 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSGCoOp: Multiple Semantic-Guided Context Optimization for Few-Shot Learning
Jul 29, 2025



Vision-language pre-trained models (VLMs) such as CLIP have demonstrated remarkable zero-shot generalization, and prompt learning has emerged as an efficient alternative to full fine-tuning. However, existing methods often struggle with generalization to novel classes, a phenomenon attributed to overfitting on seen classes and forgetting general knowledge. Furthermore, recent approaches that improve generalization often introduce complex architectures or heavy computational overhead. In this paper, we propose a Multiple Semantic-Guided Context Optimization (MSGCoOp) framework to enhance few-shot generalization while maintaining computational efficiency. Our approach leverages an ensemble of parallel learnable context vectors to capture diverse semantic aspects. To enrich these prompts, we introduce a semantic guidance mechanism that aligns them with comprehensive class descriptions automatically generated by a Large Language Model (LLM). Furthermore, a diversity regularization loss encourages the prompts to learn complementary and orthogonal features, preventing them from collapsing into redundant representations. Extensive experiments on 11 benchmark datasets show that MSGCoOp significantly improves performance on base-to-novel generalization, achieving an average harmonic mean improvement of 1.10\% over the strong KgCoOp baseline. Our method also demonstrates enhanced robustness in cross-domain generalization tasks. Our code is avaliable at: \href{https://github.com/Rain-Bus/MSGCoOp}{https://github.com/Rain-Bus/MSGCoOp}.
Learning from Concealed Labels
Dec 03, 2024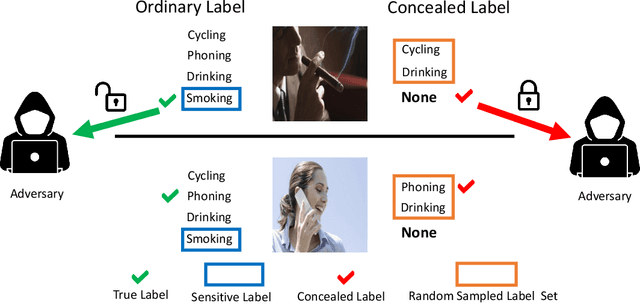
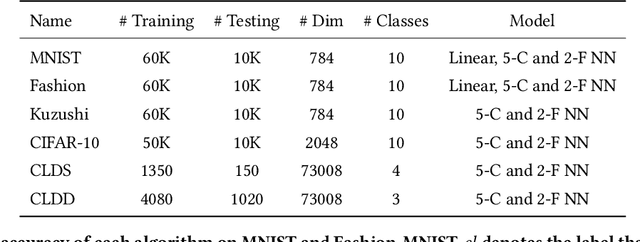

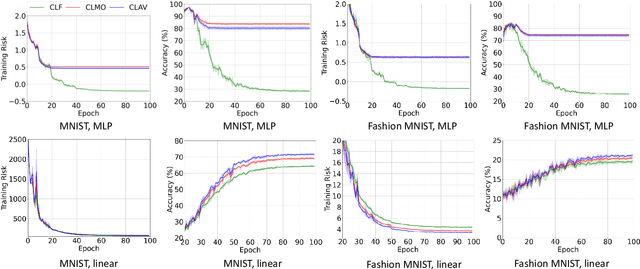
Annotating data for sensitive labels (e.g., disease, smoking) poses a potential threats to individual privacy in many real-world scenarios. To cope with this problem, we propose a novel setting to protect privacy of each instance, namely learning from concealed labels for multi-class classification. Concealed labels prevent sensitive labels from appearing in the label set during the label collection stage, which specifies none and some random sampled insensitive labels as concealed labels set to annotate sensitive data. In this paper, an unbiased estimator can be established from concealed data under mild assumptions, and the learned multi-class classifier can not only classify the instance from insensitive labels accurately but also recognize the instance from the sensitive labels. Moreover, we bound the estimation error and show that the multi-class classifier achieves the optimal parametric convergence rate. Experiments demonstrate the significance and effectiveness of the proposed method for concealed labels in synthetic and real-world datasets.
Learning from True-False Labels via Multi-modal Prompt Retrieving
May 24, 2024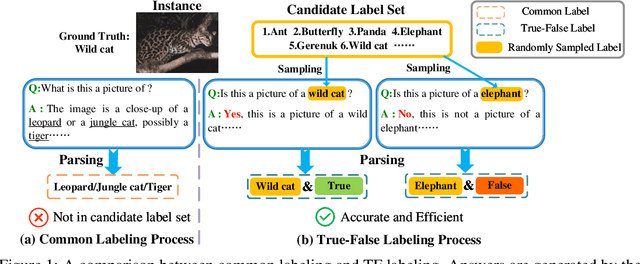

