 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepfake Word Detection by Next-token Prediction using Fine-tuned Whisper
Feb 26, 2026Deepfake speech utterances can be forged by replacing one or more words in a bona fide utterance with semantically different words synthesized by speech generative models. While a dedicated synthetic word detector could be developed, we investigate a cost-effective method that fine-tunes a pre-trained Whisper model to detect synthetic words while transcribing the input utterance via next-token prediction. We further investigate using partially vocoded utterances as the fine-tuning data, thereby reducing the cost of data collection. Our experiments demonstrate that, on in-domain test data, the fine-tuned Whisper yields low synthetic-word detection error rates and transcription error rates. On out-of-domain test data with synthetic words produced by unseen speech generative models, the fine-tuned Whisper remains on par with a dedicated ResNet-based detection model; however, the overall performance degradation calls for strategies to improve its generalization capability.
Self Voice Conversion as an Attack against Neural Audio Watermarking
Jan 28, 2026Audio watermarking embeds auxiliary information into speech while maintaining speaker identity, linguistic content, and perceptual quality. Although recent advances in neural and digital signal processing-based watermarking methods have improved imperceptibility and embedding capacity, robustness is still primarily assessed against conventional distortions such as compression, additive noise, and resampling. However, the rise of deep learning-based attacks introduces novel and significant threats to watermark security. In this work, we investigate self voice conversion as a universal, content-preserving attack against audio watermarking systems. Self voice conversion remaps a speaker's voice to the same identity while altering acoustic characteristics through a voice conversion model. We demonstrate that this attack severely degrades the reliability of state-of-the-art watermarking approaches and highlight its implications for the security of modern audio watermarking techniques.
Summary of The Inaugural Music Source Restoration Challenge
Jan 07, 2026Music Source Restoration (MSR) aims to recover original, unprocessed instrument stems from professionally mixed and degraded audio, requiring the reversal of both production effects and real-world degradations. We present the inaugural MSR Challenge, which features objective evaluation on studio-produced mixtures using Multi-Mel-SNR, Zimtohrli, and FAD-CLAP, alongside subjective evaluation on real-world degraded recordings. Five teams participated in the challenge. The winning system achieved 4.46 dB Multi-Mel-SNR and 3.47 MOS-Overall, corresponding to relative improvements of 91% and 18% over the second-place system, respectively. Per-stem analysis reveals substantial variation in restoration difficulty across instruments, with bass averaging 4.59 dB across all teams, while percussion averages only 0.29 dB. The dataset, evaluation protocols, and baselines are available at https://msrchallenge.com/.
Spoofing attack augmentation: can differently-trained attack models improve generalisation?
Sep 18, 2023


A reliable deepfake detector or spoofing countermeasure (CM) should be robust in the face of unpredictable spoofing attacks. To encourage the learning of more generaliseable artefacts, rather than those specific only to known attacks, CMs are usually exposed to a broad variety of different attacks during training. Even so, the performance of deep-learning-based CM solutions are known to vary, sometimes substantially, when they are retrained with different initialisations, hyper-parameters or training data partitions. We show in this paper that the potency of spoofing attacks, also deep-learning-based, can similarly vary according to training conditions, sometimes resulting in substantial degradations to detection performance. Nevertheless, while a RawNet2 CM model is vulnerable when only modest adjustments are made to the attack algorithm, those based upon graph attention networks and self-supervised learning are reassuringly robust. The focus upon training data generated with different attack algorithms might not be sufficient on its own to ensure generaliability; some form of spoofing attack augmentation at the algorithm level can be complementary.
Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems
Jun 13, 2023



We present Malafide, a universal adversarial attack against automatic speaker verification (ASV) spoofing countermeasures (CMs). By introducing convolutional noise using an optimised linear time-invariant filter, Malafide attacks can be used to compromise CM reliability while preserving other speech attributes such as quality and the speaker's voice. In contrast to other adversarial attacks proposed recently, Malafide filters are optimised independently of the input utterance and duration, are tuned instead to the underlying spoofing attack, and require the optimisation of only a small number of filter coefficients. Even so, they degrade CM performance estimates by an order of magnitude, even in black-box settings, and can also be configured to overcome integrated CM and ASV subsystems. Integrated solutions that use self-supervised learning CMs, however, are more robust, under both black-box and white-box settings.
Can spoofing countermeasure and speaker verification systems be jointly optimised?
Mar 31, 2023Spoofing countermeasure (CM) and automatic speaker verification (ASV) sub-systems can be used in tandem with a backend classifier as a solution to the spoofing aware speaker verification (SASV) task. The two sub-systems are typically trained independently to solve different tasks. While our previous work demonstrated the potential of joint optimisation, it also showed a tendency to over-fit to speakers and a lack of sub-system complementarity. Using only a modest quantity of auxiliary data collected from new speakers, we show that joint optimisation degrades the performance of separate CM and ASV sub-systems, but that it nonetheless improves complementarity, thereby delivering superior SASV performance. Using standard SASV evaluation data and protocols, joint optimisation reduces the equal error rate by 27\% relative to performance obtained using fixed, independently-optimised sub-systems under like-for-like training conditions.
Explainable deepfake and spoofing detection: an attack analysis using SHapley Additive exPlanations
Feb 28, 2022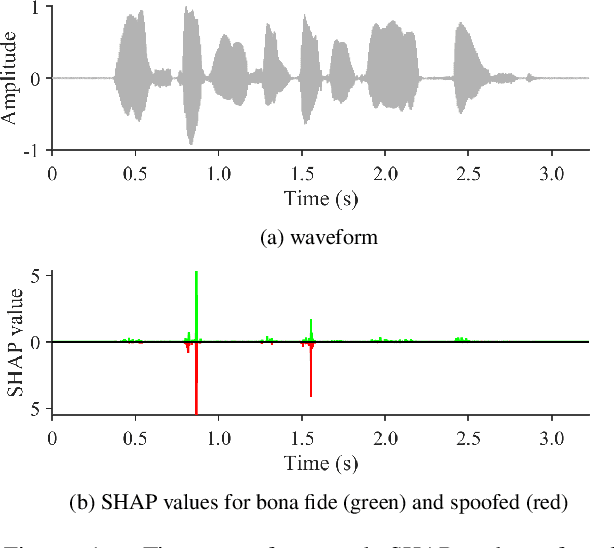
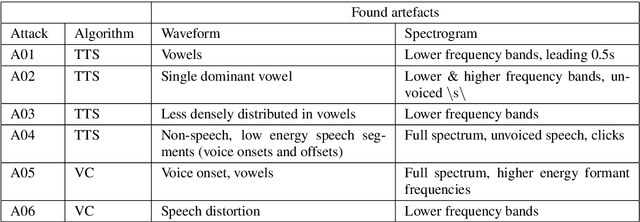
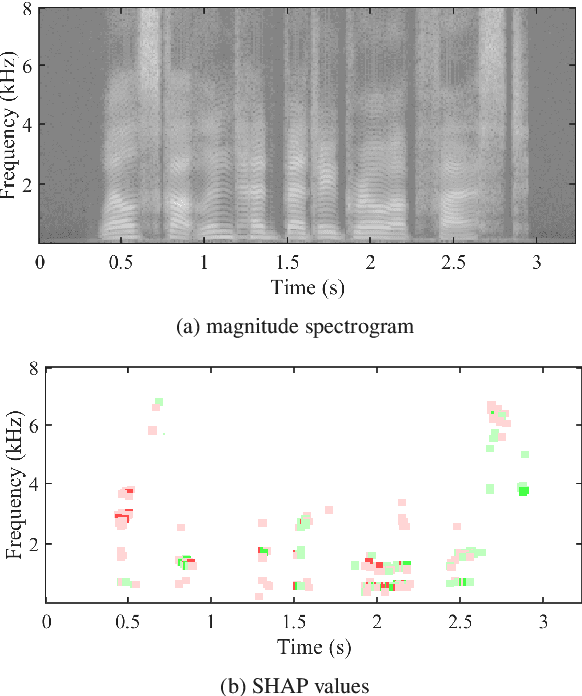
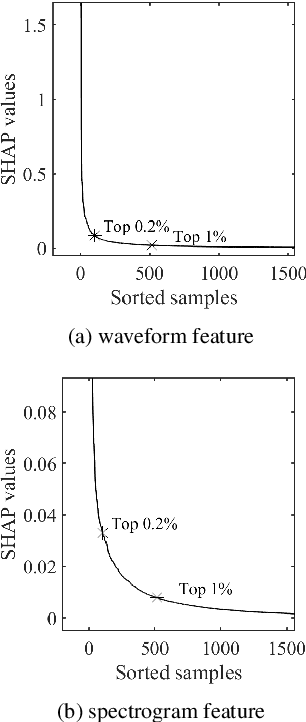
Despite several years of research in deepfake and spoofing detection for automatic speaker verification, little is known about the artefacts that classifiers use to distinguish between bona fide and spoofed utterances. An understanding of these is crucial to the design of trustworthy, explainable solutions. In this paper we report an extension of our previous work to better understand classifier behaviour to the use of SHapley Additive exPlanations (SHAP) to attack analysis. Our goal is to identify the artefacts that characterise utterances generated by different attacks algorithms. Using a pair of classifiers