 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBS-Mamba for Black-Soil Area Detection On the Qinghai-Tibetan Plateau
Mar 16, 2025Extremely degraded grassland on the Qinghai-Tibetan Plateau (QTP) presents a significant environmental challenge due to overgrazing, climate change, and rodent activity, which degrade vegetation cover and soil quality. These extremely degraded grassland on QTP, commonly referred to as black-soil area, require accurate assessment to guide effective restoration efforts. In this paper, we present a newly created QTP black-soil dataset, annotated under expert guidance. We introduce a novel neural network model, BS-Mamba, specifically designed for the black-soil area detection using UAV remote sensing imagery. The BS-Mamba model demonstrates higher accuracy in identifying black-soil area across two independent test datasets than the state-of-the-art models. This research contributes to grassland restoration by providing an efficient method for assessing the extent of black-soil area on the QTP.
Origin-Destination Demand Prediction: An Urban Radiation and Attraction Perspective
Nov 29, 2024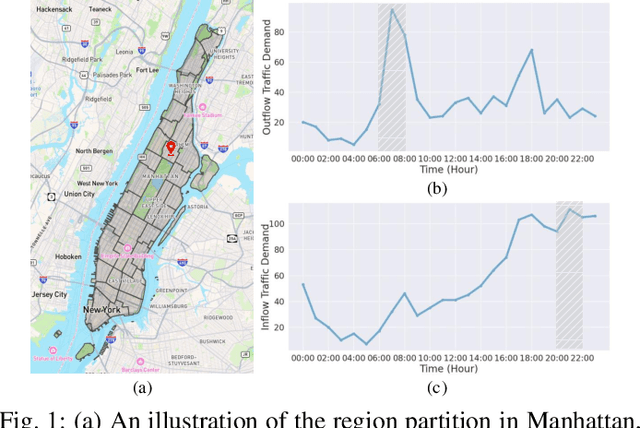
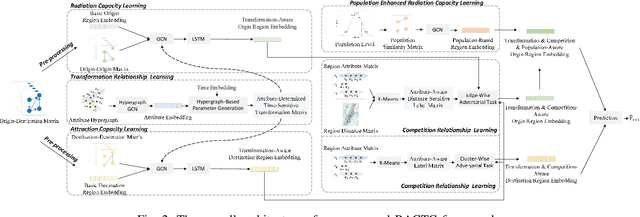
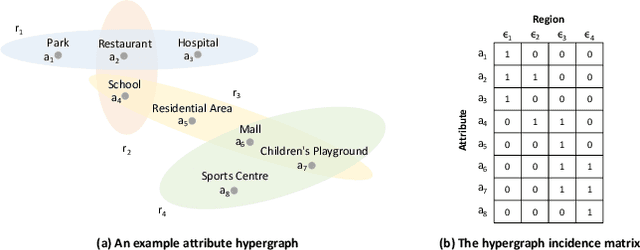
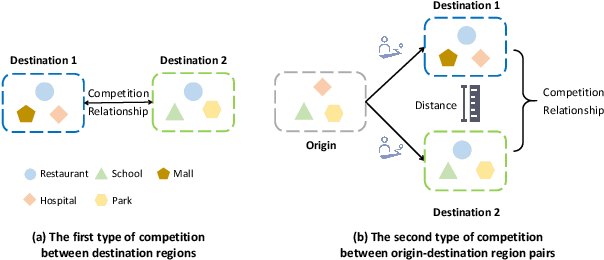
In recent years, origin-destination (OD) demand prediction has gained significant attention for its profound implications in urban development. Existing data-driven deep learning methods primarily focus on the spatial or temporal dependency between regions yet neglecting regions' fundamental functional difference. Though knowledge-driven physical methods have characterised regions' functions by their radiation and attraction capacities, these functions are defined on numerical factors like population without considering regions' intrinsic nominal attributes, e.g., a region is a residential or industrial district. Moreover, the complicated relationships between two types of capacities, e.g., the radiation capacity of a residential district in the morning will be transformed into the attraction capacity in the evening, are totally missing from physical methods. In this paper, we not only generalize the physical radiation and attraction capacities into the deep learning framework with the extended capability to fulfil regions' functions, but also present a new model that captures the relationships between two types of capacities. Specifically, we first model regions' radiation and attraction capacities using a bilateral branch network, each equipped with regions' attribute representations. We then describe the transformation relationship of different capacities of the same region using a hypergraph-based parameter generation method. We finally unveil the competition relationship of different regions with the same attraction capacity through cluster-based adversarial learning. Extensive experiments on two datasets demonstrate the consistent improvements of our method over the state-of-the-art baselines, as well as the good explainability of regions' functions using their nominal attributes.
