 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistinctive Feature Codec: Adaptive Segmentation for Efficient Speech Representation
May 24, 2025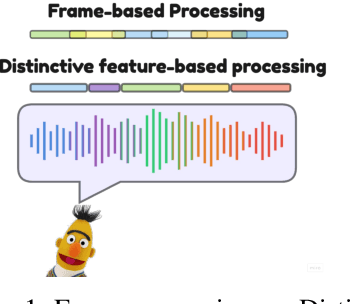
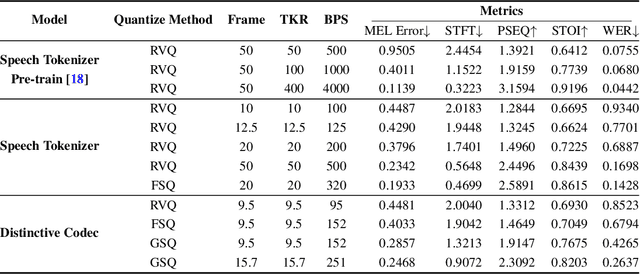
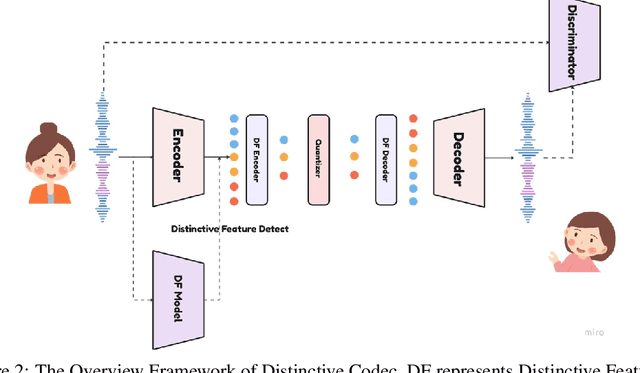
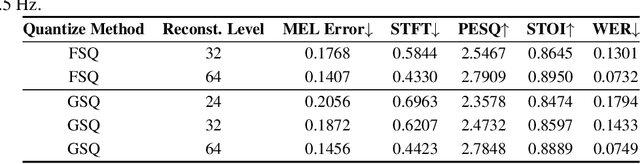
The tokenization of speech with neural speech codec models is a crucial aspect of AI systems designed for speech understanding and generation. While text-based systems naturally benefit from token boundaries between discrete symbols, tokenizing continuous speech signals is more complex due to the unpredictable timing of important acoustic variations. Most current neural speech codecs typically address this by using uniform processing at fixed time intervals, which overlooks the varying information density inherent in speech. In this paper, we introduce a distinctive feature-based approach that dynamically allocates tokens based on the perceptual significance of speech content. By learning to identify and prioritize distinctive regions in speech signals, our approach achieves a significantly more efficient speech representation compared with conventional frame-based methods. This work marks the first successful extension of traditional signal processing-based distinctive features into deep learning frameworks. Through rigorous experimentation, we demonstrate the effectiveness of our approach and provide theoretical insights into how aligning segment boundaries with natural acoustic transitions improves codebook utilization. Additionally, we enhance tokenization stability by developing a Group-wise Scalar Quantization approach for variable-length segments. Our distinctive feature-based approach offers a promising alternative to conventional frame-based processing and advances interpretable representation learning in the modern deep learning speech processing framework.
A unified multichannel far-field speech recognition system: combining neural beamforming with attention based end-to-end model
Jan 05, 2024Far-field speech recognition is a challenging task that conventionally uses signal processing beamforming to attack noise and interference problem. But the performance has been found usually limited due to heavy reliance on environmental assumption. In this paper, we propose a unified multichannel far-field speech recognition system that combines the neural beamforming and transformer-based Listen, Spell, Attend (LAS) speech recognition system, which extends the end-to-end speech recognition system further to include speech enhancement. Such framework is then jointly trained to optimize the final objective of interest. Specifically, factored complex linear projection (fCLP) has been adopted to form the neural beamforming. Several pooling strategies to combine look directions are then compared in order to find the optimal approach. Moreover, information of the source direction is also integrated in the beamforming to explore the usefulness of source direction as a prior, which is usually available especially in multi-modality scenario. Experiments on different microphone array geometry are conducted to evaluate the robustness against spacing variance of microphone array. Large in-house databases are used to evaluate the effectiveness of the proposed framework and the proposed method achieve 19.26\% improvement when compared with a strong baseline.
