 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThermoSplat: Cross-Modal 3D Gaussian Splatting with Feature Modulation and Geometry Decoupling
Jan 22, 2026Multi-modal scene reconstruction integrating RGB and thermal infrared data is essential for robust environmental perception across diverse lighting and weather conditions. However, extending 3D Gaussian Splatting (3DGS) to multi-spectral scenarios remains challenging. Current approaches often struggle to fully leverage the complementary information of multi-modal data, typically relying on mechanisms that either tend to neglect cross-modal correlations or leverage shared representations that fail to adaptively handle the complex structural correlations and physical discrepancies between spectrums. To address these limitations, we propose ThermoSplat, a novel framework that enables deep spectral-aware reconstruction through active feature modulation and adaptive geometry decoupling. First, we introduce a Cross-Modal FiLM Modulation mechanism that dynamically conditions shared latent features on thermal structural priors, effectively guiding visible texture synthesis with reliable cross-modal geometric cues. Second, to accommodate modality-specific geometric inconsistencies, we propose a Modality-Adaptive Geometric Decoupling scheme that learns independent opacity offsets and executes an independent rasterization pass for the thermal branch. Additionally, a hybrid rendering pipeline is employed to integrate explicit Spherical Harmonics with implicit neural decoding, ensuring both semantic consistency and high-frequency detail preservation. Extensive experiments on the RGBT-Scenes dataset demonstrate that ThermoSplat achieves state-of-the-art rendering quality across both visible and thermal spectrums.
CineMyoPS: Segmenting Myocardial Pathologies from Cine Cardiac MR
Jul 03, 2025
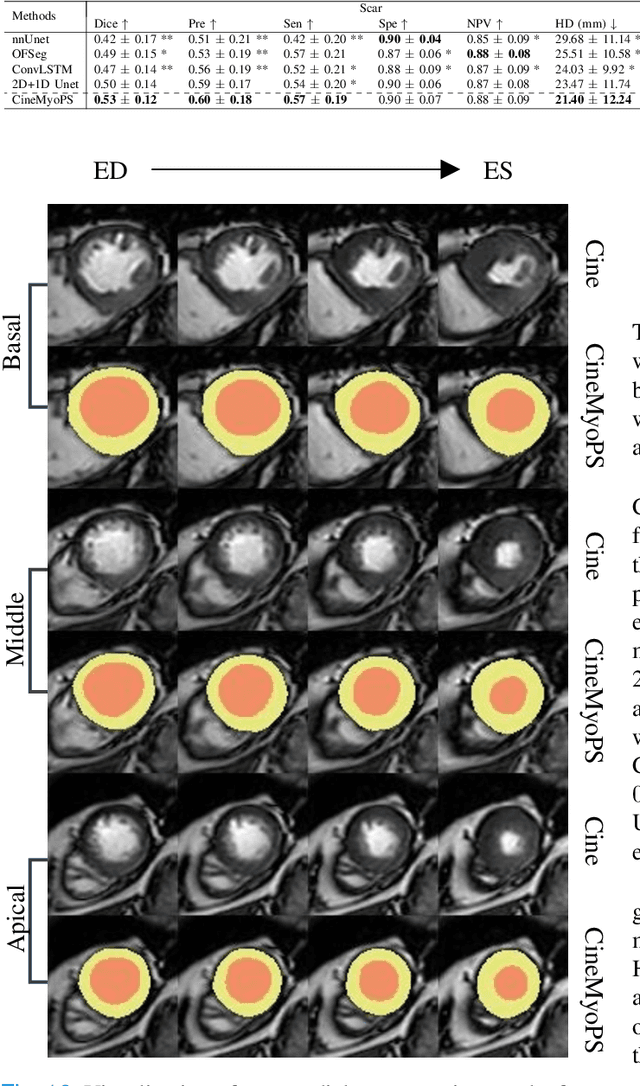


Myocardial infarction (MI) is a leading cause of death worldwide. Late gadolinium enhancement (LGE) and T2-weighted cardiac magnetic resonance (CMR) imaging can respectively identify scarring and edema areas, both of which are essential for MI risk stratification and prognosis assessment. Although combining complementary information from multi-sequence CMR is useful, acquiring these sequences can be time-consuming and prohibitive, e.g., due to the administration of contrast agents. Cine CMR is a rapid and contrast-free imaging technique that can visualize both motion and structural abnormalities of the myocardium induced by acute MI. Therefore, we present a new end-to-end deep neural network, referred to as CineMyoPS, to segment myocardial pathologies, \ie scars and edema, solely from cine CMR images. Specifically, CineMyoPS extracts both motion and anatomy features associated with MI. Given the interdependence between these features, we design a consistency loss (resembling the co-training strategy) to facilitate their joint learning. Furthermore, we propose a time-series aggregation strategy to integrate MI-related features across the cardiac cycle, thereby enhancing segmentation accuracy for myocardial pathologies. Experimental results on a multi-center dataset demonstrate that CineMyoPS achieves promising performance in myocardial pathology segmentation, motion estimation, and anatomy segmentation.