Robust bilinear factor analysis based on the matrix-variate $t$ distribution
Jan 04, 2024



Factor Analysis based on multivariate $t$ distribution ($t$fa) is a useful robust tool for extracting common factors on heavy-tailed or contaminated data. However, $t$fa is only applicable to vector data. When $t$fa is applied to matrix data, it is common to first vectorize the matrix observations. This introduces two challenges for $t$fa: (i) the inherent matrix structure of the data is broken, and (ii) robustness may be lost, as vectorized matrix data typically results in a high data dimension, which could easily lead to the breakdown of $t$fa. To address these issues, starting from the intrinsic matrix structure of matrix data, a novel robust factor analysis model, namely bilinear factor analysis built on the matrix-variate $t$ distribution ($t$bfa), is proposed in this paper. The novelty is that it is capable to simultaneously extract common factors for both row and column variables of interest on heavy-tailed or contaminated matrix data. Two efficient algorithms for maximum likelihood estimation of $t$bfa are developed. Closed-form expression for the Fisher information matrix to calculate the accuracy of parameter estimates are derived. Empirical studies are conducted to understand the proposed $t$bfa model and compare with related competitors. The results demonstrate the superiority and practicality of $t$bfa. Importantly, $t$bfa exhibits a significantly higher breakdown point than $t$fa, making it more suitable for matrix data.
Robust factored principal component analysis for matrix-valued outlier accommodation and detection
Dec 13, 2021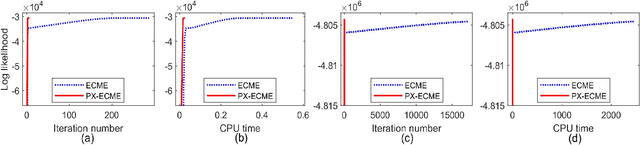
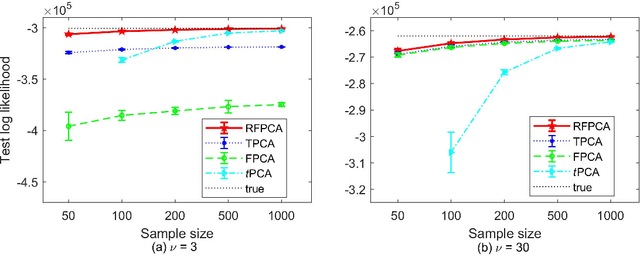
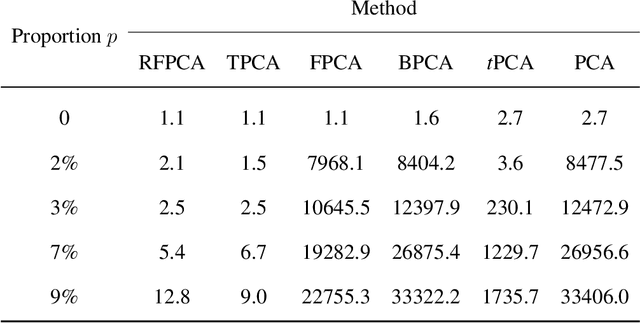
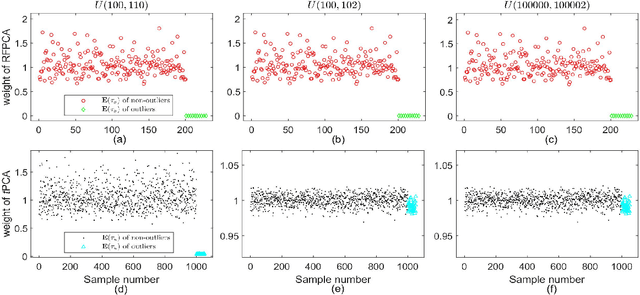
