 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Guided Graph Convolutional Networks for Skeleton-Based Action Recognition
Paper and Code
Oct 10, 2022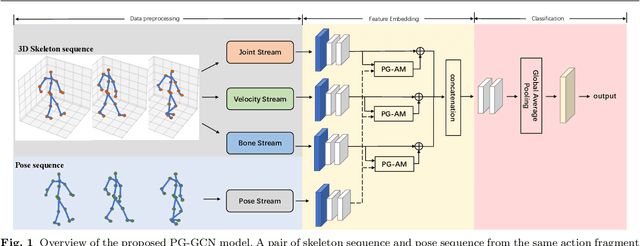
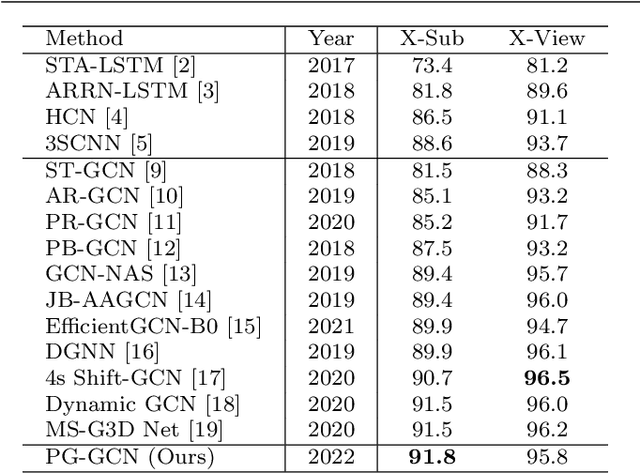
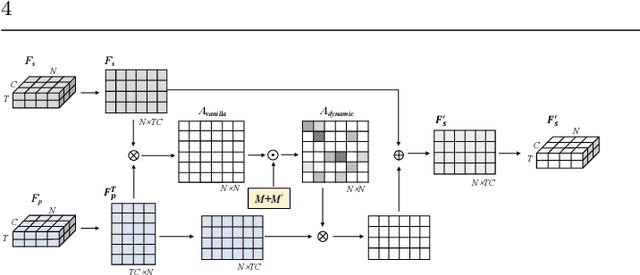
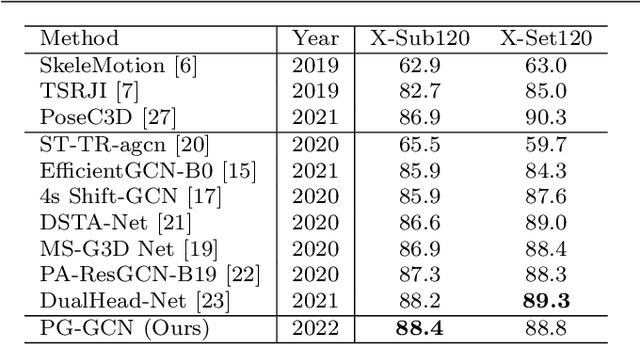
Graph convolutional networks (GCNs), which can model the human body skeletons as spatial and temporal graphs, have shown remarkable potential in skeleton-based action recognition. However, in the existing GCN-based methods, graph-structured representation of the human skeleton makes it difficult to be fused with other modalities, especially in the early stages. This may limit their scalability and performance in action recognition tasks. In addition, the pose information, which naturally contains informative and discriminative clues for action recognition, is rarely explored together with skeleton data in existing methods. In this work, we propose pose-guided GCN (PG-GCN), a multi-modal framework for high-performance human action recognition. In particular, a multi-stream network is constructed to simultaneously explore the robust features from both the pose and skeleton data, while a dynamic attention module is designed for early-stage feature fusion. The core idea of this module is to utilize a trainable graph to aggregate features from the skeleton stream with that of the pose stream, which leads to a network with more robust feature representation ability. Extensive experiments show that the proposed PG-GCN can achieve state-of-the-art performance on the NTU RGB+D 60 and NTU RGB+D 120 datasets.