 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Simplifying Large-Scale Spatial Vectors: Fast, Memory-Efficient, and Cost-Predictable k-means
Dec 03, 2024



The k-means algorithm can simplify large-scale spatial vectors, such as 2D geo-locations and 3D point clouds, to support fast analytics and learning. However, when processing large-scale datasets, existing k-means algorithms have been developed to achieve high performance with significant computational resources, such as memory and CPU usage time. These algorithms, though effective, are not well-suited for resource-constrained devices. In this paper, we propose a fast, memory-efficient, and cost-predictable k-means called Dask-means. We first accelerate k-means by designing a memory-efficient accelerator, which utilizes an optimized nearest neighbor search over a memory-tunable index to assign spatial vectors to clusters in batches. We then design a lightweight cost estimator to predict the memory cost and runtime of the k-means task, allowing it to request appropriate memory from devices or adjust the accelerator's required space to meet memory constraints, and ensure sufficient CPU time for running k-means. Experiments show that when simplifying datasets with scale such as $10^6$, Dask-means uses less than $30$MB of memory, achieves over $168$ times speedup compared to the widely-used Lloyd's algorithm. We also validate Dask-means on mobile devices, where it demonstrates significant speedup and low memory cost compared to other state-of-the-art (SOTA) k-means algorithms. Our cost estimator estimates the memory cost with a difference of less than $3\%$ from the actual ones and predicts runtime with an MSE up to $33.3\%$ lower than SOTA methods.
On ADMM in Heterogeneous Federated Learning: Personalization, Robustness, and Fairness
Jul 23, 2024



Statistical heterogeneity is a root cause of tension among accuracy, fairness, and robustness of federated learning (FL), and is key in paving a path forward. Personalized FL (PFL) is an approach that aims to reduce the impact of statistical heterogeneity by developing personalized models for individual users, while also inherently providing benefits in terms of fairness and robustness. However, existing PFL frameworks focus on improving the performance of personalized models while neglecting the global model. Moreover, these frameworks achieve sublinear convergence rates and rely on strong assumptions. In this paper, we propose FLAME, an optimization framework by utilizing the alternating direction method of multipliers (ADMM) to train personalized and global models. We propose a model selection strategy to improve performance in situations where clients have different types of heterogeneous data. Our theoretical analysis establishes the global convergence and two kinds of convergence rates for FLAME under mild assumptions. We theoretically demonstrate that FLAME is more robust and fair than the state-of-the-art methods on a class of linear problems. Our experimental findings show that FLAME outperforms state-of-the-art methods in convergence and accuracy, and it achieves higher test accuracy under various attacks and performs more uniformly across clients.
Efficient k-means with Individual Fairness via Exponential Tilting
Jun 24, 2024In location-based resource allocation scenarios, the distances between each individual and the facility are desired to be approximately equal, thereby ensuring fairness. Individually fair clustering is often employed to achieve the principle of treating all points equally, which can be applied in these scenarios. This paper proposes a novel algorithm, tilted k-means (TKM), aiming to achieve individual fairness in clustering. We integrate the exponential tilting into the sum of squared errors (SSE) to formulate a novel objective function called tilted SSE. We demonstrate that the tilted SSE can generalize to SSE and employ the coordinate descent and first-order gradient method for optimization. We propose a novel fairness metric, the variance of the distances within each cluster, which can alleviate the Matthew Effect typically caused by existing fairness metrics. Our theoretical analysis demonstrates that the well-known k-means++ incurs a multiplicative error of O(k log k), and we establish the convergence of TKM under mild conditions. In terms of fairness, we prove that the variance generated by TKM decreases with a scaled hyperparameter. In terms of efficiency, we demonstrate the time complexity is linear with the dataset size. Our experiments demonstrate that TKM outperforms state-of-the-art methods in effectiveness, fairness, and efficiency.