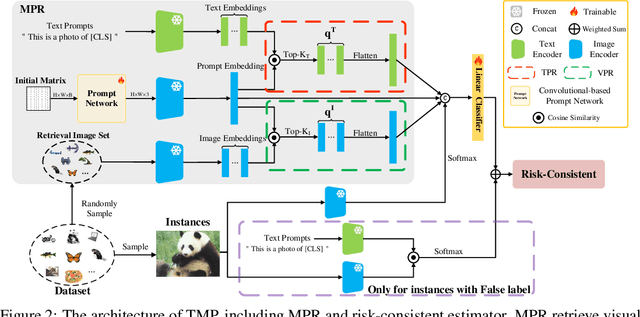

Weakly supervised learning has recently achieved considerable success in reducing annotation costs and label noise. Unfortunately, existing weakly supervised learning methods are short of ability in generating reliable labels via pre-trained vision-language models (VLMs). In this paper, we propose a novel weakly supervised labeling setting, namely True-False Labels (TFLs) which can achieve high accuracy when generated by VLMs. The TFL indicates whether an instance belongs to the label, which is randomly and uniformly sampled from the candidate label set. Specifically, we theoretically derive a risk-consistent estimator to explore and utilize the conditional probability distribution information of TFLs. Besides, we propose a convolutional-based Multi-modal Prompt Retrieving (MRP) method to bridge the gap between the knowledge of VLMs and target learning tasks. Experimental results demonstrate the effectiveness of the proposed TFL setting and MRP learning method. The code to reproduce the experiments is at https://github.com/Tranquilxu/TMP.
Multi-label Learning from Privacy-Label
Dec 20, 2023Multi-abel Learning (MLL) often involves the assignment of multiple relevant labels to each instance, which can lead to the leakage of sensitive information (such as smoking, diseases, etc.) about the instances. However, existing MLL suffer from failures in protection for sensitive information. In this paper, we propose a novel setting named Multi-Label Learning from Privacy-Label (MLLPL), which Concealing Labels via Privacy-Label Unit (CLPLU). Specifically, during the labeling phase, each privacy-label is randomly combined with a non-privacy label to form a Privacy-Label Unit (PLU). If any label within a PLU is positive, the unit is labeled as positive; otherwise, it is labeled negative, as shown in Figure 1. PLU ensures that only non-privacy labels are appear in the label set, while the privacy-labels remain concealed. Moreover, we further propose a Privacy-Label Unit Loss (PLUL) to learn the optimal classifier by minimizing the empirical risk of PLU. Experimental results on multiple benchmark datasets demonstrate the effectiveness and superiority of the proposed method.
Learning from Positive and Unlabeled Data with Augmented Classes
Jul 27, 2022
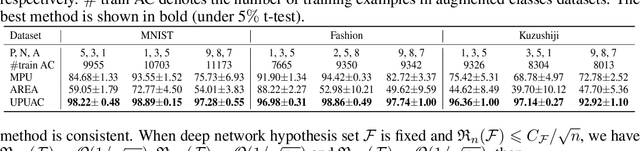
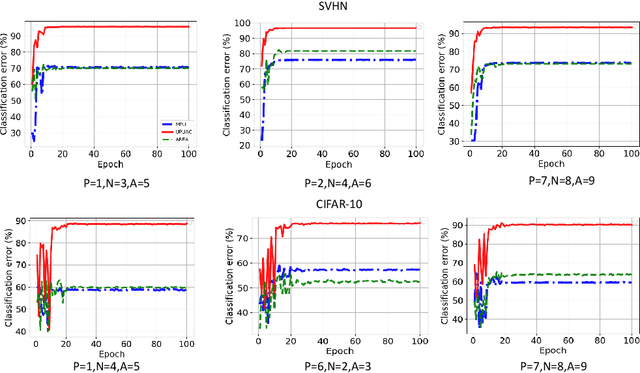
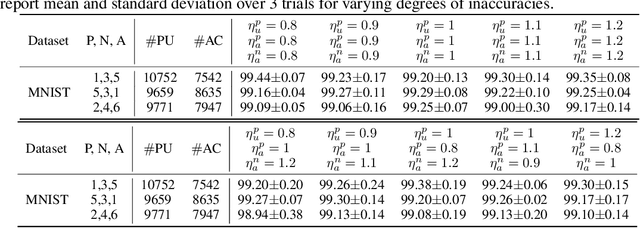
Positive Unlabeled (PU) learning aims to learn a binary classifier from only positive and unlabeled data, which is utilized in many real-world scenarios. However, existing PU learning algorithms cannot deal with the real-world challenge in an open and changing scenario, where examples from unobserved augmented classes may emerge in the testing phase. In this paper, we propose an unbiased risk estimator for PU learning with Augmented Classes (PUAC) by utilizing unlabeled data from the augmented classes distribution, which can be easily collected in many real-world scenarios. Besides, we derive the estimation error bound for the proposed estimator, which provides a theoretical guarantee for its convergence to the optimal solution. Experiments on multiple realistic datasets demonstrate the effectiveness of proposed approach.