Jul 30, 2024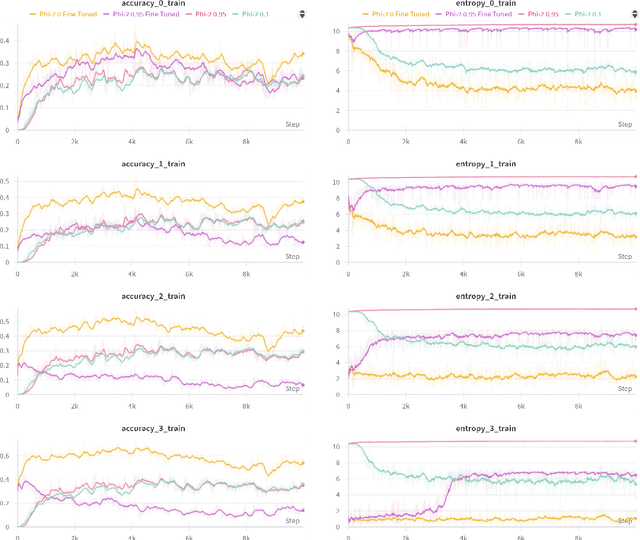
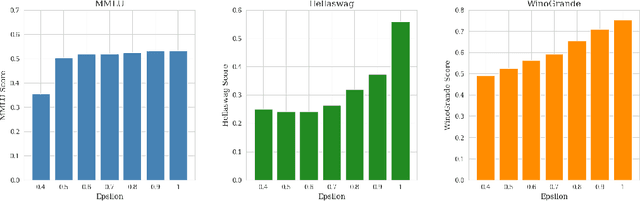
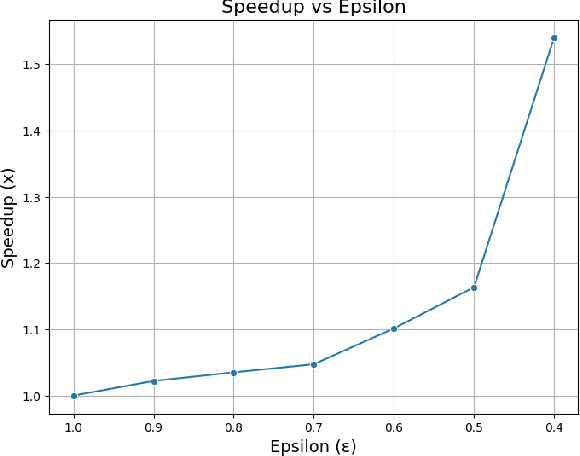
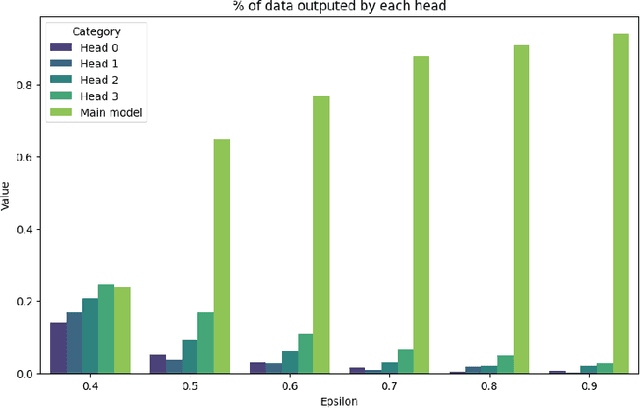
This paper presents a novel technique for accelerating inference in large, pre-trained language models (LLMs) by introducing early exits during inference. The computational demands of these models, used across a wide range of applications, can be substantial. By capitalizing on the inherent variability in token complexity, our approach enables selective acceleration of the inference process. Specifically, we propose the integration of early exit ''heads'' atop existing transformer layers, which facilitate conditional terminations based on a confidence metric. These heads are trained in a self-supervised manner using the model's own predictions as training data, thereby eliminating the need for additional annotated data. The confidence metric, established using a calibration set, ensures a desired level of accuracy while enabling early termination when confidence exceeds a predetermined threshold. Notably, our method preserves the original accuracy and reduces computational time on certain tasks, leveraging the existing knowledge of pre-trained LLMs without requiring extensive retraining. This lightweight, modular modification has the potential to greatly enhance the practical usability of LLMs, particularly in applications like real-time language processing in resource-constrained environments.
EERO: Early Exit with Reject Option for Efficient Classification with limited budget
Feb 06, 2024The increasing complexity of advanced machine learning models requires innovative approaches to manage computational resources effectively. One such method is the Early Exit strategy, which allows for adaptive computation by providing a mechanism to shorten the processing path for simpler data instances. In this paper, we propose EERO, a new methodology to translate the problem of early exiting to a problem of using multiple classifiers with reject option in order to better select the exiting head for each instance. We calibrate the probabilities of exiting at the different heads using aggregation with exponential weights to guarantee a fixed budget .We consider factors such as Bayesian risk, budget constraints, and head-specific budget consumption. Experimental results, conducted using a ResNet-18 model and a ConvNext architecture on Cifar and ImageNet datasets, demonstrate that our method not only effectively manages budget allocation but also enhances accuracy in overthinking scenarios.