Aligning Multi-Sequence CMR Towards Fully Automated Myocardial Pathology Segmentation
Feb 07, 2023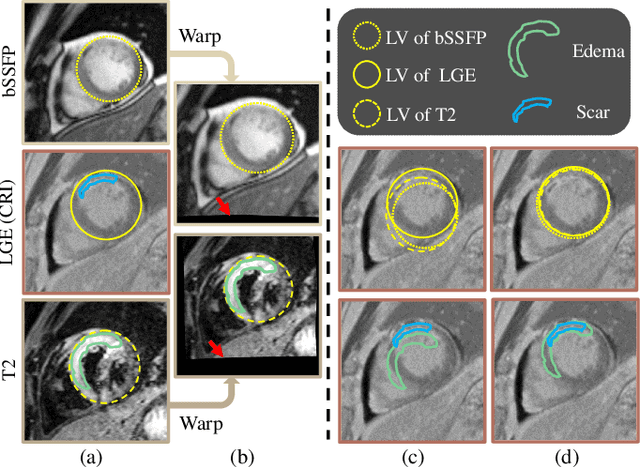
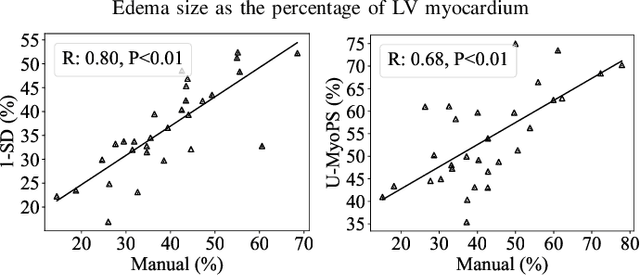
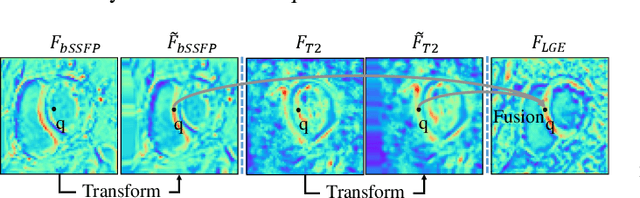
Myocardial pathology segmentation (MyoPS) is critical for the risk stratification and treatment planning of myocardial infarction (MI). Multi-sequence cardiac magnetic resonance (MS-CMR) images can provide valuable information. For instance, balanced steady-state free precession cine sequences present clear anatomical boundaries, while late gadolinium enhancement and T2-weighted CMR sequences visualize myocardial scar and edema of MI, respectively. Existing methods usually fuse anatomical and pathological information from different CMR sequences for MyoPS, but assume that these images have been spatially aligned. However, MS-CMR images are usually unaligned due to the respiratory motions in clinical practices, which poses additional challenges for MyoPS. This work presents an automatic MyoPS framework for unaligned MS-CMR images. Specifically, we design a combined computing model for simultaneous image registration and information fusion, which aggregates multi-sequence features into a common space to extract anatomical structures (i.e., myocardium). Consequently, we can highlight the informative regions in the common space via the extracted myocardium to improve MyoPS performance, considering the spatial relationship between myocardial pathologies and myocardium. Experiments on a private MS-CMR dataset and a public dataset from the MYOPS2020 challenge show that our framework could achieve promising performance for fully automatic MyoPS.
