 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Question Answering via only 2D Vision-Language Models
May 28, 2025Large vision-language models (LVLMs) have significantly advanced numerous fields. In this work, we explore how to harness their potential to address 3D scene understanding tasks, using 3D question answering (3D-QA) as a representative example. Due to the limited training data in 3D, we do not train LVLMs but infer in a zero-shot manner. Specifically, we sample 2D views from a 3D point cloud and feed them into 2D models to answer a given question. When the 2D model is chosen, e.g., LLAVA-OV, the quality of sampled views matters the most. We propose cdViews, a novel approach to automatically selecting critical and diverse Views for 3D-QA. cdViews consists of two key components: viewSelector prioritizing critical views based on their potential to provide answer-specific information, and viewNMS enhancing diversity by removing redundant views based on spatial overlap. We evaluate cdViews on the widely-used ScanQA and SQA benchmarks, demonstrating that it achieves state-of-the-art performance in 3D-QA while relying solely on 2D models without fine-tuning. These findings support our belief that 2D LVLMs are currently the most effective alternative (of the resource-intensive 3D LVLMs) for addressing 3D tasks.
Unleashing Network Potentials for Semantic Scene Completion
Mar 14, 2024



Semantic scene completion (SSC) aims to predict complete 3D voxel occupancy and semantics from a single-view RGB-D image, and recent SSC methods commonly adopt multi-modal inputs. However, our investigation reveals two limitations: ineffective feature learning from single modalities and overfitting to limited datasets. To address these issues, this paper proposes a novel SSC framework - Adversarial Modality Modulation Network (AMMNet) - with a fresh perspective of optimizing gradient updates. The proposed AMMNet introduces two core modules: a cross-modal modulation enabling the interdependence of gradient flows between modalities, and a customized adversarial training scheme leveraging dynamic gradient competition. Specifically, the cross-modal modulation adaptively re-calibrates the features to better excite representation potentials from each single modality. The adversarial training employs a minimax game of evolving gradients, with customized guidance to strengthen the generator's perception of visual fidelity from both geometric completeness and semantic correctness. Extensive experimental results demonstrate that AMMNet outperforms state-of-the-art SSC methods by a large margin, providing a promising direction for improving the effectiveness and generalization of SSC methods.
Semantic Scene Completion with Cleaner Self
Mar 17, 2023

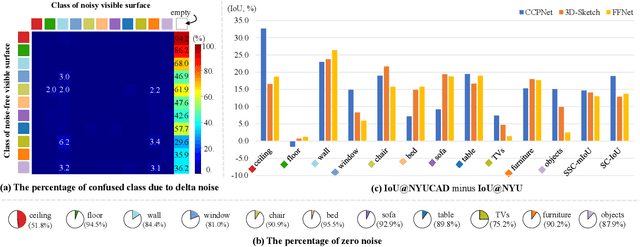
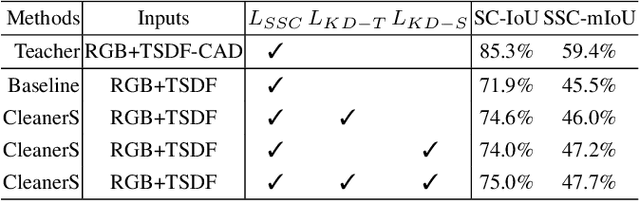
Semantic Scene Completion (SSC) transforms an image of single-view depth and/or RGB 2D pixels into 3D voxels, each of whose semantic labels are predicted. SSC is a well-known ill-posed problem as the prediction model has to "imagine" what is behind the visible surface, which is usually represented by Truncated Signed Distance Function (TSDF). Due to the sensory imperfection of the depth camera, most existing methods based on the noisy TSDF estimated from depth values suffer from 1) incomplete volumetric predictions and 2) confused semantic labels. To this end, we use the ground-truth 3D voxels to generate a perfect visible surface, called TSDF-CAD, and then train a "cleaner" SSC model. As the model is noise-free, it is expected to focus more on the "imagination" of unseen voxels. Then, we propose to distill the intermediate "cleaner" knowledge into another model with noisy TSDF input. In particular, we use the 3D occupancy feature and the semantic relations of the "cleaner self" to supervise the counterparts of the "noisy self" to respectively address the above two incorrect predictions. Experimental results validate that our method improves the noisy counterparts with 3.1% IoU and 2.2% mIoU for measuring scene completion and SSC, and also achieves new state-of-the-art accuracy on the popular NYU dataset.