Security of Facial Forensics Models Against Adversarial Attacks
Nov 02, 2019

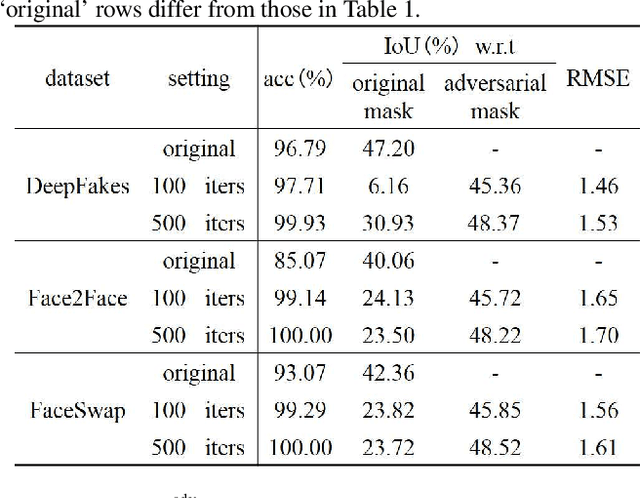

Deep neural networks (DNNs) have been used in forensics to identify fake facial images. We investigated several DNN-based forgery forensics models (FFMs) to determine whether they are secure against adversarial attacks. We experimentally demonstrated the existence of individual adversarial perturbations (IAPs) and universal adversarial perturbations (UAPs) that can lead a well-performed FFM to misbehave. Based on iterative procedure, gradient information is used to generate two kinds of IAPs that can be used to fabricate classification and segmentation outputs. In contrast, UAPs are generated on the basis of over-firing. We designed a new objective function that encourages neurons to over-fire, which makes UAP generation feasible even without using training data. Experiments demonstrated the transferability of UAPs across unseen datasets and unseen FFMs. Moreover, we are the first to conduct subjective assessment for imperceptibility of the adversarial perturbations, revealing that the crafted UAPs are visually negligible. There findings provide a baseline for evaluating the adversarial security of FFMs.
A Method for Identifying Origin of Digital Images Using a Convolution Neural Network
Nov 02, 2019

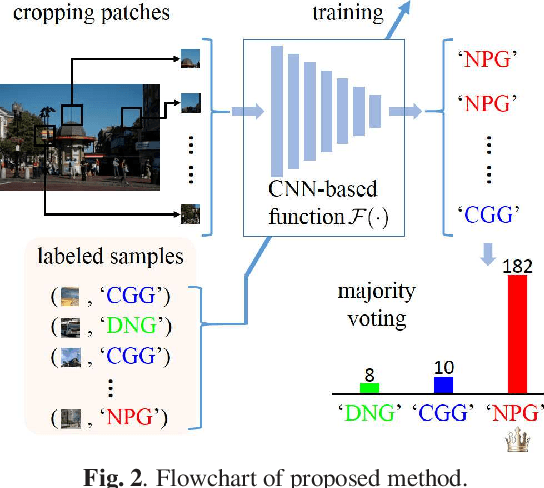
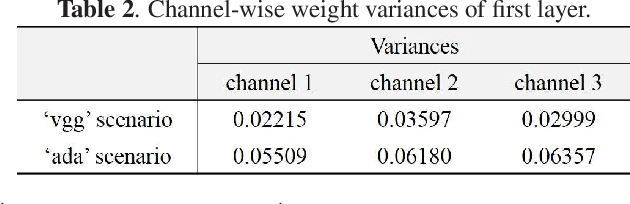
The rapid development of deep learning techniques has created new challenges in identifying the origin of digital images because generative adversarial networks and variational autoencoders can create plausible digital images whose contents are not present in natural scenes. In this paper, we consider the origin that can be broken down into three categories: natural photographic image (NPI), computer generated graphic (CGG), and deep network generated image (DGI). A method is presented for effectively identifying the origin of digital images that is based on a convolutional neural network (CNN) and uses a local-to-global framework to reduce training complexity. By feeding labeled data, the CNN is trained to predict the origin of local patches cropped from an image. The origin of the full-size image is then determined by majority voting. Unlike previous forensic methods, the CNN takes the raw pixels as input without the aid of "residual map". Experimental results revealed that not only the high-frequency components but also the middle-frequency ones contribute to origin identification. The proposed method achieved up to 95.21% identification accuracy and behaved robustly against several common post-processing operations including JPEG compression, scaling, geometric transformation, and contrast stretching. The quantitative results demonstrate that the proposed method is more effective than handcrafted feature-based methods.
