 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust bilinear factor analysis based on the matrix-variate $t$ distribution
Jan 04, 2024



Factor Analysis based on multivariate $t$ distribution ($t$fa) is a useful robust tool for extracting common factors on heavy-tailed or contaminated data. However, $t$fa is only applicable to vector data. When $t$fa is applied to matrix data, it is common to first vectorize the matrix observations. This introduces two challenges for $t$fa: (i) the inherent matrix structure of the data is broken, and (ii) robustness may be lost, as vectorized matrix data typically results in a high data dimension, which could easily lead to the breakdown of $t$fa. To address these issues, starting from the intrinsic matrix structure of matrix data, a novel robust factor analysis model, namely bilinear factor analysis built on the matrix-variate $t$ distribution ($t$bfa), is proposed in this paper. The novelty is that it is capable to simultaneously extract common factors for both row and column variables of interest on heavy-tailed or contaminated matrix data. Two efficient algorithms for maximum likelihood estimation of $t$bfa are developed. Closed-form expression for the Fisher information matrix to calculate the accuracy of parameter estimates are derived. Empirical studies are conducted to understand the proposed $t$bfa model and compare with related competitors. The results demonstrate the superiority and practicality of $t$bfa. Importantly, $t$bfa exhibits a significantly higher breakdown point than $t$fa, making it more suitable for matrix data.
Choosing the number of factors in factor analysis with incomplete data via a hierarchical Bayesian information criterion
Apr 19, 2022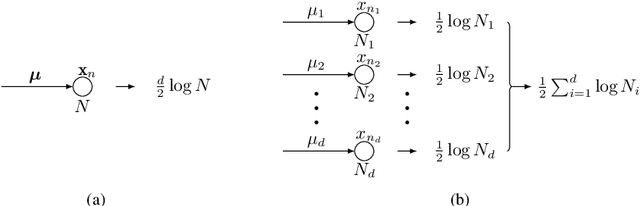
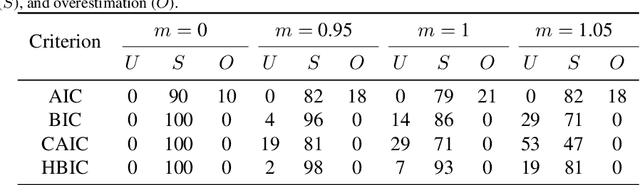
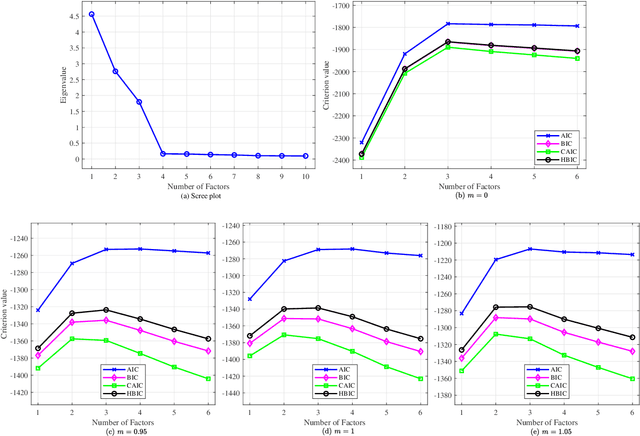
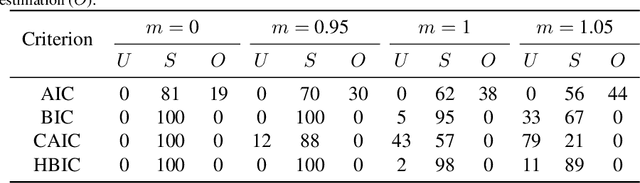
The Bayesian information criterion (BIC), defined as the observed data log likelihood minus a penalty term based on the sample size $N$, is a popular model selection criterion for factor analysis with complete data. This definition has also been suggested for incomplete data. However, the penalty term based on the `complete' sample size $N$ is the same no matter whether in a complete or incomplete data case. For incomplete data, there are often only $N_i<N$ observations for variable $i$, which means that using the `complete' sample size $N$ implausibly ignores the amounts of missing information inherent in incomplete data. Given this observation, a novel criterion called hierarchical BIC (HBIC) for factor analysis with incomplete data is proposed. The novelty is that it only uses the actual amounts of observed information, namely $N_i$'s, in the penalty term. Theoretically, it is shown that HBIC is a large sample approximation of variational Bayesian (VB) lower bound, and BIC is a further approximation of HBIC, which means that HBIC shares the theoretical consistency of BIC. Experiments on synthetic and real data sets are conducted to access the finite sample performance of HBIC, BIC, and related criteria with various missing rates. The results show that HBIC and BIC perform similarly when the missing rate is small, but HBIC is more accurate when the missing rate is not small.