Dependency Relationships-Enhanced Attentive Group Recommendation in HINs
Nov 19, 2023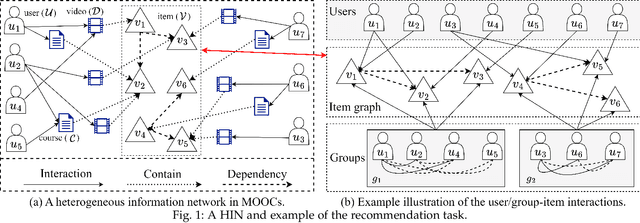

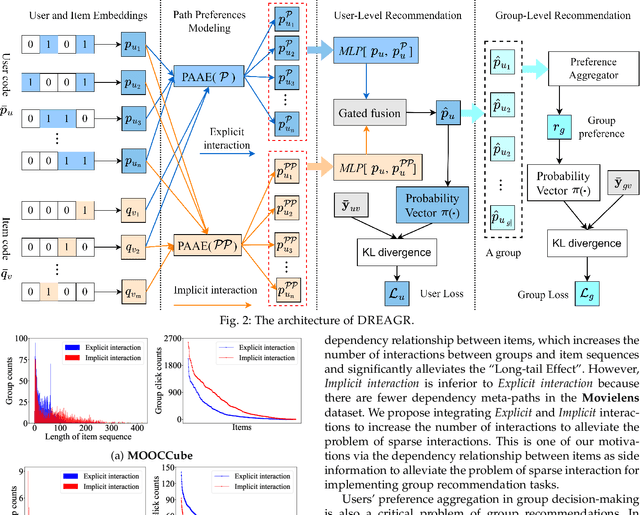

Recommending suitable items to a group of users, commonly referred to as the group recommendation task, is becoming increasingly urgent with the development of group activities. The challenges within the group recommendation task involve aggregating the individual preferences of group members as the group's preferences and facing serious sparsity problems due to the lack of user/group-item interactions. To solve these problems, we propose a novel approach called Dependency Relationships-Enhanced Attentive Group Recommendation (DREAGR) for the recommendation task of occasional groups. Specifically, we introduce the dependency relationship between items as side information to enhance the user/group-item interaction and alleviate the interaction sparsity problem. Then, we propose a Path-Aware Attention Embedding (PAAE) method to model users' preferences on different types of paths. Next, we design a gated fusion mechanism to fuse users' preferences into their comprehensive preferences. Finally, we develop an attention aggregator that aggregates users' preferences as the group's preferences for the group recommendation task. We conducted experiments on two datasets to demonstrate the superiority of DREAGR by comparing it with state-of-the-art group recommender models. The experimental results show that DREAGR outperforms other models, especially HR@N and NDCG@N (N=5, 10), where DREAGR has improved in the range of 3.64% to 7.01% and 2.57% to 3.39% on both datasets, respectively.
Personalized Federated Learning via ADMM with Moreau Envelope
Nov 12, 2023Personalized federated learning (PFL) is an approach proposed to address the issue of poor convergence on heterogeneous data. However, most existing PFL frameworks require strong assumptions for convergence. In this paper, we propose an alternating direction method of multipliers (ADMM) for training PFL models with Moreau envelope (FLAME), which achieves a sublinear convergence rate, relying on the relatively weak assumption of gradient Lipschitz continuity. Moreover, due to the gradient-free nature of ADMM, FLAME alleviates the need for hyperparameter tuning, particularly in avoiding the adjustment of the learning rate when training the global model. In addition, we propose a biased client selection strategy to expedite the convergence of training of PFL models. Our theoretical analysis establishes the global convergence under both unbiased and biased client selection strategies. Our experiments validate that FLAME, when trained on heterogeneous data, outperforms state-of-the-art methods in terms of model performance. Regarding communication efficiency, it exhibits an average speedup of 3.75x compared to the baselines. Furthermore, experimental results validate that the biased client selection strategy speeds up the convergence of both personalized and global models.