Multi-Depth Boundary-Aware Left Atrial Scar Segmentation Network
Aug 08, 2022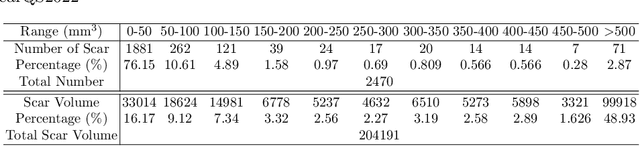
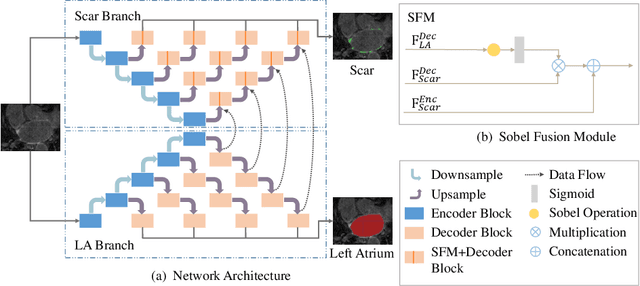
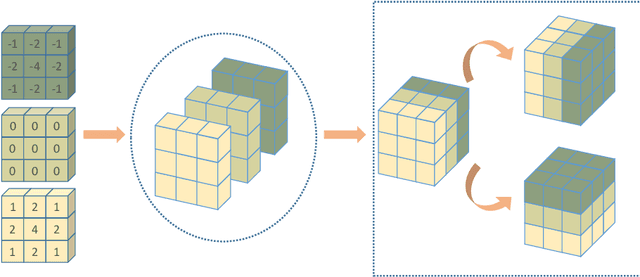

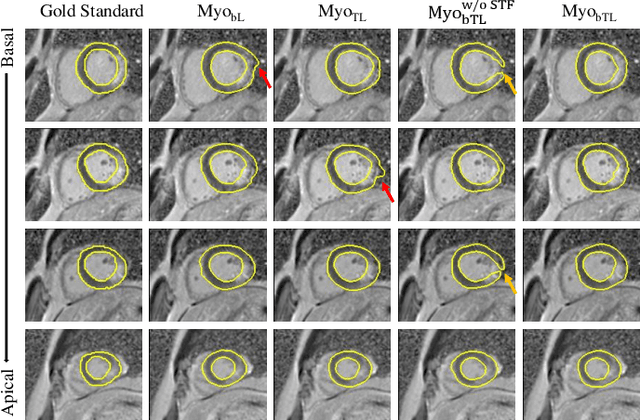
Automatic segmentation of left atrial (LA) scars from late gadolinium enhanced CMR images is a crucial step for atrial fibrillation (AF) recurrence analysis. However, delineating LA scars is tedious and error-prone due to the variation of scar shapes. In this work, we propose a boundary-aware LA scar segmentation network, which is composed of two branches to segment LA and LA scars, respectively. We explore the inherent spatial relationship between LA and LA scars. By introducing a Sobel fusion module between the two segmentation branches, the spatial information of LA boundaries can be propagated from the LA branch to the scar branch. Thus, LA scar segmentation can be performed condition on the LA boundaries regions. In our experiments, 40 labeled images were used to train the proposed network, and the remaining 20 labeled images were used for evaluation. The network achieved an average Dice score of 0.608 for LA scar segmentation.
Cross-Modality Multi-Atlas Segmentation Using Deep Neural Networks
Feb 04, 2022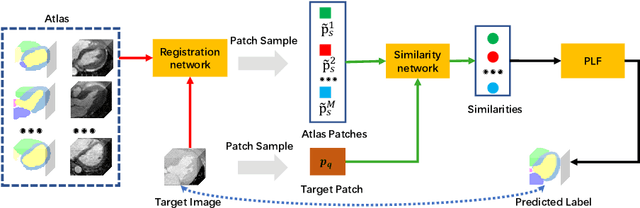
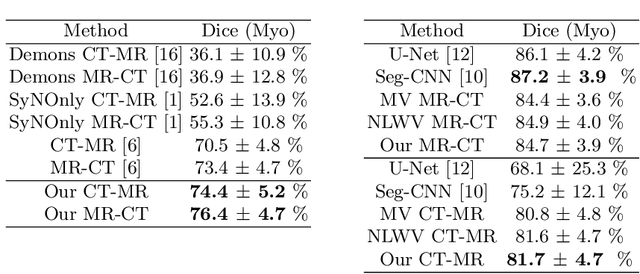
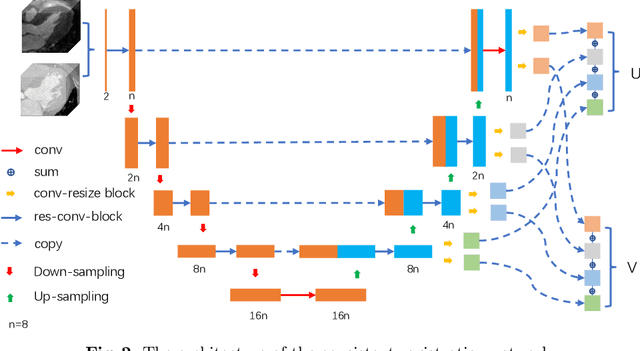
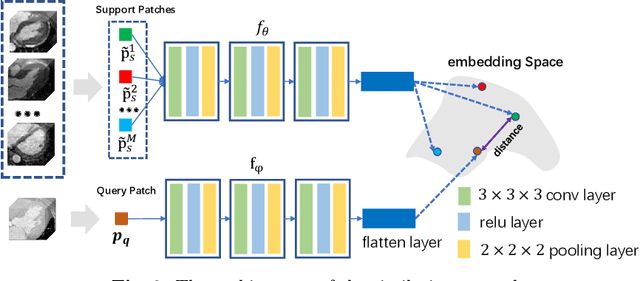
Multi-atlas segmentation (MAS) is a promising framework for medical image segmentation. Generally, MAS methods register multiple atlases, i.e., medical images with corresponding labels, to a target image; and the transformed atlas labels can be combined to generate target segmentation via label fusion schemes. Many conventional MAS methods employed the atlases from the same modality as the target image. However, the number of atlases with the same modality may be limited or even missing in many clinical applications. Besides, conventional MAS methods suffer from the computational burden of registration or label fusion