 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Large Language Model Inference with Self-Supervised Early Exits
Paper and Code
Jul 30, 2024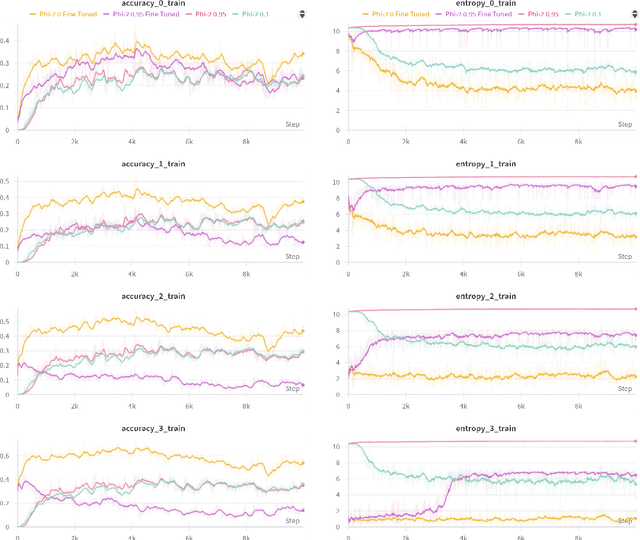
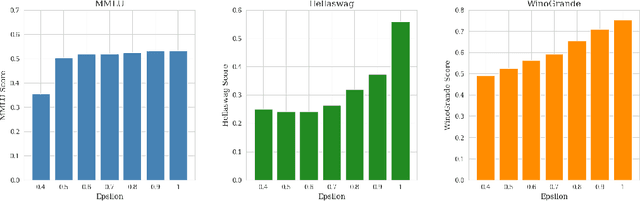
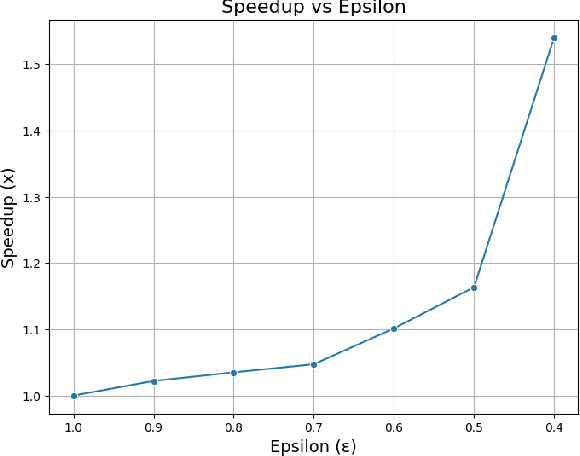
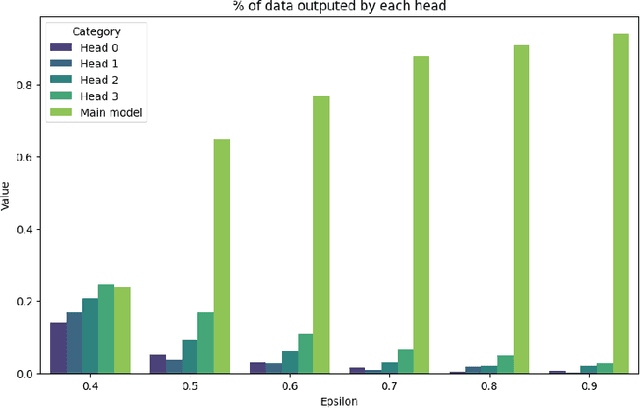
This paper presents a novel technique for accelerating inference in large, pre-trained language models (LLMs) by introducing early exits during inference. The computational demands of these models, used across a wide range of applications, can be substantial. By capitalizing on the inherent variability in token complexity, our approach enables selective acceleration of the inference process. Specifically, we propose the integration of early exit ''heads'' atop existing transformer layers, which facilitate conditional terminations based on a confidence metric. These heads are trained in a self-supervised manner using the model's own predictions as training data, thereby eliminating the need for additional annotated data. The confidence metric, established using a calibration set, ensures a desired level of accuracy while enabling early termination when confidence exceeds a predetermined threshold. Notably, our method preserves the original accuracy and reduces computational time on certain tasks, leveraging the existing knowledge of pre-trained LLMs without requiring extensive retraining. This lightweight, modular modification has the potential to greatly enhance the practical usability of LLMs, particularly in applications like real-time language processing in resource-constrained environments.