 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAILTTS: Adversarial Learning of Intermediate Acoustic Feature for End-to-End Lightweight Text-to-Speech
Paper and Code
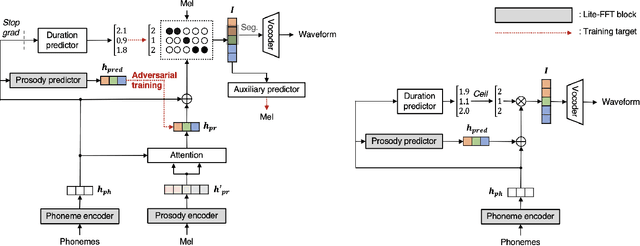
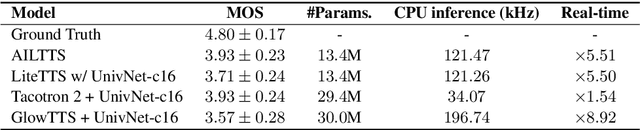


The quality of end-to-end neural text-to-speech (TTS) systems highly depends on the reliable estimation of intermediate acoustic features from text inputs. To reduce the complexity of the speech generation process, several non-autoregressive TTS systems directly find a mapping relationship between text and waveforms. However, the generation quality of these system is unsatisfactory due to the difficulty in modeling the dynamic nature of prosodic information. In this paper, we propose an effective prosody predictor that successfully replicates the characteristics of prosodic features extracted from mel-spectrograms. Specifically, we introduce a generative model-based conditional discriminator to enable the estimated embeddings have highly informative prosodic features, which significantly enhances the expressiveness of generated speech. Since the estimated embeddings obtained by the proposed method are highly correlated with acoustic features, the time-alignment of input texts and intermediate features is greatly simplified, which results in faster convergence. Our proposed model outperforms several publicly available models based on various objective and subjective evaluation metrics, even using a relatively small number of parameters.