Principal component analysis (PCA) is a popular dimension reduction technique for vector data. Factored PCA (FPCA) is a probabilistic extension of PCA for matrix data, which can substantially reduce the number of parameters in PCA while yield satisfactory performance. However, FPCA is based on the Gaussian assumption and thereby susceptible to outliers. Although the multivariate $t$ distribution as a robust modeling tool for vector data has a very long history, its application to matrix data is very limited. The main reason is that the dimension of the vectorized matrix data is often very high and the higher the dimension, the lower the breakdown point that measures the robustness. To solve the robustness problem suffered by FPCA and make it applicable to matrix data, in this paper we propose a robust extension of FPCA (RFPCA), which is built upon a $t$-type distribution called matrix-variate $t$ distribution. Like the multivariate $t$ distribution, the matrix-variate $t$ distribution can adaptively down-weight outliers and yield robust estimates. We develop a fast EM-type algorithm for parameter estimation. Experiments on synthetic and real-world datasets reveal that RFPCA is compared favorably with several related methods and RFPCA is a simple but powerful tool for matrix-valued outlier detection.
Intent Disentanglement and Feature Self-supervision for Novel Recommendation
Jun 28, 2021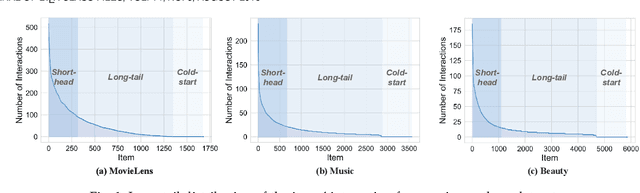
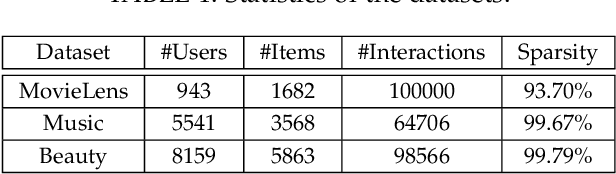
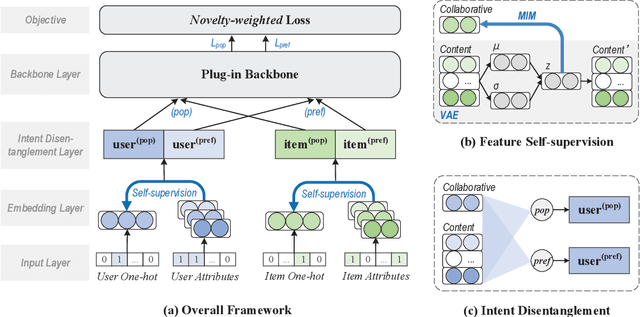
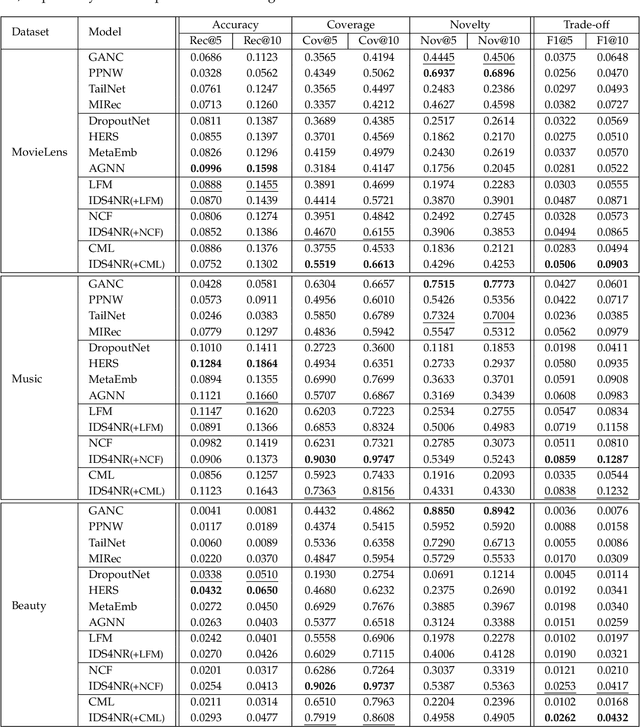
One key property in recommender systems is the long-tail distribution in user-item interactions where most items only have few user feedback. Improving the recommendation of tail items can promote novelty and bring positive effects to both users and providers, and thus is a desirable property of recommender systems. Current novel recommendation studies over-emphasize the importance of tail items without differentiating the degree of users' intent on popularity and often incur a sharp decline of accuracy. Moreover, none of existing methods has ever taken the extreme case of tail items, i.e., cold-start items without any interaction, into consideration. In this work, we first disclose the mechanism that drives a user's interaction towards popular or niche items by disentangling her intent into