procedures. In this work, we design a novel cross-modality MAS framework, which uses available atlases from a certain modality to segment a target image from another modality. To boost the computational efficiency of the framework, both the image registration and label fusion are achieved by well-designed deep neural networks. For the atlas-to-target image registration, we propose a bi-directional registration network (BiRegNet), which can efficiently align images from different modalities. For the label fusion, we design a similarity estimation network (SimNet), which estimates the fusion weight of each atlas by measuring its similarity to the target image. SimNet can learn multi-scale information for similarity estimation to improve the performance of label fusion. The proposed framework was evaluated by the left ventricle and liver segmentation tasks on the MM-WHS and CHAOS datasets, respectively. Results have shown that the framework is effective for cross-modality MAS in both registration and label fusion. The code will be released publicly on \url{https://github.com/NanYoMy/cmmas} once the manuscript is accepted.
Unsupervised MMRegNet based on Spatially Encoded Gradient Information
May 16, 2021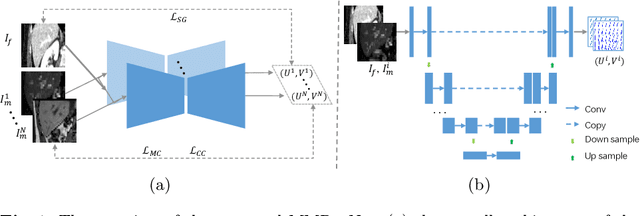
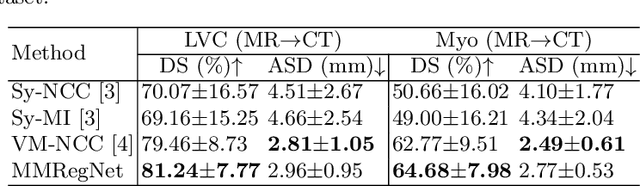
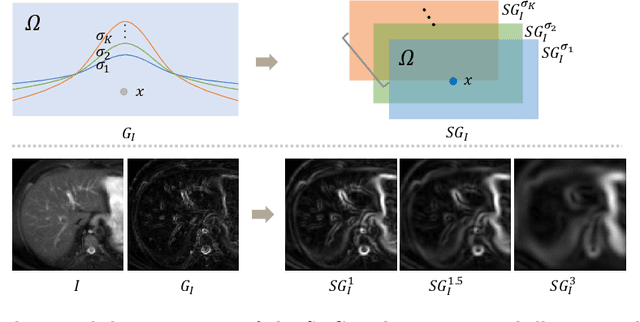
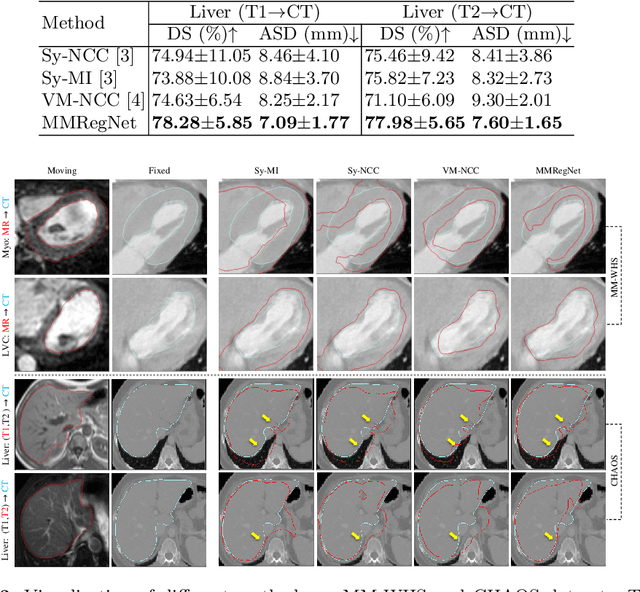
Multi-modality medical images can provide relevant and complementary anatomical information for a target (organ, tumor or tissue). Registering the multi-modality images to a common space can fuse these comprehensive information, and bring convenience for clinical application. Recently, neural networks have been widely investigated to boost registration methods. However, it is still challenging to develop a multi-modality registration network due to the lack of robust criteria for network training. Besides, most existing registration networks mainly focus on pairwise registration, and can hardly be applicable for multiple image scenarios. In this work, we propose a multi-modality