 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoVNet: Configurable Field-of-View Speech Enhancement with Low Computation and Distortion for Smart Glasses
Aug 12, 2024


This paper presents a novel multi-channel speech enhancement approach, FoVNet, that enables highly efficient speech enhancement within a configurable field of view (FoV) of a smart-glasses user without needing specific target-talker(s) directions. It advances over prior works by enhancing all speakers within any given FoV, with a hybrid signal processing and deep learning approach designed with high computational efficiency. The neural network component is designed with ultra-low computation (about 50 MMACS). A multi-channel Wiener filter and a post-processing module are further used to improve perceptual quality. We evaluate our algorithm with a microphone array on smart glasses, providing a configurable, efficient solution for augmented hearing on energy-constrained devices. FoVNet excels in both computational efficiency and speech quality across multiple scenarios, making it a promising solution for smart glasses applications.
TRUNet: Transformer-Recurrent-U Network for Multi-channel Reverberant Sound Source Separation
Oct 08, 2021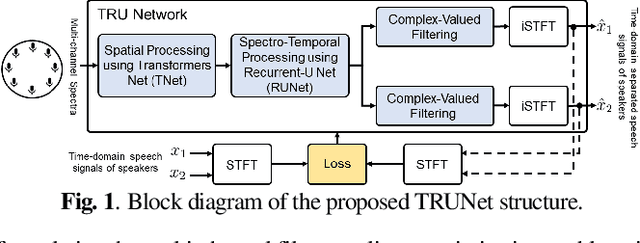
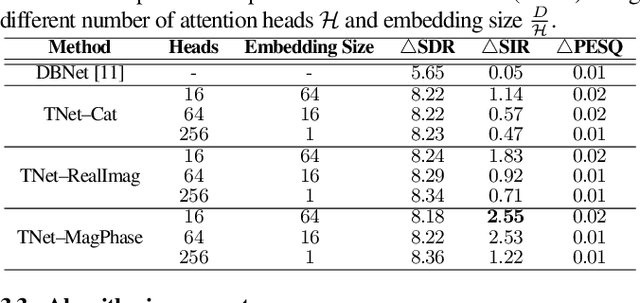
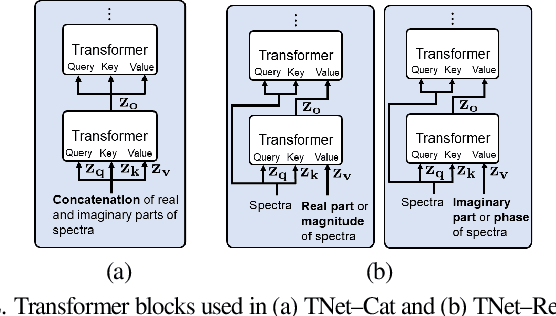
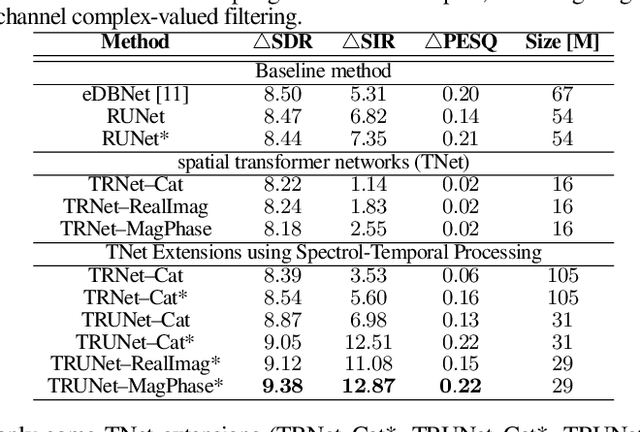
In recent years, many deep learning techniques for single-channel sound source separation have been proposed using recurrent, convolutional and transformer networks. When multiple microphones are available, spatial diversity between speakers and background noise in addition to spectro-temporal diversity can be exploited by using multi-channel filters for sound source separation. Aiming at end-to-end multi-channel source separation, in this paper we propose a transformer-recurrent-U network (TRUNet), which directly estimates multi-channel filters from multi-channel input spectra. TRUNet consists of a spatial processing network with an attention mechanism across microphone channels aiming at capturing the spatial diversity, and a spectro-temporal processing network aiming at capturing spectral and temporal diversities. In addition to multi-channel filters, we also consider estimating single-channel filters from multi-channel input spectra using TRUNet. We train the network on a large reverberant dataset using a combined compressed mean-squared error loss function, which further improves the sound separation performance. We evaluate the network on a realistic and challenging reverberant dataset, generated from measured room impulse responses of an actual microphone array. The experimental results on realistic reverberant sound source separation show that the proposed TRUNet outperforms state-of-the-art single-channel and multi-channel source separation methods.
DBNET: DOA-driven beamforming network for end-to-end farfield sound source separation
Oct 22, 2020



