 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual speaker conversion: jointly and simultaneously transforming facial expression and acoustic characteristics
Paper and Code
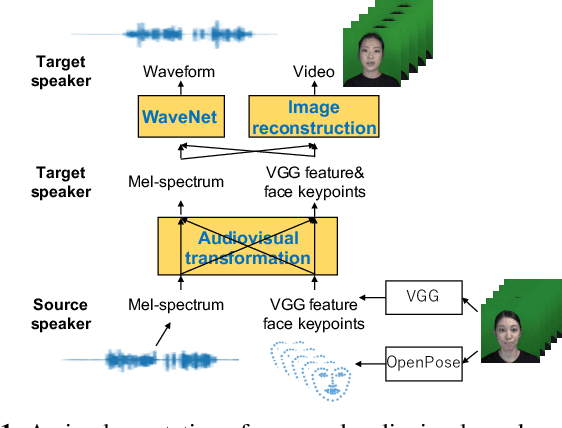
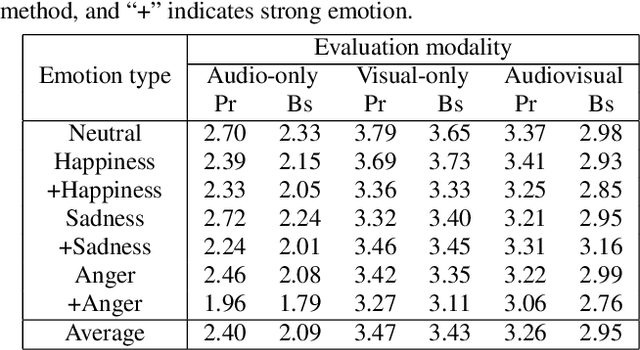
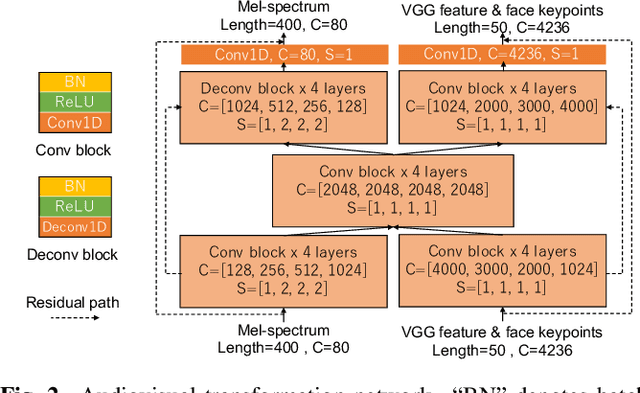
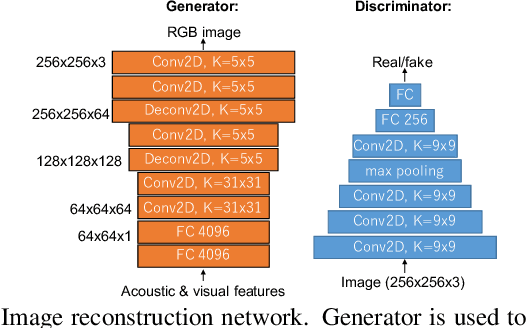
An audiovisual speaker conversion method is presented for simultaneously transforming the facial expressions and voice of a source speaker into those of a target speaker. Transforming the facial and acoustic features together makes it possible for the converted voice and facial expressions to be highly correlated and for the generated target speaker to appear and sound natural. It uses three neural networks: a conversion network that fuses and transforms the facial and acoustic features, a waveform generation network that produces the waveform from both the converted facial and acoustic features, and an image reconstruction network that outputs an RGB facial image also based on both the converted features. The results of experiments using an emotional audiovisual database showed that the proposed method achieved significantly higher naturalness compared with one that separately transformed acoustic and facial features.