 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Activation, Refinement, and Aggregation: Exploring Diverse Cues for Fine-Grained Bird Recognition
Paper and Code
Apr 12, 2025
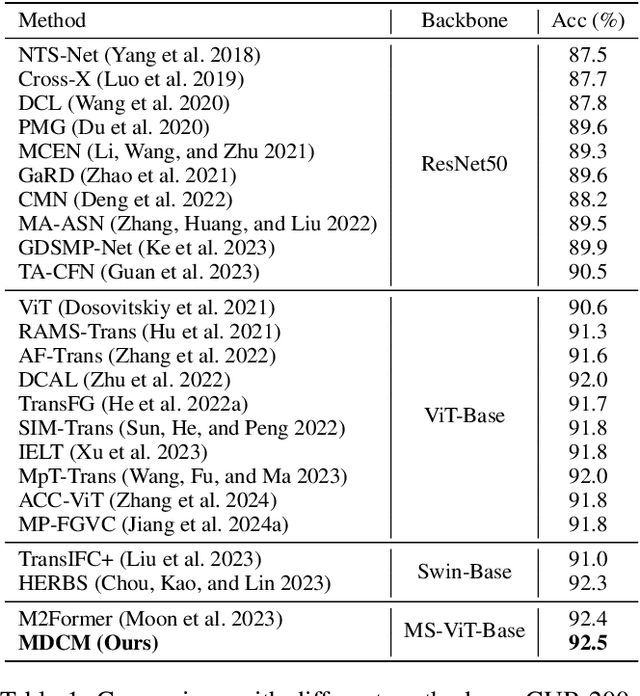
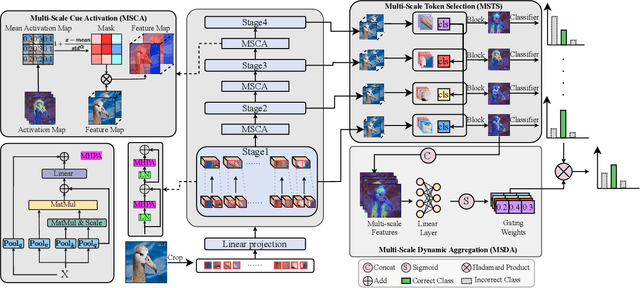
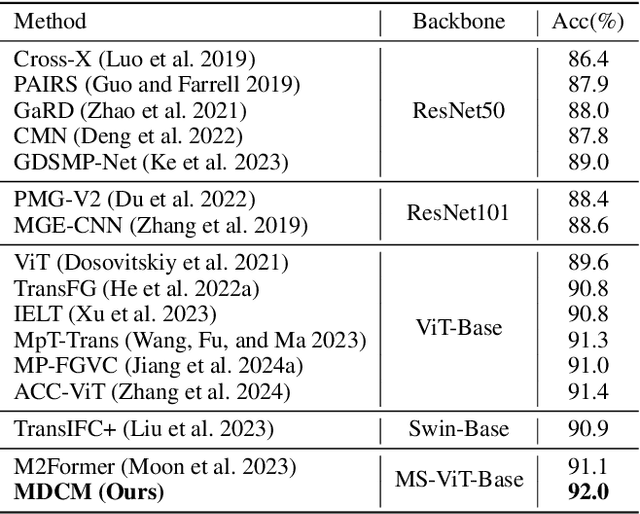
Given the critical role of birds in ecosystems, Fine-Grained Bird Recognition (FGBR) has gained increasing attention, particularly in distinguishing birds within similar subcategories. Although Vision Transformer (ViT)-based methods often outperform Convolutional Neural Network (CNN)-based methods in FGBR, recent studies reveal that the limited receptive field of plain ViT model hinders representational richness and makes them vulnerable to scale variance. Thus, enhancing the multi-scale capabilities of existing ViT-based models to overcome this bottleneck in FGBR is a worthwhile pursuit. In this paper, we propose a novel framework for FGBR, namely Multi-scale Diverse Cues Modeling (MDCM), which explores diverse cues at different scales across various stages of a multi-scale Vision Transformer (MS-ViT) in an "Activation-Selection-Aggregation" paradigm. Specifically, we first propose a multi-scale cue activation module to ensure the discriminative cues learned at different stage are mutually different. Subsequently, a multi-scale token selection mechanism is proposed to remove redundant noise and highlight discriminative, scale-specific cues at each stage. Finally, the selected tokens from each stage are independently utilized for bird recognition, and the recognition results from multiple stages are adaptively fused through a multi-scale dynamic aggregation mechanism for final model decisions. Both qualitative and quantitative results demonstrate the effectiveness of our proposed MDCM, which outperforms CNN- and ViT-based models on several widely-used FGBR benchmarks.