Many deep learning techniques are available to perform source separation and reduce background noise. However, designing an end-to-end multi-channel source separation method using deep learning and conventional acoustic signal processing techniques still remains challenging. In this paper we propose a direction-of-arrival-driven beamforming network (DBnet) consisting of direction-of-arrival (DOA) estimation and beamforming layers for end-to-end source separation. We propose to train DBnet using loss functions that are solely based on the distances between the separated speech signals and the target speech signals, without a need for the ground-truth DOAs of speakers. To improve the source separation performance, we also propose end-to-end extensions of DBnet which incorporate post masking networks. We evaluate the proposed DBnet and its extensions on a very challenging dataset, targeting realistic far-field sound source separation in reverberant and noisy environments. The experimental results show that the proposed extended DBnet using a convolutional-recurrent post masking network outperforms state-of-the-art source separation methods.
Improving auditory attention decoding performance of linear and non-linear methods using state-space model
Apr 02, 2020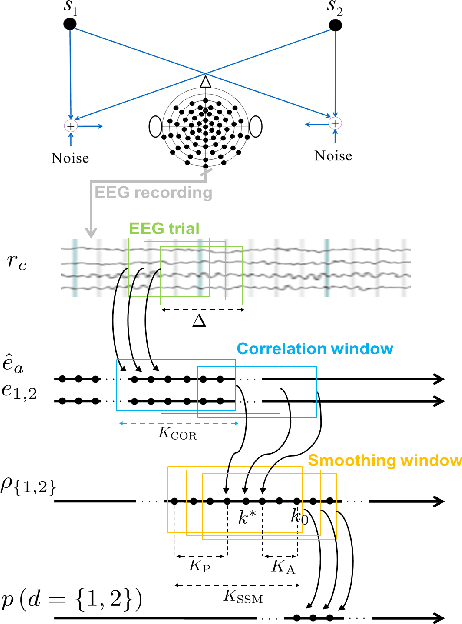
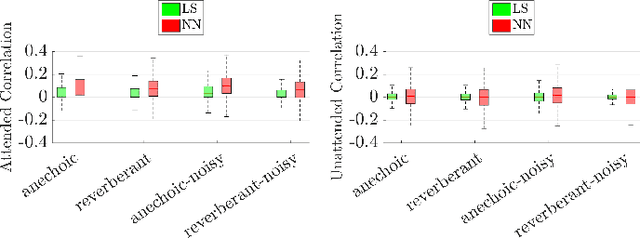

Identifying the target speaker in hearing aid applications is crucial to improve speech understanding. Recent advances in electroencephalography (EEG) have shown that it is possible to identify the target speaker from single-trial EEG recordings using auditory attention decoding (AAD) methods. AAD methods reconstruct the attended speech envelope from EEG recordings, based on a linear least-squares cost function or non-linear neural networks, and then directly compare the reconstructed envelope with the speech envelopes of speakers to identify the attended speaker using Pearson correlation coefficients. Since these correlation coefficients are highly fluctuating, for a reliable decoding a large correlation window is used, which causes a large processing delay. In this paper, we investigate a state-space model using correlation coefficients obtained with a small correlation window to improve the decoding performance of the linear and the non-linear AAD methods. The experimental results show that the state-space model significantly improves the decoding performance.