 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn investigation of modularity for noise robustness in conformer-based ASR
Sep 09, 2024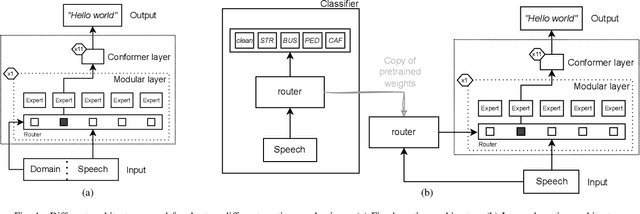
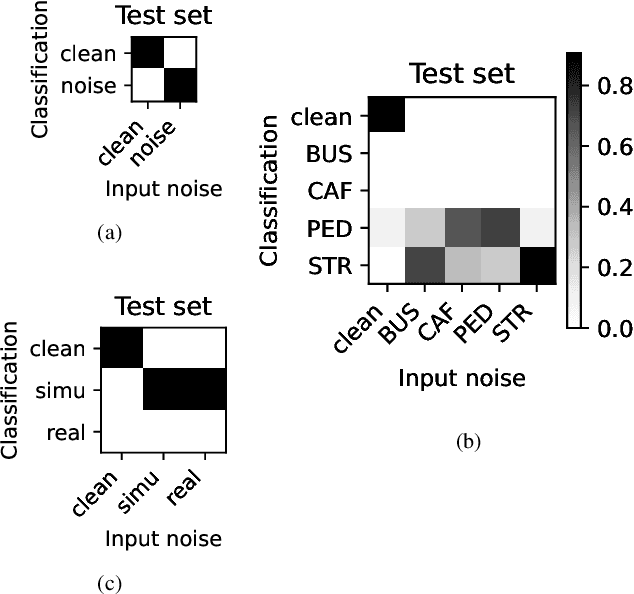


Whilst state of the art automatic speech recognition (ASR) can perform well, it still degrades when exposed to acoustic environments that differ from those used when training the model. Unfamiliar environments for a given model may well be known a-priori, but yield comparatively small amounts of adaptation data. In this experimental study, we investigate to what extent recent formalisations of modularity can aid adaptation of ASR to new acoustic environments. Using a conformer based model and fixed routing, we confirm that environment awareness can indeed lead to improved performance in known environments. However, at least on the (CHIME) datasets in the study, it is difficult for a classifier module to distinguish different noisy environments, a simpler distinction between noisy and clean speech being the optimal configuration. The results have clear implications for deploying large models in particular environments with or without a-priori knowledge of the environmental noise.
Low-Level Physiological Implications of End-to-End Learning of Speech Recognition
Aug 22, 2022


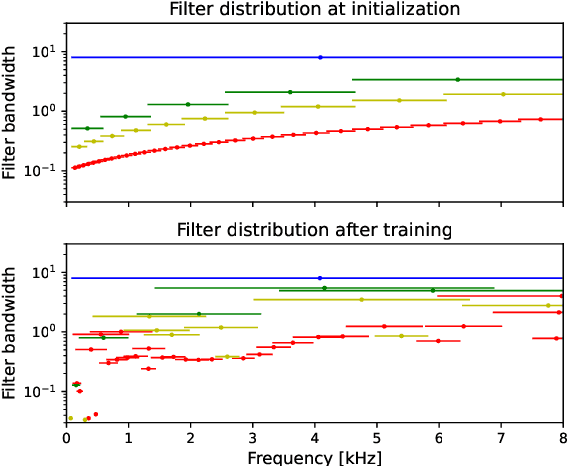
Current speech recognition architectures perform very well from the point of view of machine learning, hence user interaction. This suggests that they are emulating the human biological system well. We investigate whether the inference can be inverted to provide insights into that biological system; in particular the hearing mechanism. Using SincNet, we confirm that end-to-end systems do learn well known filterbank structures. However, we also show that wider band-width filters are important in the learned structure. Whilst some benefits can be gained by initialising both narrow and wide-band filters, physiological constraints suggest that such filters arise in mid-brain rather than the cochlea. We show that standard machine learning architectures must be modified to allow this process to be emulated neurally.