 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLock: Defending Malicious Behaviors in Federated Learning with Blockchain
Nov 05, 2022Federated learning (FL) is a promising way to allow multiple data owners (clients) to collaboratively train machine learning models without compromising data privacy. Yet, existing FL solutions usually rely on a centralized aggregator for model weight aggregation, while assuming clients are honest. Even if data privacy can still be preserved, the problem of single-point failure and data poisoning attack from malicious clients remains unresolved. To tackle this challenge, we propose to use distributed ledger technology (DLT) to achieve FLock, a secure and reliable decentralized Federated Learning system built on blockchain. To guarantee model quality, we design a novel peer-to-peer (P2P) review and reward/slash mechanism to detect and deter malicious clients, powered by on-chain smart contracts. The reward/slash mechanism, in addition, serves as incentives for participants to honestly upload and review model parameters in the FLock system. FLock thus improves the performance and the robustness of FL systems in a fully P2P manner.
Generalized Data Weighting via Class-level Gradient Manipulation
Oct 29, 2021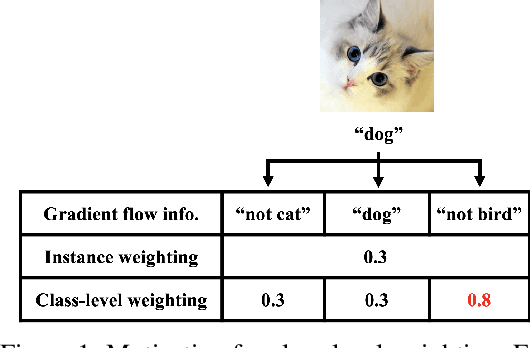



Label noise and class imbalance are two major issues coexisting in real-world datasets. To alleviate the two issues, state-of-the-art methods reweight each instance by leveraging a small amount of clean and unbiased data. Yet, these methods overlook class-level information within each instance, which can be further utilized to improve performance. To this end, in this paper, we propose Generalized Data Weighting (GDW) to simultaneously mitigate label noise and class imbalance by manipulating gradients at the class level. To be specific, GDW unrolls the loss gradient to class-level gradients by the chain rule and reweights the flow of each gradient separately. In this way, GDW achieves remarkable performance improvement on both issues. Aside from the performance gain, GDW efficiently obtains class-level weights without introducing any extra computational cost compared with instance weighting methods. Specifically, GDW performs a gradient descent step on class-level weights, which only relies on intermediate gradients. Extensive experiments in various settings verify the effectiveness of GDW. For example, GDW outperforms state-of-the-art methods by $2.56\%$ under the $60\%$ uniform noise setting in CIFAR10. Our code is available at https://github.com/GGchen1997/GDW-NIPS2021.