Generating Sentiment-Preserving Fake Online Reviews Using Neural Language Models and Their Human- and Machine-based Detection
Jul 22, 2019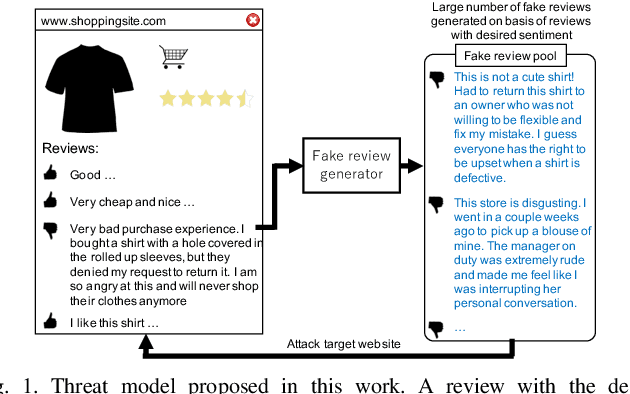
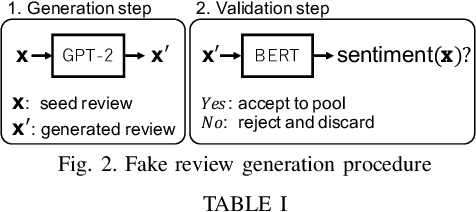


Advanced neural language models (NLMs) are widely used in sequence generation tasks because they are able to produce fluent and meaningful sentences. They can also be used to generate fake reviews, which can then be used to attack online review systems and influence the buying decisions of online shoppers. A problem in fake review generation is how to generate the desired sentiment/topic. Existing solutions first generate an initial review based on some keywords and then modify some of the words in the initial review so that the review has the desired sentiment/topic. We overcome this problem by using the GPT-2 NLM to generate a large number of high-quality reviews based on a review with the desired sentiment and then using a BERT based text classifier (with accuracy of 96\%) to filter out reviews with undesired sentiments. Because none of the words in the review are modified, fluent samples like the training data can be generated from the learned distribution. A subjective evaluation with 80 participants demonstrated that this simple method can produce reviews that are as fluent as those written by people. It also showed that the participants tended to distinguish fake reviews randomly. Two countermeasures, GROVER and GLTR, were found to be able to accurately detect fake review.
Multi-task Learning For Detecting and Segmenting Manipulated Facial Images and Videos
Jun 17, 2019
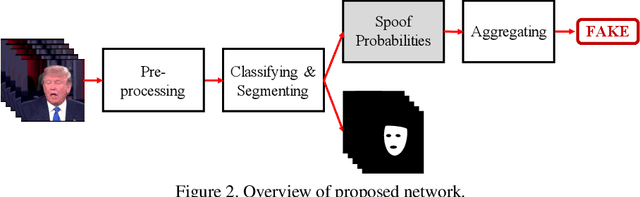
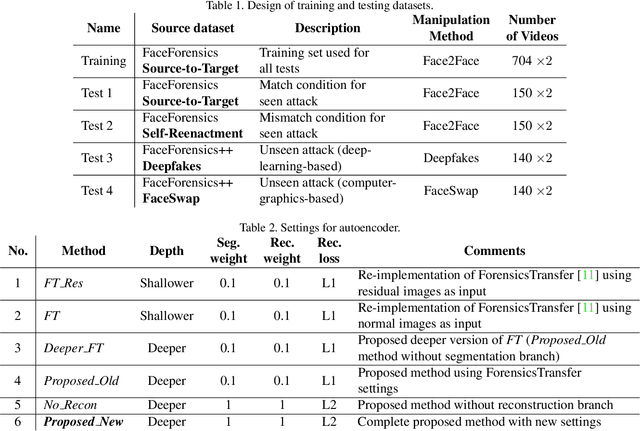