which operate either upon raw waveforms or magnitude spectrograms, we show that visualisations of SHAP results can be used to identify attack-specific artefacts and the differences and consistencies between synthetic speech and converted voice spoofing attacks.
Explaining deep learning models for spoofing and deepfake detection with SHapley Additive exPlanations
Oct 07, 2021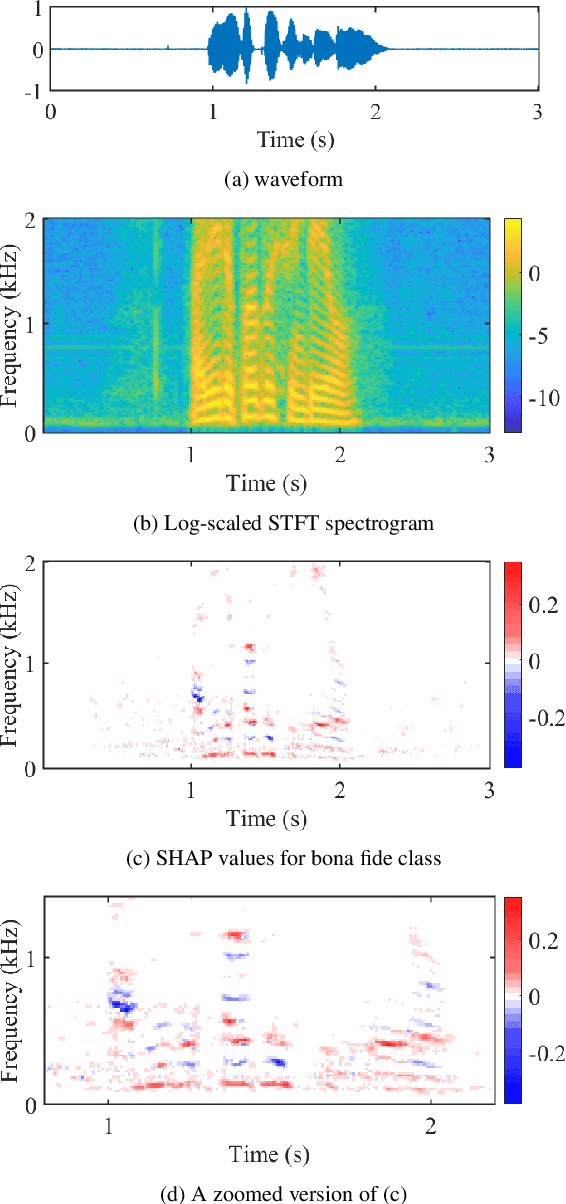
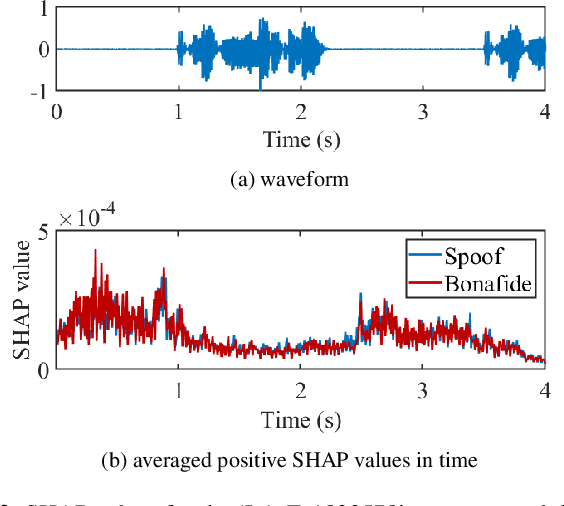
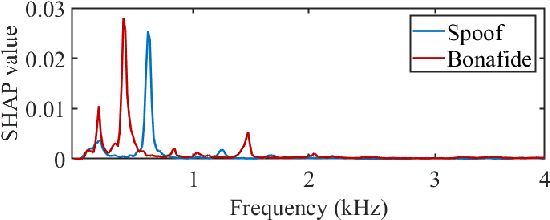
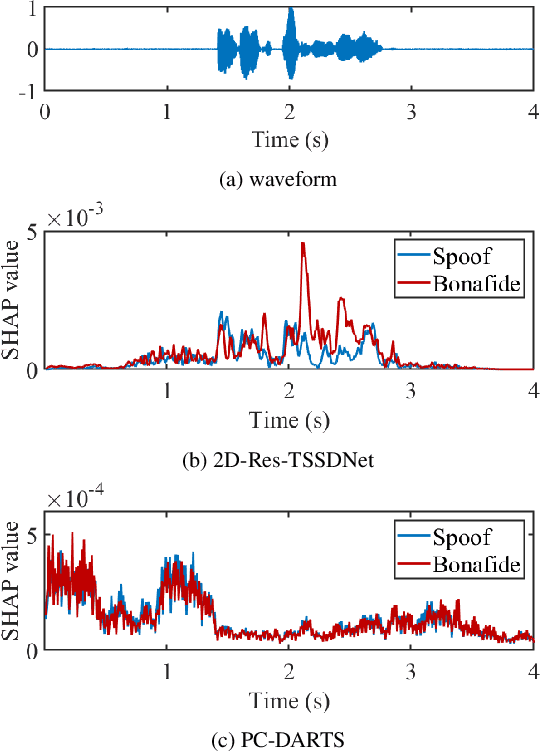
Substantial progress in spoofing and deepfake detection has been made in recent years. Nonetheless, the community has yet to make notable inroads in providing an explanation for how a classifier produces its output. The dominance of black box spoofing detection solutions is at further odds with the drive toward trustworthy, explainable artificial intelligence. This paper describes our use of SHapley Additive exPlanations (SHAP) to gain new insights in spoofing detection. We demonstrate use of the tool in revealing unexpected classifier behaviour, the artefacts that contribute most to classifier outputs and differences in the behaviour of competing spoofing detection models. The tool is both efficient and flexible, being readily applicable to a host of different architecture models in addition to related, different applications. All results reported in the paper are reproducible using open-source software.
