 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuper-resolving Compressed Images via Parallel and Series Integration of Artifact Reduction and Resolution Enhancement
Mar 04, 2021



In this paper, we propose a novel compressed image super resolution (CISR) framework based on parallel and series integration of artifact removal and resolution enhancement. Based on maximum a posterior inference for estimating a clean low-resolution (LR) input image and a clean high resolution (HR) output image from down-sampled and compressed observations, we have designed a CISR architecture consisting of two deep neural network modules: the artifact reduction module (ARM) and resolution enhancement module (REM). ARM and REM work in parallel with both taking the compressed LR image as their inputs, while they also work in series with REM taking the output of ARM as one of its inputs and ARM taking the output of REM as its other input. A unique property of our CSIR system is that a single trained model is able to super-resolve LR images compressed by different methods to various qualities. This is achieved by exploiting deep neural net-works capacity for handling image degradations, and the parallel and series connections between ARM and REM to reduce the dependency on specific degradations. ARM and REM are trained simultaneously by the deep unfolding technique. Experiments are conducted on a mixture of JPEG and WebP compressed images without a priori knowledge of the compression type and com-pression factor. Visual and quantitative comparisons demonstrate the superiority of our method over state-of-the-art super resolu-tion methods.Code link: https://github.com/luohongming/CISR_PSI
VHS to HDTV Video Translation using Multi-task Adversarial Learning
Jan 07, 2021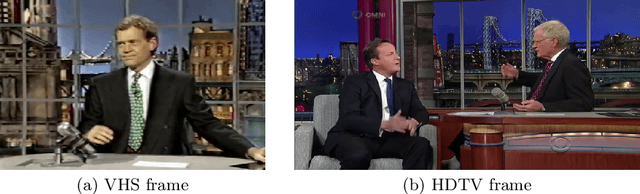

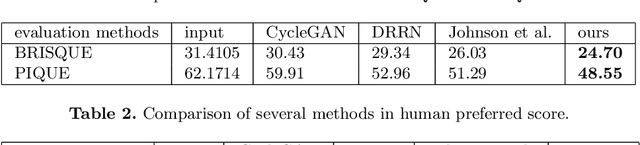
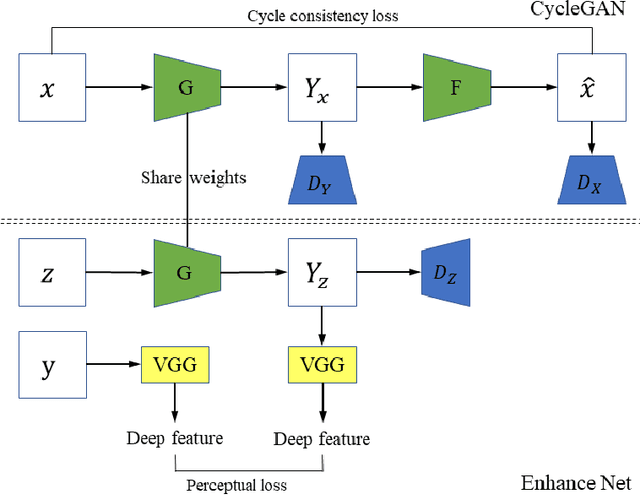
There are large amount of valuable video archives in Video Home System (VHS) format. However, due to the analog nature, their quality is often poor. Compared to High-definition television (HDTV), VHS video not only has a dull color appearance but also has a lower resolution and often appears blurry. In this paper, we focus on the problem of translating VHS video to HDTV video and have developed a solution based on a novel unsupervised multi-task adversarial learning model. Inspired by the success of generative adversarial network (GAN) and CycleGAN, we employ cycle consistency loss, adversarial loss and perceptual loss together to learn a translation model. An important innovation of our work is the incorporation of super-resolution model and color transfer model that can solve unsupervised multi-task problem. To our knowledge, this is the first work that dedicated to the study of the relation between VHS and HDTV and the first computational solution to translate VHS to HDTV. We present experimental results to demonstrate the effectiveness of our solution qualitatively and quantitatively.