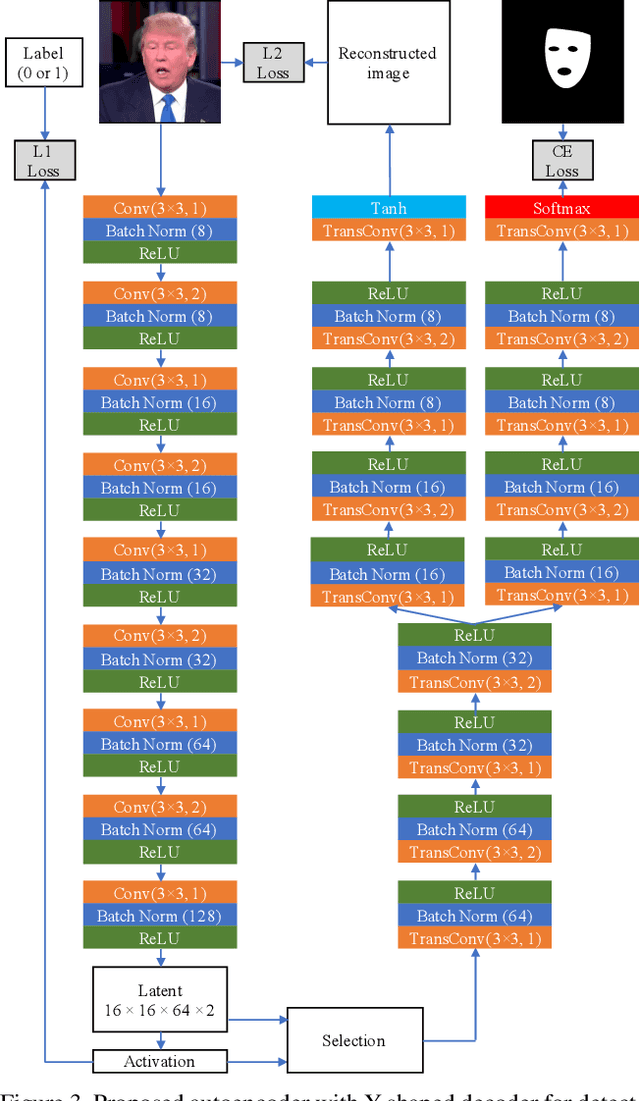
Detecting manipulated images and videos is an important topic in digital media forensics. Most detection methods use binary classification to determine the probability of a query being manipulated. Another important topic is locating manipulated regions (i.e., performing segmentation), which are mostly created by three commonly used attacks: removal, copy-move, and splicing. We have designed a convolutional neural network that uses the multi-task learning approach to simultaneously detect manipulated images and videos and locate the manipulated regions for each query. Information gained by performing one task is shared with the other task and thereby enhance the performance of both tasks. A semi-supervised learning approach is used to improve the network's generability. The network includes an encoder and a Y-shaped decoder. Activation of the encoded features is used for the binary classification. The output of one branch of the decoder is used for segmenting the manipulated regions while that of the other branch is used for reconstructing the input, which helps improve overall performance. Experiments using the FaceForensics and FaceForensics++ databases demonstrated the network's effectiveness against facial reenactment attacks and face swapping attacks as well as its ability to deal with the mismatch condition for previously seen attacks. Moreover, fine-tuning using just a small amount of data enables the network to deal with unseen attacks.
Speaker Anonymization Using X-vector and Neural Waveform Models
May 30, 2019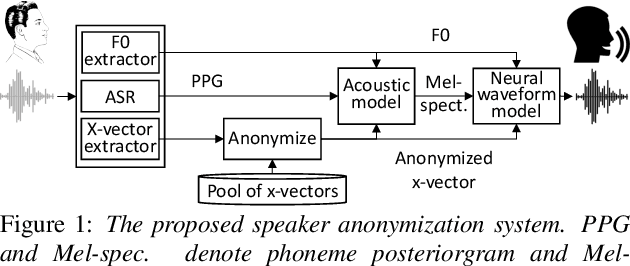
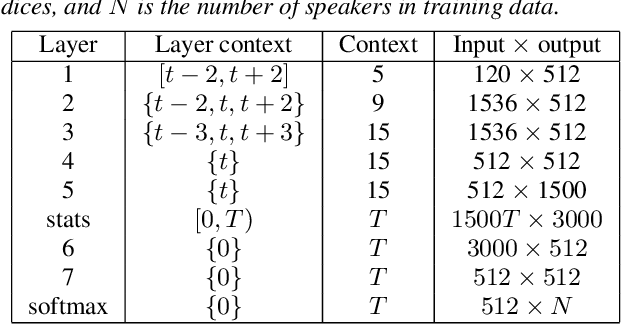
