 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSNet: Parallel Symmetric Network for Video Salient Object Detection
Oct 12, 2022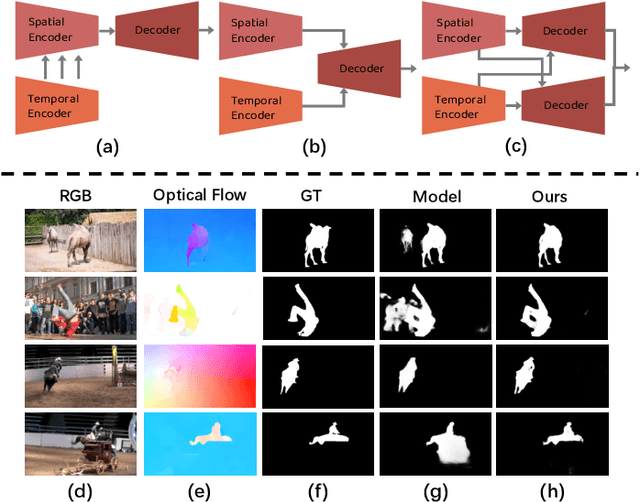
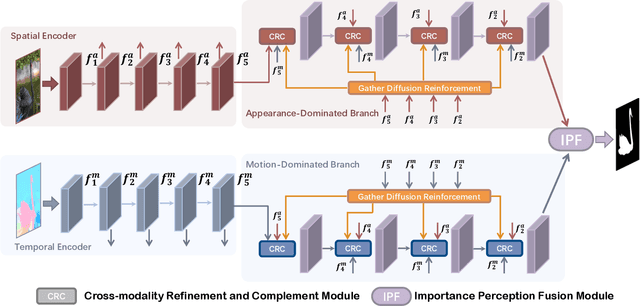
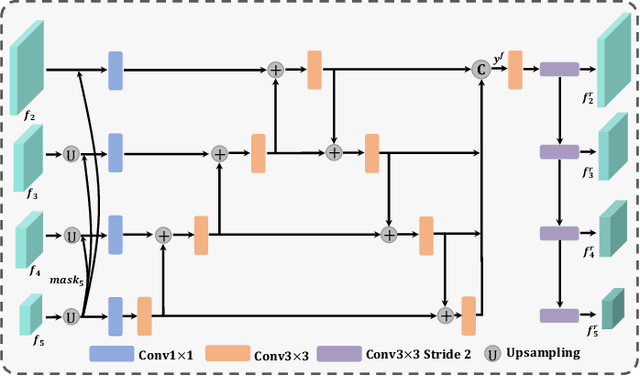
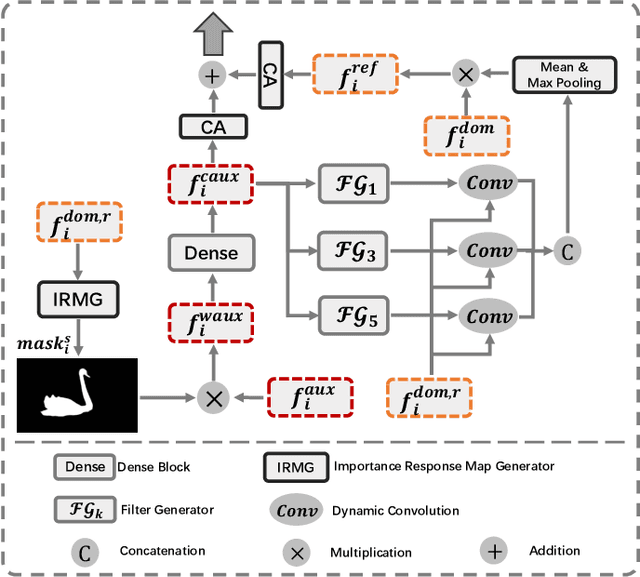
For the video salient object detection (VSOD) task, how to excavate the information from the appearance modality and the motion modality has always been a topic of great concern. The two-stream structure, including an RGB appearance stream and an optical flow motion stream, has been widely used as a typical pipeline for VSOD tasks, but the existing methods usually only use motion features to unidirectionally guide appearance features or adaptively but blindly fuse two modality features. However, these methods underperform in diverse scenarios due to the uncomprehensive and unspecific learning schemes. In this paper, following a more secure modeling philosophy, we deeply investigate the importance of appearance modality and motion modality in a more comprehensive way and propose a VSOD network with up and down parallel symmetry, named PSNet. Two parallel branches with different dominant modalities are set to achieve complete video saliency decoding with the cooperation of the Gather Diffusion Reinforcement (GDR) module and Cross-modality Refinement and Complement (CRC) module. Finally, we use the Importance Perception Fusion (IPF) module to fuse the features from two parallel branches according to their different importance in different scenarios. Experiments on four dataset benchmarks demonstrate that our method achieves desirable and competitive performance.