registration network (MMRegNet), which can jointly register multiple images with different modalities to a target image. Meanwhile, we present spatially encoded gradient information to train the MMRegNet in an unsupervised manner. The proposed network was evaluated on two datasets, i.e, MM-WHS 2017 and CHAOS 2019. The results show that the proposed network can achieve promising performance for cardiac left ventricle and liver registration tasks. Source code is released publicly on github.
Automatic Pulmonary Artery and Vein Separation Algorithm Based on Multitask Classification Network and Topology Reconstruction in Chest CT Images
Mar 22, 2021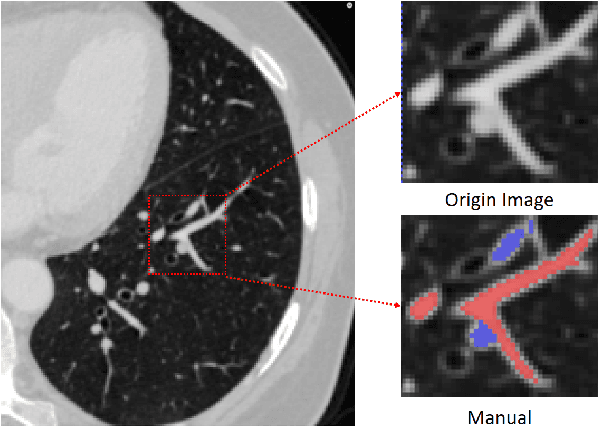
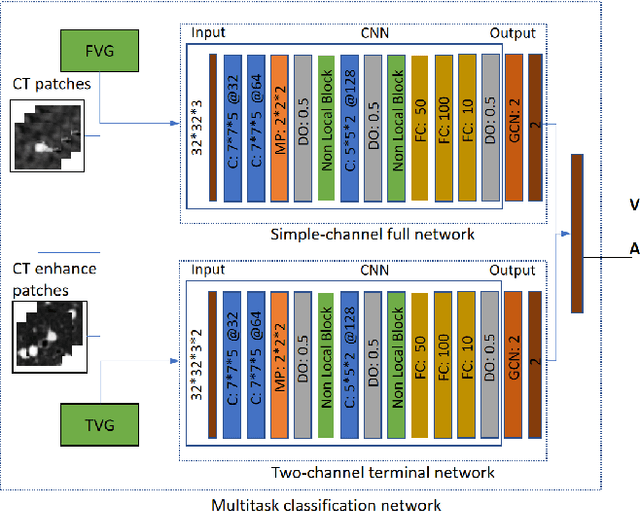
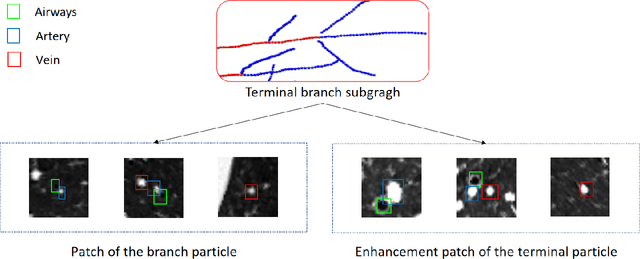
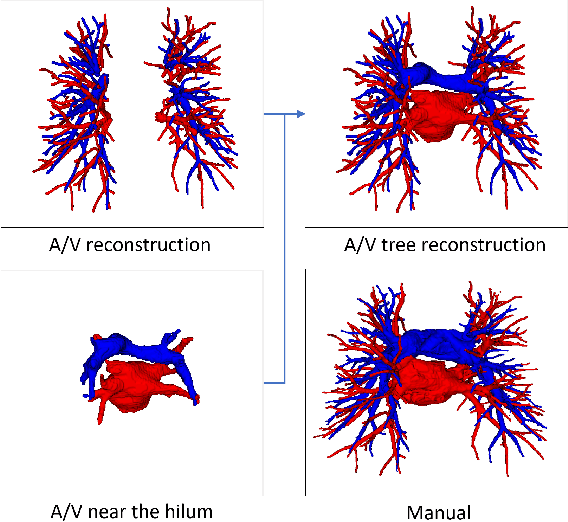
With the development of medical computer-aided diagnostic systems, pulmonary artery-vein(A/V) reconstruction plays a crucial role in assisting doctors in preoperative planning for lung cancer surgery. However, distinguishing arterial from venous irrigation in chest CT images remains a challenge due to the similarity and complex structure of the arteries and veins. We propose a novel method for automatic separation of pulmonary arteries and veins from chest CT images. The method consists of three parts. First, global connection information and local feature information are used to construct a complete topological tree and ensure the continuity of vessel reconstruction. Second, the multitask classification network proposed can automatically learn the differences between arteries and veins at different scales to reduce classification errors caused by changes in terminal vessel characteristics. Finally, the topology optimizer considers interbranch and intrabranch topological relationships to maintain spatial consistency to avoid the misclassification of A/V irrigations. We validate the performance of the method on chest CT images. Compared with manual classification, the proposed method achieves an average accuracy of 96.2% on noncontrast