Raw Differentiable Architecture Search for Speech Deepfake and Spoofing Detection
Jul 26, 2021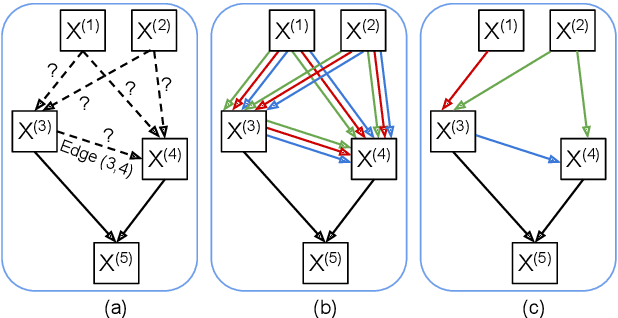
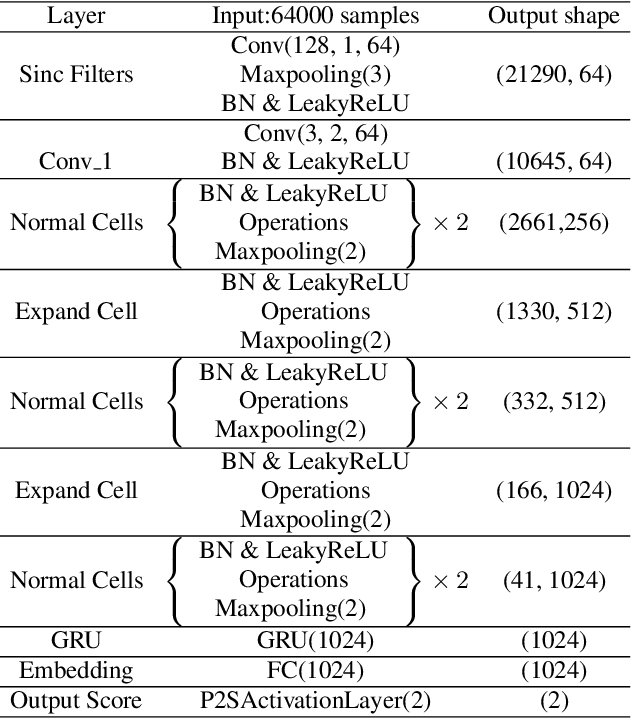

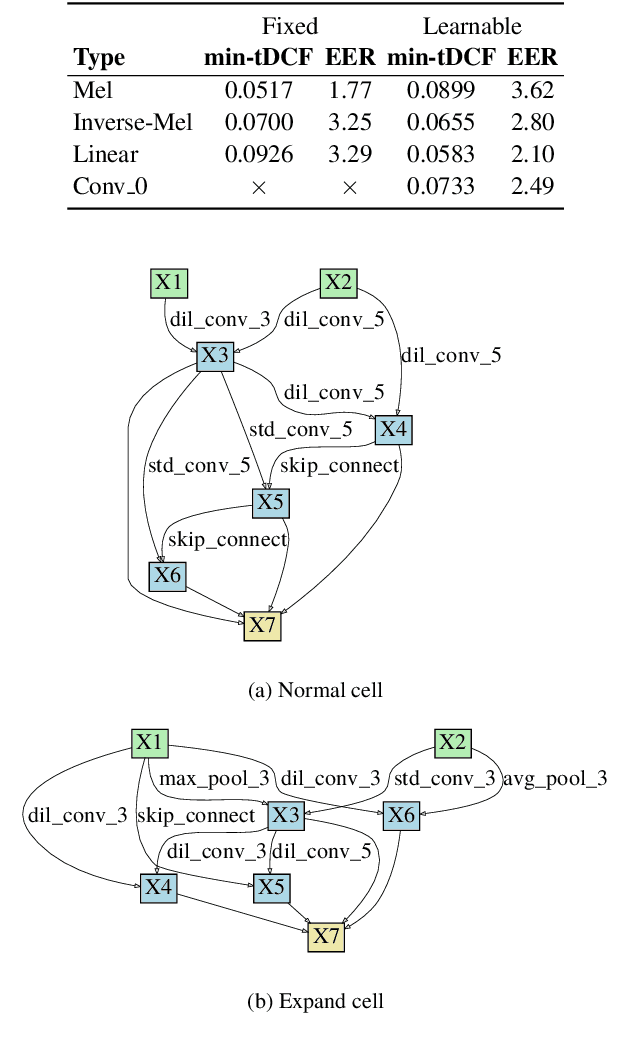
End-to-end approaches to anti-spoofing, especially those which operate directly upon the raw signal, are starting to be competitive with their more traditional counterparts. Until recently, all such approaches consider only the learning of network parameters; the network architecture is still hand crafted. This too, however, can also be learned. Described in this paper is our attempt to learn automatically the network architecture of a speech deepfake and spoofing detection solution, while jointly optimising other network components and parameters, such as the first convolutional layer which operates on raw signal inputs. The resulting raw differentiable architecture search system delivers a tandem detection cost function score of 0.0517 for the ASVspoof 2019 logical access database, a result which is among the best single-system results reported to date.
