 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhite Aggregation and Restoration for Few-shot 3D Point Cloud Semantic Segmentation
Sep 17, 2025Few-Shot 3D Point Cloud Segmentation (FS-PCS) aims to predict per-point labels for an unlabeled point cloud, given only a few labeled examples. To extract discriminative representations from the limited support set, existing methods have constructed prototypes using conventional algorithms such as farthest point sampling. However, we point out that its initial randomness significantly affects FS-PCS performance and that the prototype generation process remains underexplored despite its prevalence. This motivates us to investigate an advanced prototype generation method based on attention mechanism. Despite its potential, we found that vanilla module suffers from the distributional gap between learnable prototypical tokens and support features. To overcome this, we propose White Aggregation and Restoration Module (WARM), which resolves the misalignment by sandwiching cross-attention between whitening and coloring transformations. Specifically, whitening aligns the support features to prototypical tokens before attention process, and subsequently coloring restores the original distribution to the attended tokens. This simple yet effective design enables robust attention, thereby generating representative prototypes by capturing the semantic relationships among support features. Our method achieves state-of-the-art performance with a significant margin on multiple FS-PCS benchmarks, demonstrating its effectiveness through extensive experiments.
Activating Self-Attention for Multi-Scene Absolute Pose Regression
Nov 03, 2024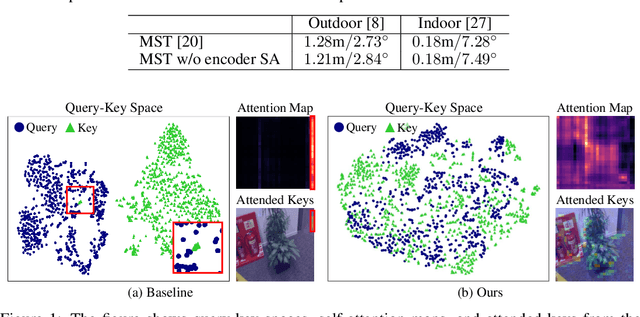
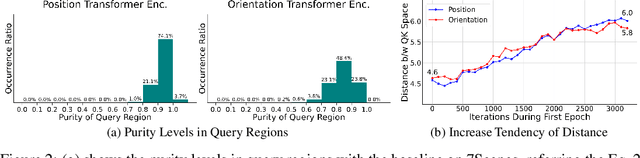