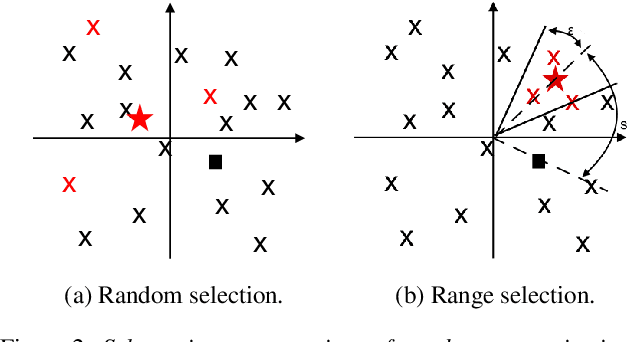
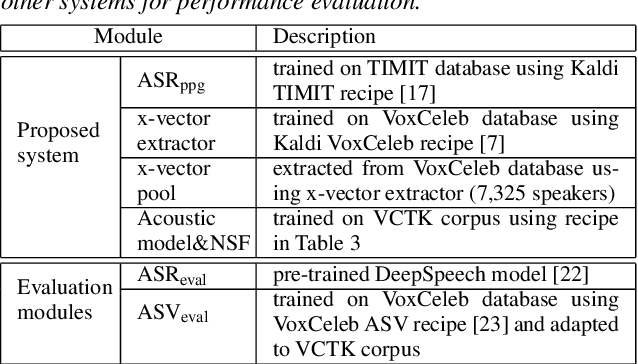
The social media revolution has produced a plethora of web services to which users can easily upload and share multimedia documents. Despite the popularity and convenience of such services, the sharing of such inherently personal data, including speech data, raises obvious security and privacy concerns. In particular, a user's speech data may be acquired and used with speech synthesis systems to produce high-quality speech utterances which reflect the same user's speaker identity. These utterances may then be used to attack speaker verification systems. One solution to mitigate these concerns involves the concealing of speaker identities before the sharing of speech data. For this purpose, we present a new approach to speaker anonymization. The idea is to extract linguistic and speaker identity features from an utterance and then to use these with neural acoustic and waveform models to synthesize anonymized speech. The original speaker identity, in the form of timbre, is suppressed and replaced with that of an anonymous pseudo identity. The approach exploits state-of-the-art x-vector speaker representations. These are used to derive anonymized pseudo speaker identities through the combination of multiple, random speaker x-vectors. Experimental results show that the proposed approach is effective in concealing speaker identities. It increases the equal error rate of a speaker verification system while maintaining high quality, anonymized speech.
Joint training framework for text-to-speech and voice conversion using multi-source Tacotron and WaveNet
Apr 07, 2019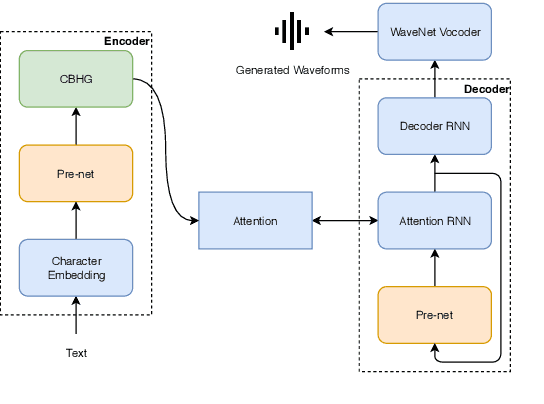
