 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Privacy Risk Measurement with Privacy Tokens for Gradient Leakage
Feb 07, 2025



The widespread deployment of deep learning models in privacy-sensitive domains has amplified concerns regarding privacy risks, particularly those stemming from gradient leakage during training. Current privacy assessments primarily rely on post-training attack simulations. However, these methods are inherently reactive, unable to encompass all potential attack scenarios, and often based on idealized adversarial assumptions. These limitations underscore the need for proactive approaches to privacy risk assessment during the training process. To address this gap, we propose the concept of privacy tokens, which are derived directly from private gradients during training. Privacy tokens encapsulate gradient features and, when combined with data features, offer valuable insights into the extent of private information leakage from training data, enabling real-time measurement of privacy risks without relying on adversarial attack simulations. Additionally, we employ Mutual Information (MI) as a robust metric to quantify the relationship between training data and gradients, providing precise and continuous assessments of privacy leakage throughout the training process. Extensive experiments validate our framework, demonstrating the effectiveness of privacy tokens and MI in identifying and quantifying privacy risks. This proactive approach marks a significant advancement in privacy monitoring, promoting the safer deployment of deep learning models in sensitive applications.
Privacy Token: Surprised to Find Out What You Accidentally Revealed
Feb 06, 2025The widespread deployment of deep learning models in privacy-sensitive domains has amplified concerns regarding privacy risks, particularly those stemming from gradient leakage during training. Current privacy assessments primarily rely on post-training attack simulations. However, these methods are inherently reactive, unable to encompass all potential attack scenarios, and often based on idealized adversarial assumptions. These limitations underscore the need for proactive approaches to privacy risk assessment during the training process. To address this gap, we propose the concept of privacy tokens, which are derived directly from private gradients during training. Privacy tokens encapsulate gradient features and, when combined with data features, offer valuable insights into the extent of private information leakage from training data, enabling real-time measurement of privacy risks without relying on adversarial attack simulations. Additionally, we employ Mutual Information (MI) as a robust metric to quantify the relationship between training data and gradients, providing precise and continuous assessments of privacy leakage throughout the training process. Extensive experiments validate our framework, demonstrating the effectiveness of privacy tokens and MI in identifying and quantifying privacy risks. This proactive approach marks a significant advancement in privacy monitoring, promoting the safer deployment of deep learning models in sensitive applications.
Intermediate Outputs Are More Sensitive Than You Think
Dec 01, 2024



The increasing reliance on deep computer vision models that process sensitive data has raised significant privacy concerns, particularly regarding the exposure of intermediate results in hidden layers. While traditional privacy risk assessment techniques focus on protecting overall model outputs, they often overlook vulnerabilities within these intermediate representations. Current privacy risk assessment techniques typically rely on specific attack simulations to assess risk, which can be computationally expensive and incomplete. This paper introduces a novel approach to measuring privacy risks in deep computer vision models based on the Degrees of Freedom (DoF) and sensitivity of intermediate outputs, without requiring adversarial attack simulations. We propose a framework that leverages DoF to evaluate the amount of information retained in each layer and combines this with the rank of the Jacobian matrix to assess sensitivity to input variations. This dual analysis enables systematic measurement of privacy risks at various model layers. Our experimental validation on real-world datasets demonstrates the effectiveness of this approach in providing deeper insights into privacy risks associated with intermediate representations.
Enhancing DP-SGD through Non-monotonous Adaptive Scaling Gradient Weight
Nov 05, 2024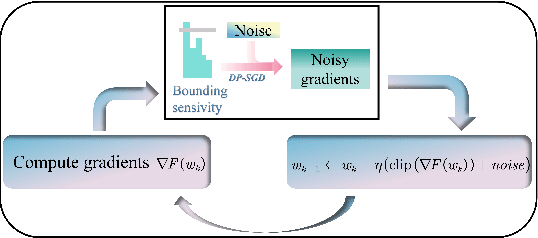
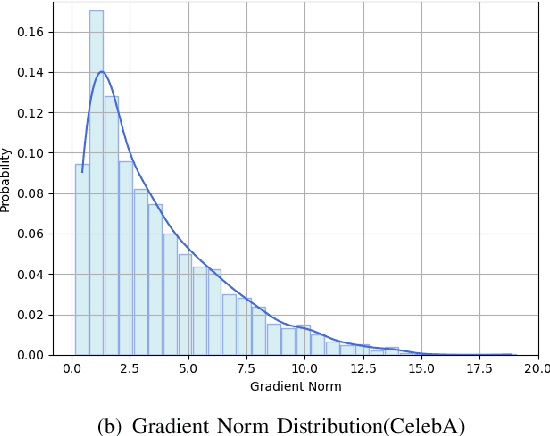
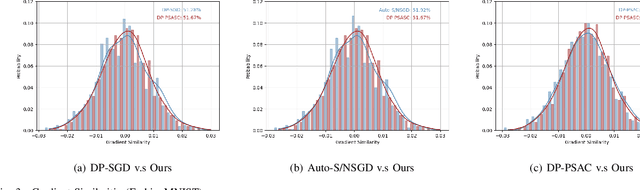
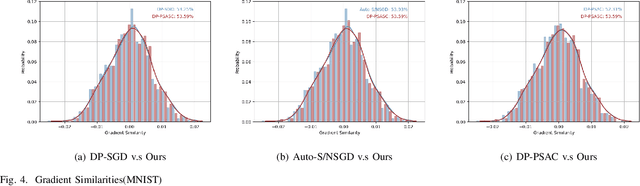
In the domain of deep learning, the challenge of protecting sensitive data while maintaining model utility is significant. Traditional Differential Privacy (DP) techniques such as Differentially Private Stochastic Gradient Descent (DP-SGD) typically employ strategies like direct or per-sample adaptive gradient clipping. These methods, however, compromise model accuracy due to their critical influence on gradient handling, particularly neglecting the significant contribution of small gradients during later training stages. In this paper, we introduce an enhanced version of DP-SGD, named Differentially Private Per-sample Adaptive Scaling Clipping (DP-PSASC). This approach replaces traditional clipping with non-monotonous adaptive gradient scaling, which alleviates the need for intensive threshold setting and rectifies the disproportionate weighting of smaller gradients. Our contribution is twofold. First, we develop a novel gradient scaling technique that effectively assigns proper weights to gradients, particularly small ones, thus improving learning under differential privacy. Second, we integrate a momentum-based method into DP-PSASC to reduce bias from stochastic sampling, enhancing convergence rates. Our theoretical and empirical analyses confirm that DP-PSASC preserves privacy and delivers superior performance across diverse datasets, setting new standards for privacy-sensitive applications.
Machine Unlearning with Minimal Gradient Dependence for High Unlearning Ratios
Jun 24, 2024


In the context of machine unlearning, the primary challenge lies in effectively removing traces of private data from trained models while maintaining model performance and security against privacy attacks like membership inference attacks. Traditional gradient-based unlearning methods often rely on extensive historical gradients, which becomes impractical with high unlearning ratios and may reduce the effectiveness of unlearning. Addressing these limitations, we introduce Mini-Unlearning, a novel approach that capitalizes on a critical observation: unlearned parameters correlate with retrained parameters through contraction mapping. Our method, Mini-Unlearning, utilizes a minimal subset of historical gradients and leverages this contraction mapping to facilitate scalable, efficient unlearning. This lightweight, scalable method significantly enhances model accuracy and strengthens resistance to membership inference attacks. Our experiments demonstrate that Mini-Unlearning not only works under higher unlearning ratios but also outperforms existing techniques in both accuracy and security, offering a promising solution for applications requiring robust unlearning capabilities.