chest CT. In addition, the method has been proven to have good generalization, that is, the accuracies of 93.8% and 94.8% are obtained for CT scans from other devices and other modes, respectively. The result of pulmonary artery-vein reconstruction obtained by the proposed method can provide better assistance for preoperative planning of lung cancer surgery.
Coarse-to-fine Airway Segmentation Using Multi information Fusion Network and CNN-based Region Growing
Feb 25, 2021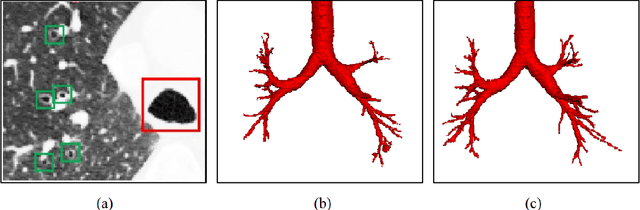
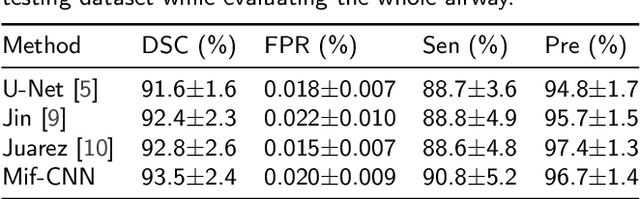
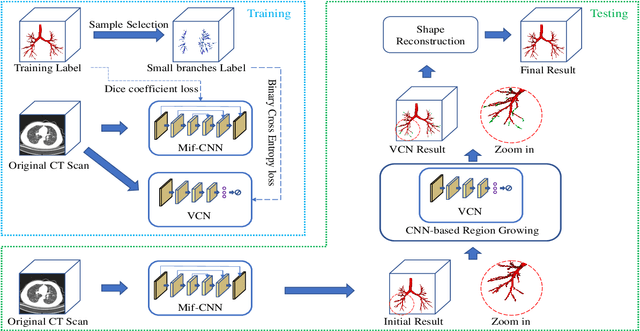
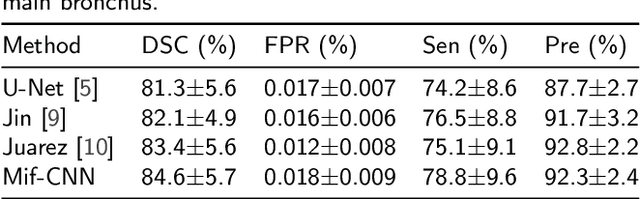
Automatic airway segmentation from chest computed tomography (CT) scans plays an important role in pulmonary disease diagnosis and computer-assisted therapy. However, low contrast at peripheral branches and complex tree-like structures remain as two mainly challenges for airway segmentation. Recent research has illustrated that deep learning methods perform well in segmentation tasks. Motivated by these works, a coarse-to-fine segmentation framework is proposed to obtain a complete airway tree. Our framework segments the overall airway and small branches via the multi-information fusion convolution neural network (Mif-CNN) and the CNN-based region growing, respectively. In Mif-CNN, atrous spatial pyramid pooling (ASPP) is integrated into a u-shaped network, and it can expend the receptive field and capture multi-scale information. Meanwhile, boundary and location information are incorporated into semantic information. These information are fused to help Mif-CNN utilize additional context knowledge and useful features. To improve the performance of the segmentation result, the CNN-based region growing method is designed to focus on obtaining small branches. A voxel classification network (VCN), which can entirely capture the rich information around each voxel, is applied to classify the voxels into airway and non-airway. In addition, a shape reconstruction method is used to refine the airway tree.