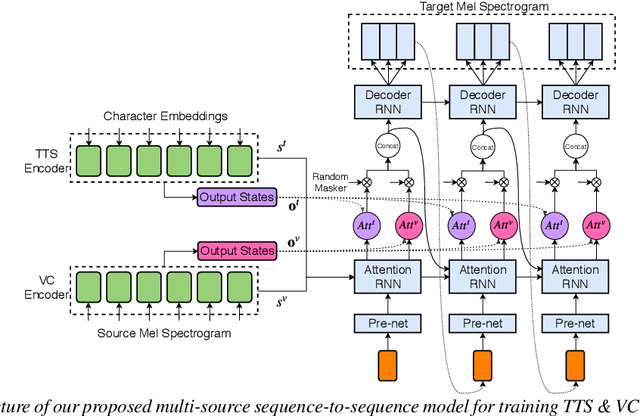
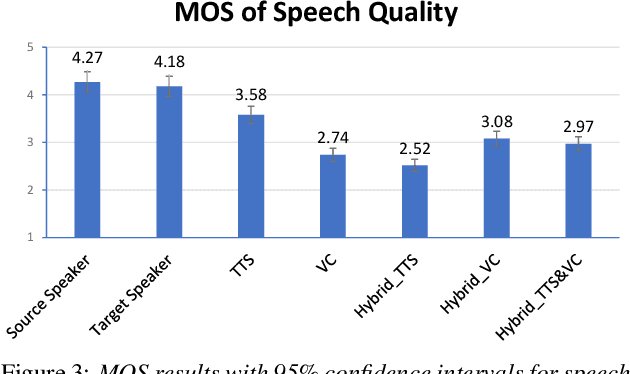
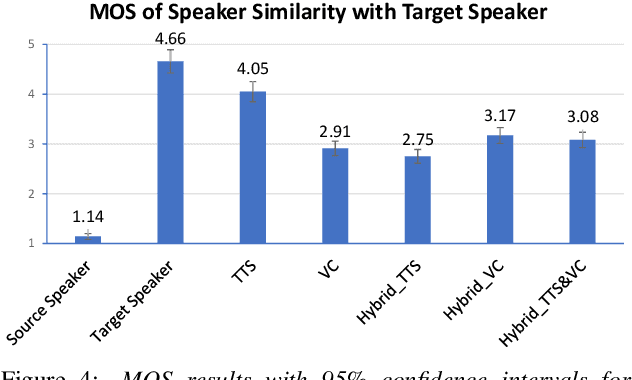
We investigated the training of a shared model for both text-to-speech (TTS) and voice conversion (VC) tasks. We propose using an extended model architecture of Tacotron, that is a multi-source sequence-to-sequence model with a dual attention mechanism as the shared model for both the TTS and VC tasks. This model can accomplish these two different tasks respectively according to the type of input. An end-to-end speech synthesis task is conducted when the model is given text as the input while a sequence-to-sequence voice conversion task is conducted when it is given the speech of a source speaker as the input. Waveform signals are generated by using WaveNet, which is conditioned by using a predicted mel-spectrogram. We propose jointly training a shared model as a decoder for a target speaker that supports multiple sources. Listening experiments show that our proposed multi-source encoder-decoder model can efficiently achieve both the TTS and VC tasks.
Audiovisual speaker conversion: jointly and simultaneously transforming facial expression and acoustic characteristics
Oct 29, 2018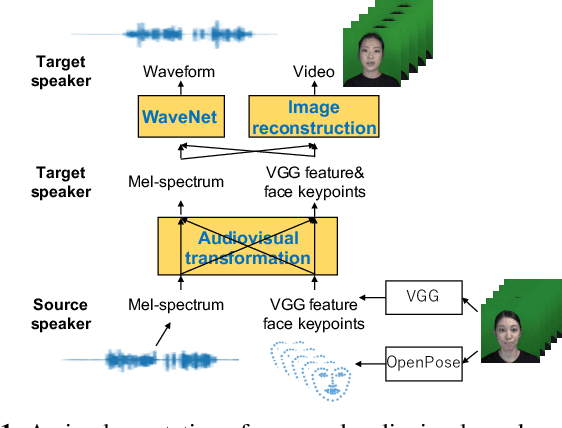
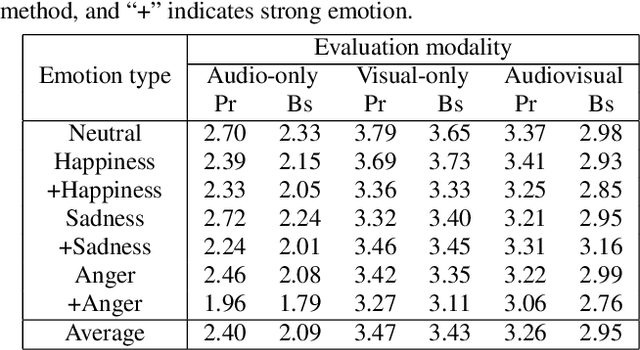
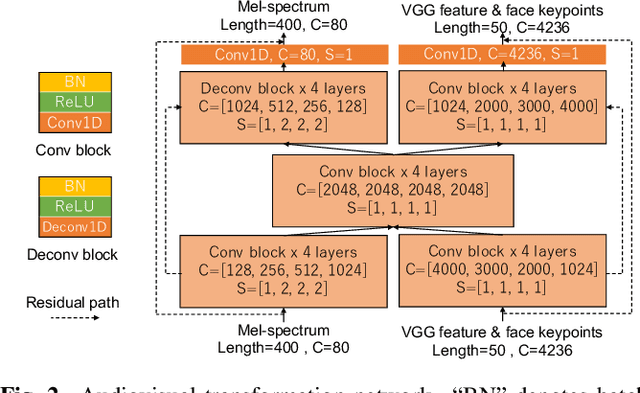
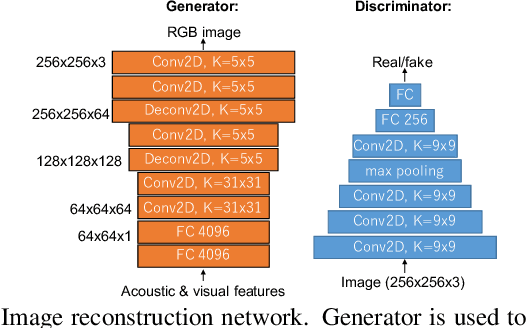
An audiovisual speaker conversion method is presented for simultaneously transforming the facial expressions and voice of a source speaker into those of a target speaker. Transforming the facial and acoustic features together makes it possible for the converted voice and facial expressions to be highly correlated