Partially-Connected Differentiable Architecture Search for Deepfake and Spoofing Detection
Apr 07, 2021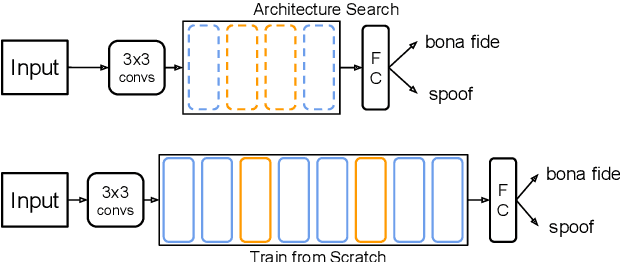
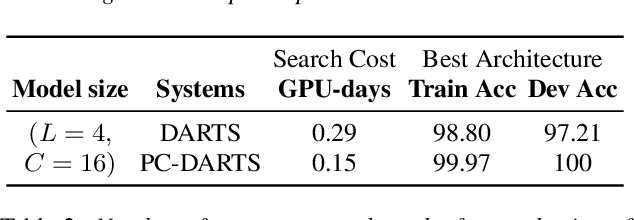
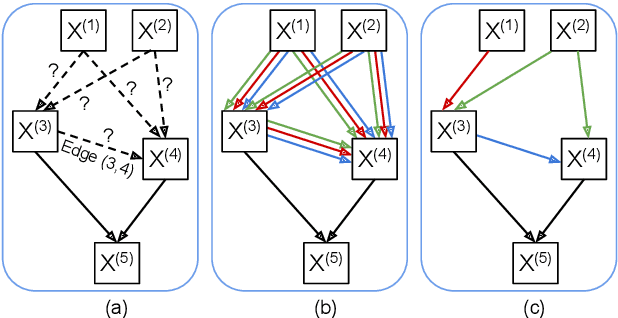
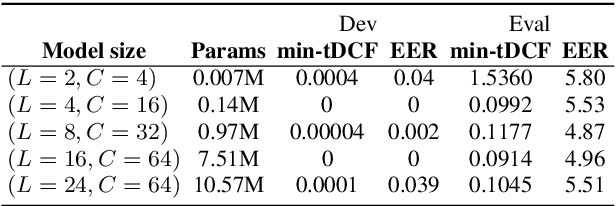
This paper reports the first successful application of a differentiable architecture search (DARTS) approach to the deepfake and spoofing detection problems. An example of neural architecture search, DARTS operates upon a continuous, differentiable search space which enables both the architecture and parameters to be optimised via gradient descent. Solutions based on partially-connected DARTS use random channel masking in the search space to reduce GPU time and automatically learn and optimise complex neural architectures composed of convolutional operations and residual blocks. Despite being learned quickly with little human effort, the resulting networks are competitive with the best performing systems reported in the literature. Some are also far less complex, containing 85% fewer parameters than a Res2Net competitor.