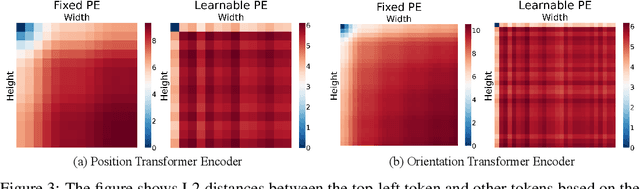
Multi-scene absolute pose regression addresses the demand for fast and memory-efficient camera pose estimation across various real-world environments. Nowadays, transformer-based model has been devised to regress the camera pose directly in multi-scenes. Despite its potential, transformer encoders are underutilized due to the collapsed self-attention map, having low representation capacity. This work highlights the problem and investigates it from a new perspective: distortion of query-key embedding space. Based on the statistical analysis, we reveal that queries and keys are mapped in completely different spaces while only a few keys are blended into the query region. This leads to the collapse of the self-attention map as all queries are considered similar to those few keys. Therefore, we propose simple but effective solutions to activate self-attention. Concretely, we present an auxiliary loss that aligns queries and keys, preventing the distortion of query-key space and encouraging the model to find global relations by self-attention. In addition, the fixed sinusoidal positional encoding is adopted instead of undertrained learnable one to reflect appropriate positional clues into the inputs of self-attention. As a result, our approach resolves the aforementioned problem effectively, thus outperforming existing methods in both outdoor and indoor scenes.
Prediction-Feedback DETR for Temporal Action Detection
Aug 29, 2024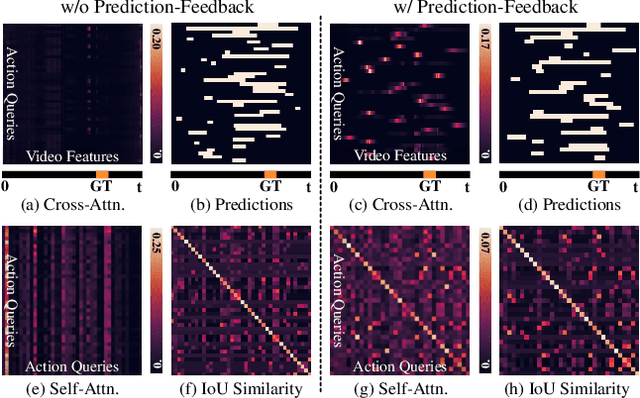
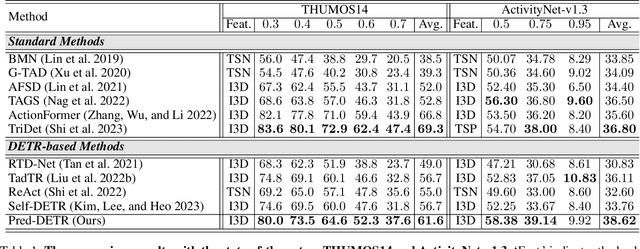
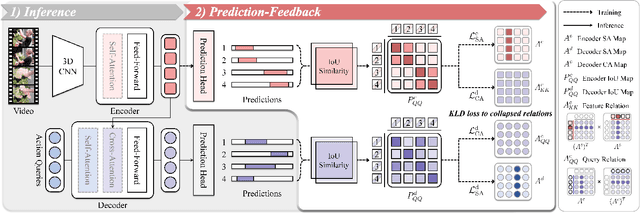
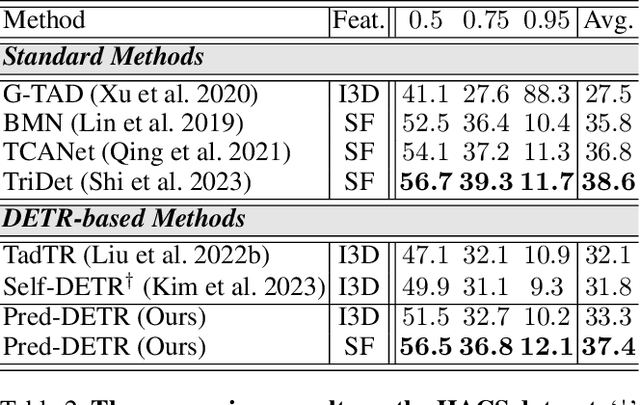
Temporal Action Detection (TAD) is fundamental yet challenging for real-world video applications. Leveraging the unique benefits of transformers, various DETR-based approaches have been adopted in TAD. However, it has recently been identified that the attention collapse in self-attention causes the performance degradation of DETR for TAD. Building upon previous research, this paper newly addresses the attention collapse problem in cross-attention within DETR-based TAD methods. Moreover, our findings reveal that cross-attention exhibits patterns distinct from predictions, indicating a short-cut phenomenon. To resolve this, we propose a new framework, Prediction-Feedback DETR (Pred-DETR), which utilizes predictions to restore the collapse and align the cross- and self-attention with predictions. Specifically, we devise novel prediction-feedback objectives using guidance from the relations of the predictions. As a result, Pred-DETR significantly alleviates the collapse and achieves state-of-the-art performance among DETR-based methods on various challenging benchmarks including THUMOS14, ActivityNet-v1.3, HACS, and FineAction.
Long-Term Pre-training for Temporal Action Detection with Transformers
Aug 23, 2024



Temporal action detection (TAD) is challenging, yet fundamental for real-world video applications. Recently, DETR-based models for TAD have been prevailing thanks to their unique benefits. However, transformers demand a huge dataset, and unfortunately data scarcity in TAD causes a severe degeneration. In this paper, we identify two crucial problems from data scarcity: attention collapse and imbalanced performance. To this end, we propose a new pre-training strategy, Long-Term Pre-training (LTP), tailored for transformers. LTP has two main components: 1) class-wise synthesis, 2) long-term pretext tasks. Firstly, we synthesize long-form video features by merging video snippets of a target class and non-target classes. They are analogous to untrimmed data used in TAD, despite being created from trimmed data. In addition, we devise two types of long-term pretext tasks to learn long-term dependency. They impose long-term conditions such as finding second-to-fourth or short-duration actions. Our extensive experiments show state-of-the-art performances in DETR-based methods on ActivityNet-v1.3 and THUMOS14 by a large margin. Moreover, we demonstrate that LTP significantly relieves the data scarcity issues in TAD.
Self-Feedback DETR for Temporal Action Detection
Aug 21, 2023



Temporal Action Detection (TAD) is challenging but fundamental for real-world video applications. Recently, DETR-based models have been devised for TAD but have not performed well yet. In this paper, we point out the problem in the self-attention of DETR for TAD; the attention modules focus on a few key elements, called temporal collapse problem. It degrades the capability of the encoder and decoder since their self-attention modules play no role. To solve the problem, we propose a novel framework, Self-DETR, which utilizes cross-attention maps of the decoder to reactivate self-attention modules. We recover the relationship between encoder features by simple matrix multiplication of the cross-attention map and its transpose. Likewise, we also get the information within decoder queries. By guiding collapsed self-attention maps with the guidance map calculated, we settle down the temporal collapse of self-attention modules in the encoder and decoder. Our extensive experiments demonstrate that Self-DETR resolves the temporal collapse problem by keeping high diversity of attention over all layers.