 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Boosting for Class Imbalance
Jun 05, 2017
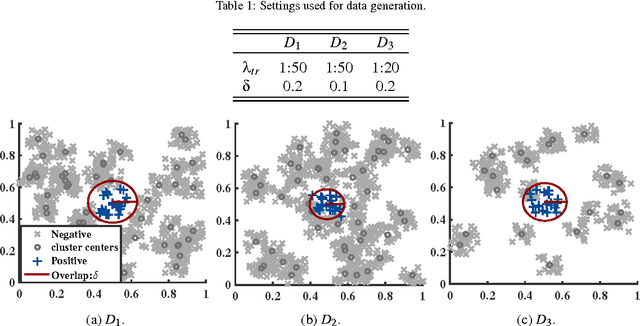


Pattern recognition applications often suffer from skewed data distributions between classes, which may vary during operations w.r.t. the design data. Two-class classification systems designed using skewed data tend to recognize the majority class better than the minority class of interest. Several data-level techniques have been proposed to alleviate this issue by up-sampling minority samples or under-sampling majority samples. However, some informative samples may be neglected by random under-sampling and adding synthetic positive samples through up-sampling adds to training complexity. In this paper, a new ensemble learning algorithm called Progressive Boosting (PBoost) is proposed that progressively inserts uncorrelated groups of samples into a Boosting procedure to avoid loss of information while generating a diverse pool of classifiers. Base classifiers in this ensemble are generated from one iteration to the next, using subsets from a validation set that grows gradually in size and imbalance. Consequently, PBoost is more robust to unknown and variable levels of skew in operational data, and has lower computation complexity than Boosting ensembles in literature. In PBoost, a new loss factor is proposed to avoid bias of performance towards the negative class. Using this loss factor, the weight update of samples and classifier contribution in final predictions are set based on the ability to recognize both classes. Using the proposed loss factor instead of standard accuracy can avoid biasing performance in any Boosting ensemble. The proposed approach was validated and compared using synthetic data, videos from the FIA dataset that emulates face re-identification applications, and KEEL collection of datasets. Results show that PBoost can outperform state of the art techniques in terms of both accuracy and complexity over different levels of imbalance and overlap between classes.