Interpretative Computer-aided Lung Cancer Diagnosis: from Radiology Analysis to Malignancy Evaluation
Feb 22, 2021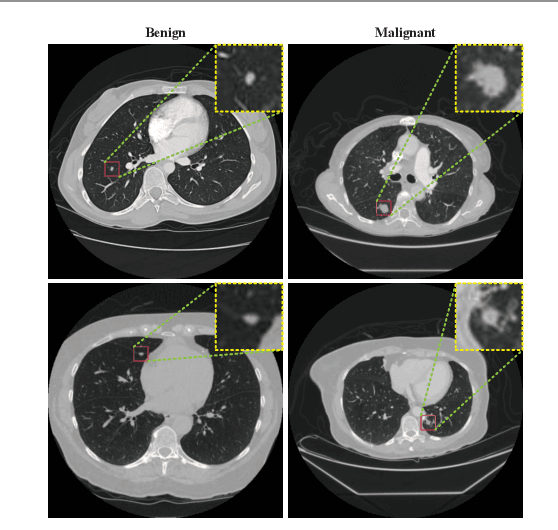
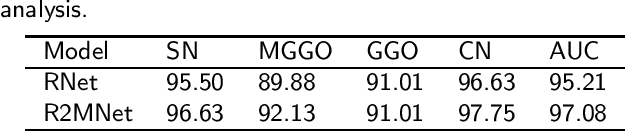
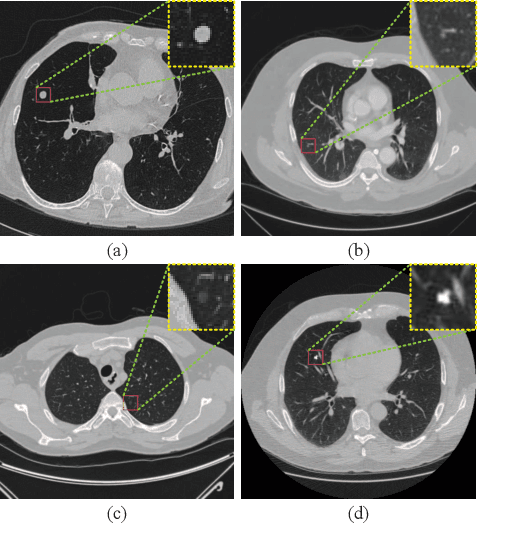

Background and Objective:Computer-aided diagnosis (CAD) systems promote diagnosis effectiveness and alleviate pressure of radiologists. A CAD system for lung cancer diagnosis includes nodule candidate detection and nodule malignancy evaluation. Recently, deep learning-based pulmonary nodule detection has reached satisfactory performance ready for clinical application. However, deep learning-based nodule malignancy evaluation depends on heuristic inference from low-dose computed tomography volume to malignant probability, which lacks clinical cognition. Methods:In this paper, we propose a joint radiology analysis and malignancy evaluation network (R2MNet) to evaluate the pulmonary nodule malignancy via radiology characteristics analysis. Radiological features are extracted as channel descriptor to highlight specific regions of the input volume that are critical for nodule malignancy evaluation. In addition, for model explanations, we propose channel-dependent activation mapping to visualize the features and shed light on the decision process of deep neural network. Results:Experimental results on the LIDC-IDRI dataset demonstrate that the proposed method achieved area under curve of 96.27% on nodule radiology analysis and AUC of 97.52% on nodule malignancy evaluation. In addition, explanations of CDAM features proved that the shape and density of nodule regions were two critical factors that influence a nodule to be inferred as malignant, which conforms with the diagnosis cognition of experienced radiologists. Conclusion:Incorporating radiology analysis with nodule malignant evaluation, the network inference process conforms to the diagnostic procedure of radiologists and increases the confidence of evaluation results. Besides, model interpretation with CDAM features shed light on the regions which DNNs focus on when they estimate nodule malignancy probabilities.
