 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-guided Cross-modal Completion and Alignment for Incomplete Text-based Person Re-identification
Oct 03, 2023
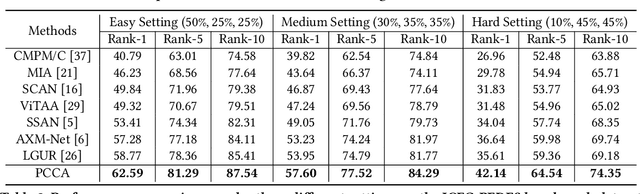

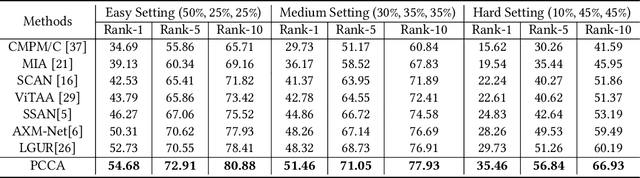
Traditional text-based person re-identification (ReID) techniques heavily rely on fully matched multi-modal data, which is an ideal scenario. However, due to inevitable data missing and corruption during the collection and processing of cross-modal data, the incomplete data issue is usually met in real-world applications. Therefore, we consider a more practical task termed the incomplete text-based ReID task, where person images and text descriptions are not completely matched and contain partially missing modality data. To this end, we propose a novel Prototype-guided Cross-modal Completion and Alignment (PCCA) framework to handle the aforementioned issues for incomplete text-based ReID. Specifically, we cannot directly retrieve person images based on a text query on missing modality data. Therefore, we propose the cross-modal nearest neighbor construction strategy for missing data by computing the cross-modal similarity between existing images and texts, which provides key guidance for the completion of missing modal features. Furthermore, to efficiently complete the missing modal features, we construct the relation graphs with the aforementioned cross-modal nearest neighbor sets of missing modal data and the corresponding prototypes, which can further enhance the generated missing modal features. Additionally, for tighter fine-grained alignment between images and texts, we raise a prototype-aware cross-modal alignment loss that can effectively reduce the modality heterogeneity gap for better fine-grained alignment in common space. Extensive experimental results on several benchmarks with different missing ratios amply demonstrate that our method can consistently outperform state-of-the-art text-image ReID approaches.
* Sorry, some collaborators do not agree to publish it on Arxiv, so please withdraw this paper