Intent Disentanglement and Feature Self-supervision for Novel Recommendation
Jun 28, 2021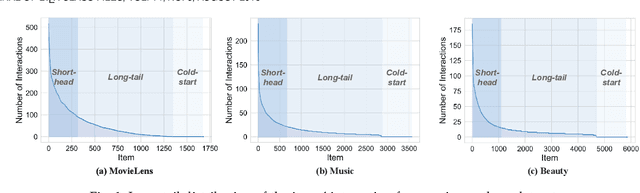
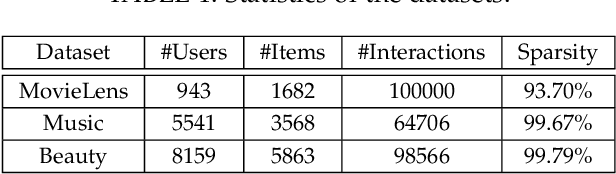
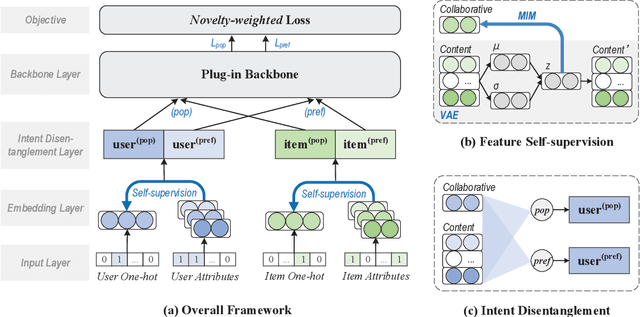
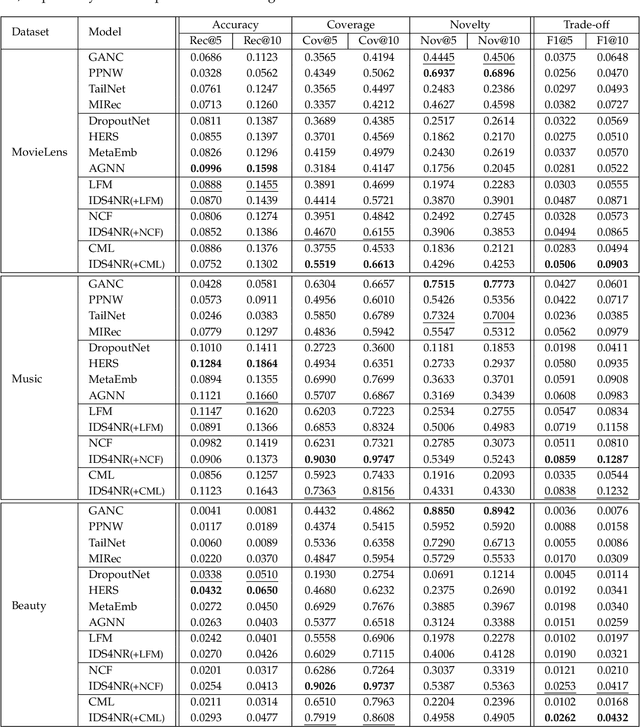
One key property in recommender systems is the long-tail distribution in user-item interactions where most items only have few user feedback. Improving the recommendation of tail items can promote novelty and bring positive effects to both users and providers, and thus is a desirable property of recommender systems. Current novel recommendation studies over-emphasize the importance of tail items without differentiating the degree of users' intent on popularity and often incur a sharp decline of accuracy. Moreover, none of existing methods has ever taken the extreme case of tail items, i.e., cold-start items without any interaction, into consideration. In this work, we first disclose the mechanism that drives a user's interaction towards popular or niche items by disentangling her intent into conformity influence (popularity) and personal interests (preference). We then present a unified end-to-end framework to simultaneously optimize accuracy and novelty targets based on the disentangled intent of popularity and that of preference. We further develop a new paradigm for novel recommendation of cold-start items which exploits the self-supervised learning technique to model the correlation between collaborative features and content features. We conduct extensive experimental results on three real-world datasets. The results demonstrate that our proposed model yields significant improvements over the state-of-the-art baselines in terms of accuracy, novelty, coverage, and trade-off.