Brain Tumor Segmentation Network Using Attention-based Fusion and Spatial Relationship Constraint
Oct 31, 2020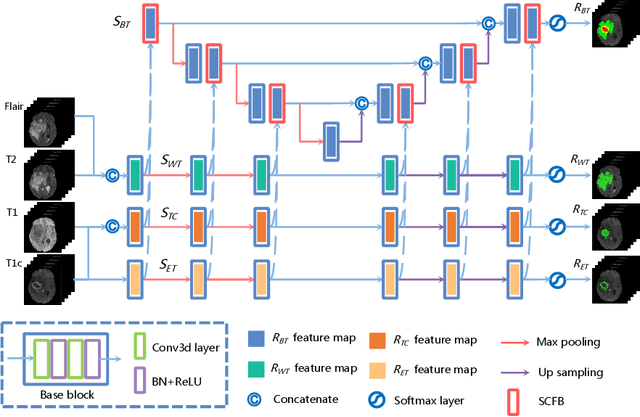
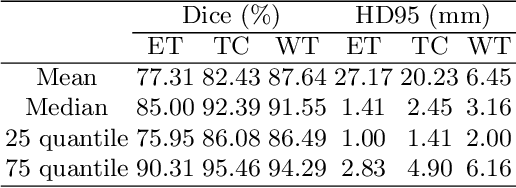
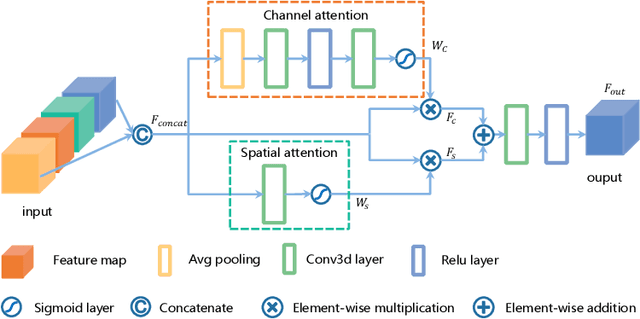
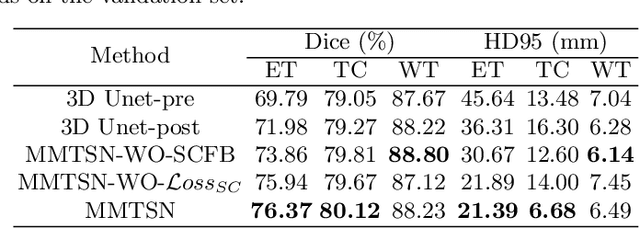
Delineating the brain tumor from magnetic resonance (MR) images is critical for the treatment of gliomas. However, automatic delineation is challenging due to the complex appearance and ambiguous outlines of tumors. Considering that multi-modal MR images can reflect different tumor biological properties, we develop a novel multi-modal tumor segmentation network (MMTSN) to robustly segment brain tumors based on multi-modal MR images. The MMTSN is composed of three sub-branches and a main branch. Specifically, the sub-branches are used to capture different tumor features from multi-modal images, while in the main branch, we design a spatial-channel fusion block (SCFB) to effectively aggregate multi-modal features. Additionally, inspired by the fact that the spatial relationship between sub-regions of tumor is relatively fixed, e.g., the enhancing tumor is always in the tumor core, we propose a spatial loss to constrain the relationship between different sub-regions of tumor. We evaluate our method on the test set of multi-modal brain tumor segmentation challenge 2020 (BraTs2020). The method achieves 0.8764, 0.8243 and 0.773 dice score for whole tumor, tumor core and enhancing tumor, respectively.