and for the generated target speaker to appear and sound natural. It uses three neural networks: a conversion network that fuses and transforms the facial and acoustic features, a waveform generation network that produces the waveform from both the converted facial and acoustic features, and an image reconstruction network that outputs an RGB facial image also based on both the converted features. The results of experiments using an emotional audiovisual database showed that the proposed method achieved significantly higher naturalness compared with one that separately transformed acoustic and facial features.
High-quality nonparallel voice conversion based on cycle-consistent adversarial network
Apr 02, 2018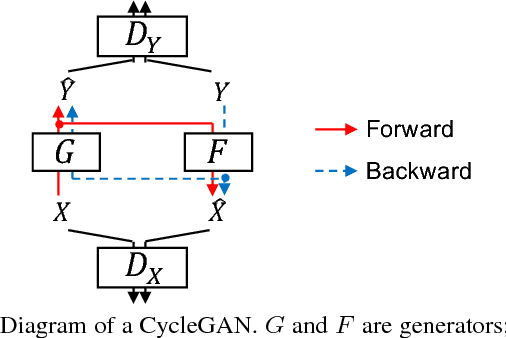
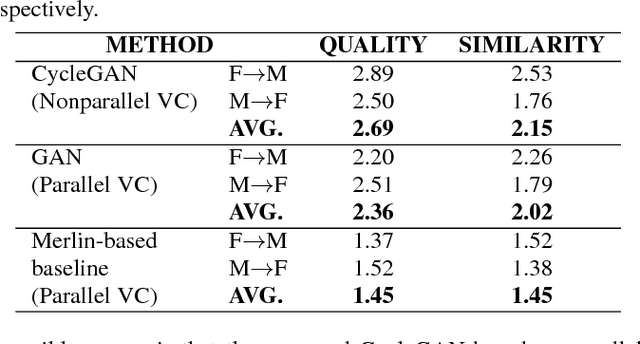
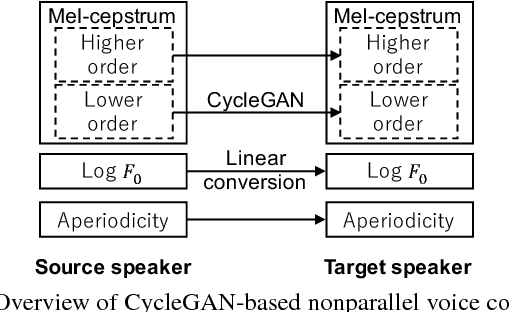
Although voice conversion (VC) algorithms have achieved remarkable success along with the development of machine learning, superior performance is still difficult to achieve when using nonparallel data. In this paper, we propose using a cycle-consistent adversarial network (CycleGAN) for nonparallel data-based VC training. A CycleGAN is a generative adversarial network (GAN) originally developed for unpaired image-to-image translation. A subjective evaluation of inter-gender conversion demonstrated that the proposed method significantly outperformed a method based on the Merlin open source neural network speech synthesis system (a parallel VC system adapted for our setup) and a GAN-based parallel VC system. This is the first research to show that the performance of a nonparallel VC method can exceed that of state-of-the-art parallel VC methods.