 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Vector Machines under Adversarial Label Contamination
Jun 01, 2022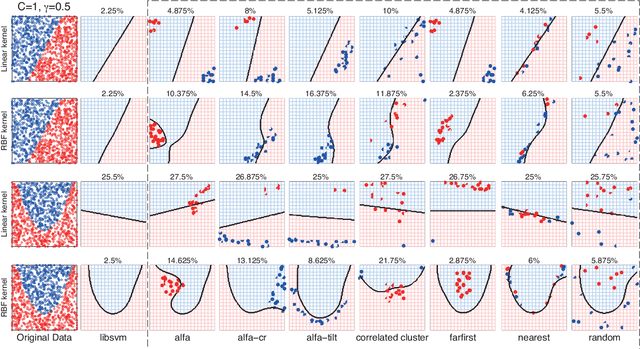
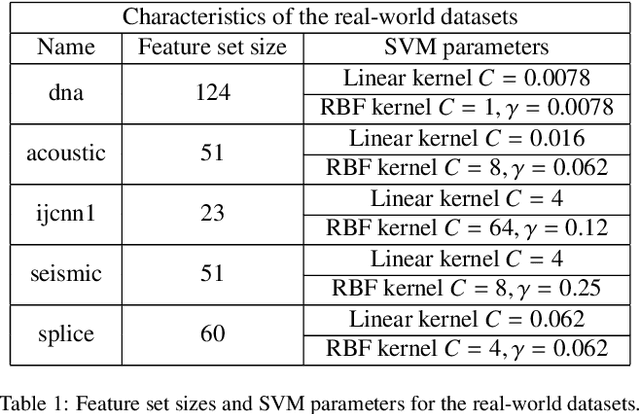
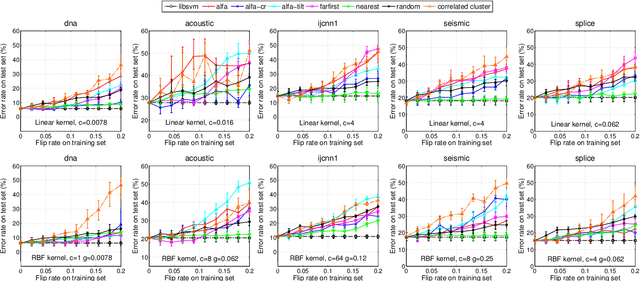
Machine learning algorithms are increasingly being applied in security-related tasks such as spam and malware detection, although their security properties against deliberate attacks have not yet been widely understood. Intelligent and adaptive attackers may indeed exploit specific vulnerabilities exposed by machine learning techniques to violate system security. Being robust to adversarial data manipulation is thus an important, additional requirement for machine learning algorithms to successfully operate in adversarial settings. In this work, we evaluate the security of Support Vector Machines (SVMs) to well-crafted, adversarial label noise attacks. In particular, we consider an attacker that aims to maximize the SVM's classification error by flipping a number of labels in the training data. We formalize a corresponding optimal attack strategy, and solve it by means of heuristic approaches to keep the computational complexity tractable. We report an extensive experimental analysis on the effectiveness of the considered attacks against linear and non-linear SVMs, both on synthetic and real-world datasets. We finally argue that our approach can also provide useful insights for developing more secure SVM learning algorithms, and also novel techniques in a number of related research areas, such as semi-supervised and active learning.
Is feature selection secure against training data poisoning?
Apr 21, 2018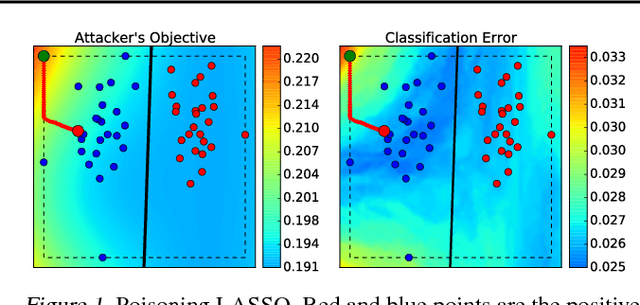
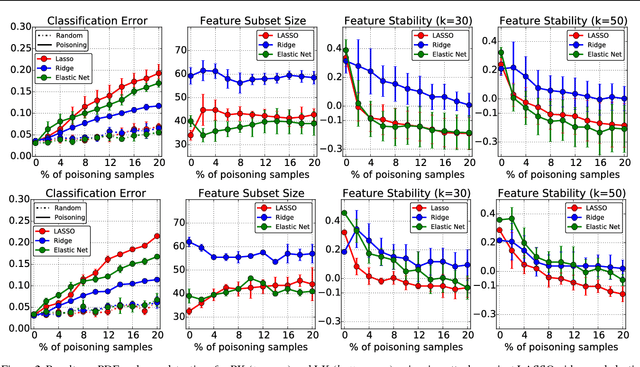
Learning in adversarial settings is becoming an important task for application domains where attackers may inject malicious data into the training set to subvert normal operation of data-driven technologies. Feature selection has been widely used in machine learning for security applications to improve generalization and computational efficiency, although it is not clear whether its use may be beneficial or even counterproductive when training data are poisoned by intelligent attackers. In this work, we shed light on this issue by providing a framework to investigate the robustness of popular feature selection methods, including LASSO, ridge regression and the elastic net. Our results on malware detection show that feature selection methods can be significantly compromised under attack (we can reduce LASSO to almost random choices of feature sets by careful insertion of less than 5% poisoned training samples), highlighting the need for specific countermeasures.