 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-LLM Collaborative Feature Engineering for Tabular Data
Jan 28, 2026Large language models (LLMs) are increasingly used to automate feature engineering in tabular learning. Given task-specific information, LLMs can propose diverse feature transformation operations to enhance downstream model performance. However, current approaches typically assign the LLM as a black-box optimizer, responsible for both proposing and selecting operations based solely on its internal heuristics, which often lack calibrated estimations of operation utility and consequently lead to repeated exploration of low-yield operations without a principled strategy for prioritizing promising directions. In this paper, we propose a human-LLM collaborative feature engineering framework for tabular learning. We begin by decoupling the transformation operation proposal and selection processes, where LLMs are used solely to generate operation candidates, while the selection is guided by explicitly modeling the utility and uncertainty of each proposed operation. Since accurate utility estimation can be difficult especially in the early rounds of feature engineering, we design a mechanism within the framework that selectively elicits and incorporates human expert preference feedback, comparing which operations are more promising, into the selection process to help identify more effective operations. Our evaluations on both the synthetic study and the real user study demonstrate that the proposed framework improves feature engineering performance across a variety of tabular datasets and reduces users' cognitive load during the feature engineering process.
Learning Topic Models: Identifiability and Finite-Sample Analysis
Oct 08, 2021


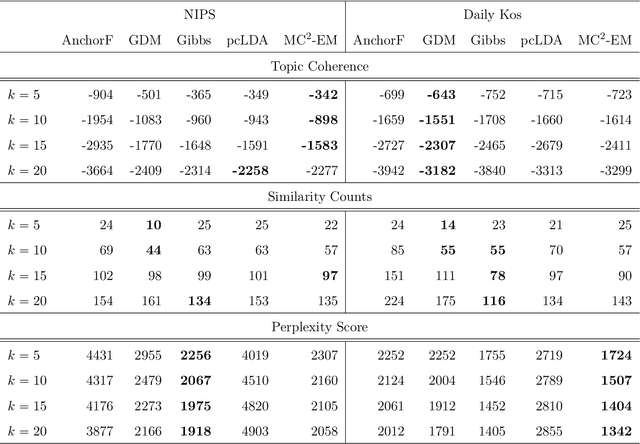
Topic models provide a useful text-mining tool for learning, extracting and discovering latent structures in large text corpora. Although a plethora of methods have been proposed for topic modeling, a formal theoretical investigation on the statistical identifiability and accuracy of latent topic estimation is lacking in the literature. In this paper, we propose a maximum likelihood estimator (MLE) of latent topics based on a specific integrated likelihood, which is naturally connected to the concept of volume minimization in computational geometry. Theoretically, we introduce a new set of geometric conditions for topic model identifiability, which are weaker than conventional separability conditions relying on the existence of anchor words or pure topic documents. We conduct finite-sample error analysis for the proposed estimator and discuss the connection of our results with existing ones. We conclude with empirical studies on both simulated and real datasets.