 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Contrastive Unlearning for Language Models
Mar 19, 2025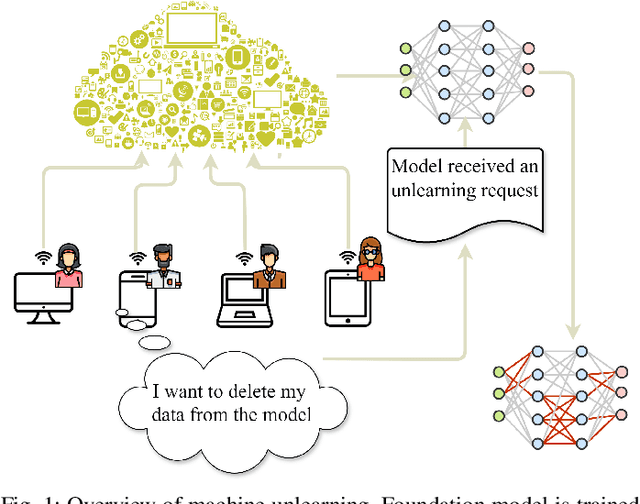
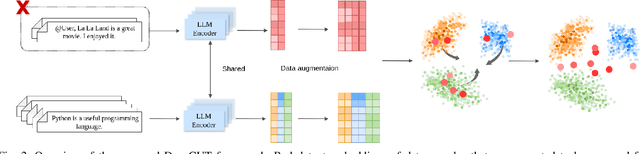
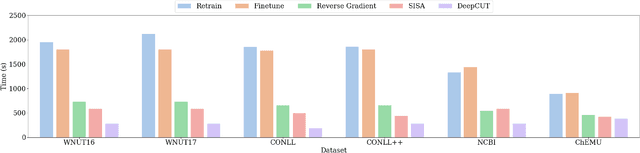
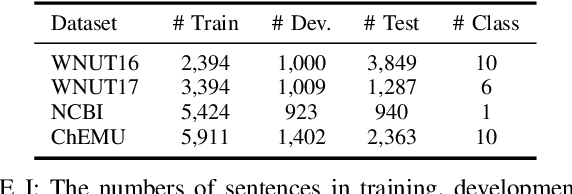
The past a few years have witnessed the great success of large language models, demonstrating powerful capabilities in comprehending textual data and generating human-like languages. Large language models achieve success by being trained on vast amounts of textual data, including online sources with copyrighted content and user-generated knowledge. However, this comes at a cost: the potential risk of exposing users' privacy and violating copyright protections. Thus, to safeguard individuals' "right to be forgotten", there has been increasing interests in machine unlearning -- the process of removing information carried by particular training samples from a model while not deteriorating its predictive quality. This is a challenging task due to the black-box nature of language models. Most existing studies focus on mitigating the impact of those forgot samples upon a model's outputs, and do not explicitly consider the geometric distributions of samples in the latent space of a model. To address this issue, we propose a machine unlearning framework, named Deep Contrastive Unlearning for fine-Tuning (DeepCUT) language models. Our proposed model achieves machine unlearning by directly optimizing the latent space of a model. Comprehensive experiments on real-world datasets demonstrate the effectiveness and efficiency of DeepCUT with consistent and significant improvement over baseline methods.
FUGNN: Harmonizing Fairness and Utility in Graph Neural Networks
May 27, 2024Fairness-aware Graph Neural Networks (GNNs) often face a challenging trade-off, where prioritizing fairness may require compromising utility. In this work, we re-examine fairness through the lens of spectral graph theory, aiming to reconcile fairness and utility within the framework of spectral graph learning. We explore the correlation between sensitive features and spectrum in GNNs, using theoretical analysis to delineate the similarity between original sensitive features and those after convolution under different spectrum. Our analysis reveals a reduction in the impact of similarity when the eigenvectors associated with the largest magnitude eigenvalue exhibit directional similarity. Based on these theoretical insights, we propose FUGNN, a novel spectral graph learning approach that harmonizes the conflict between fairness and utility. FUGNN ensures algorithmic fairness and utility by truncating the spectrum and optimizing eigenvector distribution during the encoding process. The fairness-aware eigenvector selection reduces the impact of convolution on sensitive features while concurrently minimizing the sacrifice of utility. FUGNN further optimizes the distribution of eigenvectors through a transformer architecture. By incorporating the optimized spectrum into the graph convolution network, FUGNN effectively learns node representations. Experiments on six real-world datasets demonstrate the superiority of FUGNN over baseline methods. The codes are available at https://github.com/yushuowiki/FUGNN.