conformity influence (popularity) and personal interests (preference). We then present a unified end-to-end framework to simultaneously optimize accuracy and novelty targets based on the disentangled intent of popularity and that of preference. We further develop a new paradigm for novel recommendation of cold-start items which exploits the self-supervised learning technique to model the correlation between collaborative features and content features. We conduct extensive experimental results on three real-world datasets. The results demonstrate that our proposed model yields significant improvements over the state-of-the-art baselines in terms of accuracy, novelty, coverage, and trade-off.
Health Status Prediction with Local-Global Heterogeneous Behavior Graph
Mar 23, 2021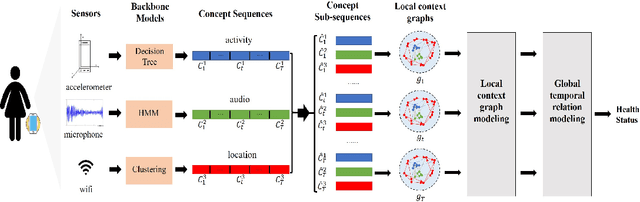


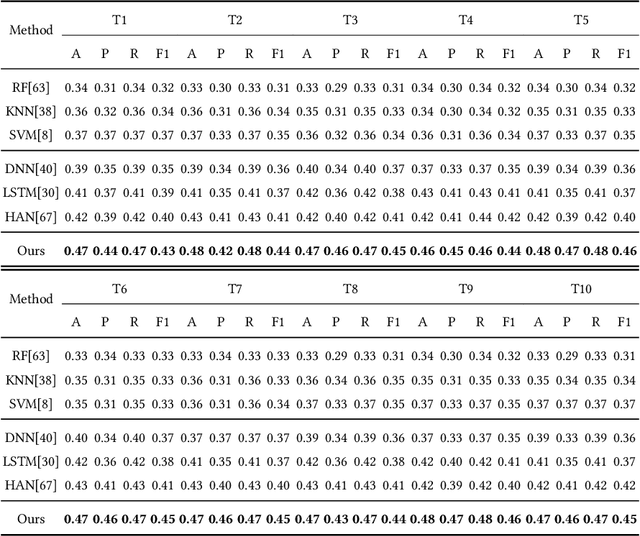
Health management is getting increasing attention all over the world. However, existing health management mainly relies on hospital examination and treatment, which are complicated and untimely. The emerging of mobile devices provides the possibility to manage people's health status in a convenient and instant way. Estimation of health status can be achieved with various kinds of data streams continuously collected from wearable sensors. However, these data streams are multi-source and heterogeneous, containing complex temporal structures with local contextual and global temporal aspects, which makes the feature learning and data joint utilization challenging. We propose to model the behavior-related multi-source data streams with a local-global graph, which contains multiple local context sub-graphs to learn short term local context information with heterogeneous graph neural networks and a global temporal sub-graph to learn long term dependency with self-attention networks. Then health status is predicted based on the structure-aware representation learned from the local-global behavior graph. We take experiments on StudentLife dataset, and extensive results demonstrate the effectiveness of our proposed model.