 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Fair Empirical Risk Minimization
Paper and Code
Jan 29, 2019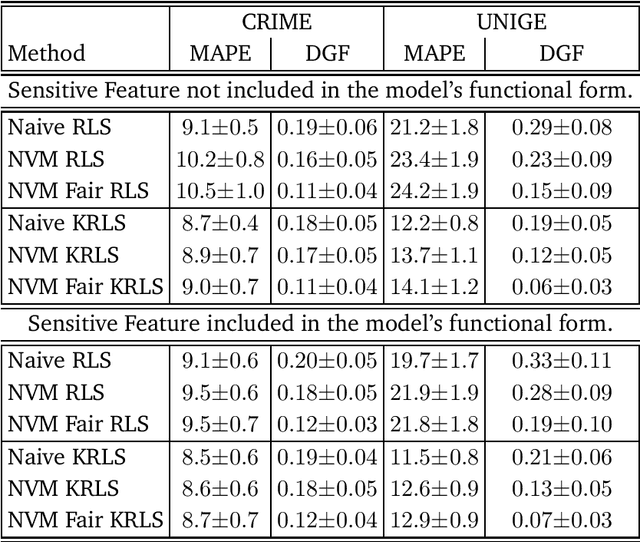

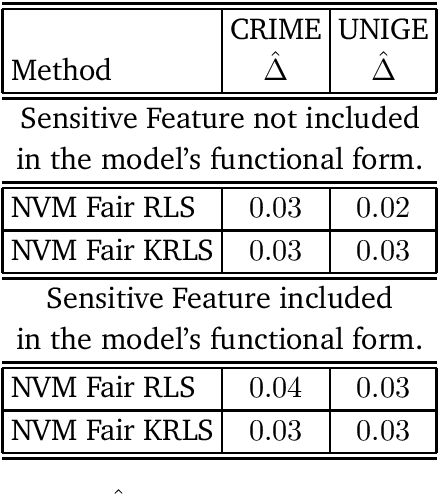
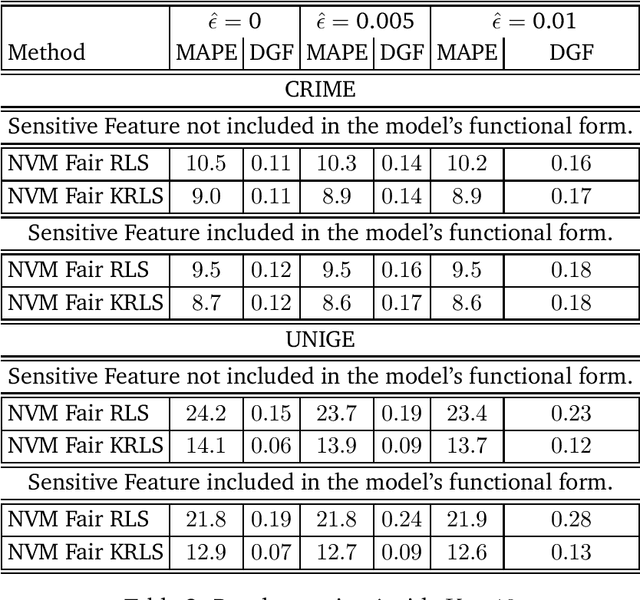
We tackle the problem of algorithmic fairness, where the goal is to avoid the unfairly influence of sensitive information, in the general context of regression with possible continuous sensitive attributes. We extend the framework of fair empirical risk minimization to this general scenario, covering in this way the whole standard supervised learning setting. Our generalized fairness measure reduces to well known notions of fairness available in literature. We derive learning guarantees for our method, that imply in particular its statistical consistency, both in terms of the risk and the fairness measure. We then specialize our approach to kernel methods and propose a convex fair estimator in that setting. We test the estimator on a commonly used benchmark dataset (Communities and Crime) and on a new dataset collected at the University of Genova, containing the information of the academic career of five thousand students. The latter dataset provides a challenging real case scenario of unfair behaviour of standard regression methods that benefits from our methodology. The experimental results show that our estimator is effective at mitigating the trade-off between accuracy and fairness requirements.