 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Trial to Triumph: Advancing Long Video Understanding via Visual Context Sample Scaling and Self-reward Alignment
Mar 26, 2025Multi-modal Large language models (MLLMs) show remarkable ability in video understanding. Nevertheless, understanding long videos remains challenging as the models can only process a finite number of frames in a single inference, potentially omitting crucial visual information. To address the challenge, we propose generating multiple predictions through visual context sampling, followed by a scoring mechanism to select the final prediction. Specifically, we devise a bin-wise sampling strategy that enables MLLMs to generate diverse answers based on various combinations of keyframes, thereby enriching the visual context. To determine the final prediction from the sampled answers, we employ a self-reward by linearly combining three scores: (1) a frequency score indicating the prevalence of each option, (2) a marginal confidence score reflecting the inter-intra sample certainty of MLLM predictions, and (3) a reasoning score for different question types, including clue-guided answering for global questions and temporal self-refocusing for local questions. The frequency score ensures robustness through majority correctness, the confidence-aligned score reflects prediction certainty, and the typed-reasoning score addresses cases with sparse key visual information using tailored strategies. Experiments show that this approach covers the correct answer for a high percentage of long video questions, on seven datasets show that our method improves the performance of three MLLMs.
Knowledge-Enhanced Dual-stream Zero-shot Composed Image Retrieval
Mar 24, 2024We study the zero-shot Composed Image Retrieval (ZS-CIR) task, which is to retrieve the target image given a reference image and a description without training on the triplet datasets. Previous works generate pseudo-word tokens by projecting the reference image features to the text embedding space. However, they focus on the global visual representation, ignoring the representation of detailed attributes, e.g., color, object number and layout. To address this challenge, we propose a Knowledge-Enhanced Dual-stream zero-shot composed image retrieval framework (KEDs). KEDs implicitly models the attributes of the reference images by incorporating a database. The database enriches the pseudo-word tokens by providing relevant images and captions, emphasizing shared attribute information in various aspects. In this way, KEDs recognizes the reference image from diverse perspectives. Moreover, KEDs adopts an extra stream that aligns pseudo-word tokens with textual concepts, leveraging pseudo-triplets mined from image-text pairs. The pseudo-word tokens generated in this stream are explicitly aligned with fine-grained semantics in the text embedding space. Extensive experiments on widely used benchmarks, i.e. ImageNet-R, COCO object, Fashion-IQ and CIRR, show that KEDs outperforms previous zero-shot composed image retrieval methods.
Text Augmented Spatial-aware Zero-shot Referring Image Segmentation
Oct 27, 2023



In this paper, we study a challenging task of zero-shot referring image segmentation. This task aims to identify the instance mask that is most related to a referring expression without training on pixel-level annotations. Previous research takes advantage of pre-trained cross-modal models, e.g., CLIP, to align instance-level masks with referring expressions. %Yet, CLIP only considers image-text pair level alignment, which neglects fine-grained image region and complex sentence matching. Yet, CLIP only considers the global-level alignment of image-text pairs, neglecting fine-grained matching between the referring sentence and local image regions. To address this challenge, we introduce a Text Augmented Spatial-aware (TAS) zero-shot referring image segmentation framework that is training-free and robust to various visual encoders. TAS incorporates a mask proposal network for instance-level mask extraction, a text-augmented visual-text matching score for mining the image-text correlation, and a spatial rectifier for mask post-processing. Notably, the text-augmented visual-text matching score leverages a $P$ score and an $N$-score in addition to the typical visual-text matching score. The $P$-score is utilized to close the visual-text domain gap through a surrogate captioning model, where the score is computed between the surrogate model-generated texts and the referring expression. The $N$-score considers the fine-grained alignment of region-text pairs via negative phrase mining, encouraging the masked image to be repelled from the mined distracting phrases. Extensive experiments are conducted on various datasets, including RefCOCO, RefCOCO+, and RefCOCOg. The proposed method clearly outperforms state-of-the-art zero-shot referring image segmentation methods.
Jointly Harnessing Prior Structures and Temporal Consistency for Sign Language Video Generation
Jul 08, 2022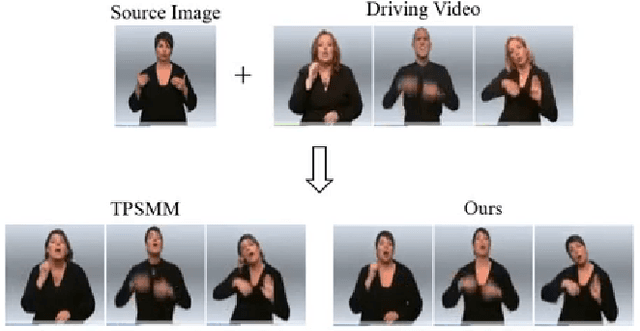

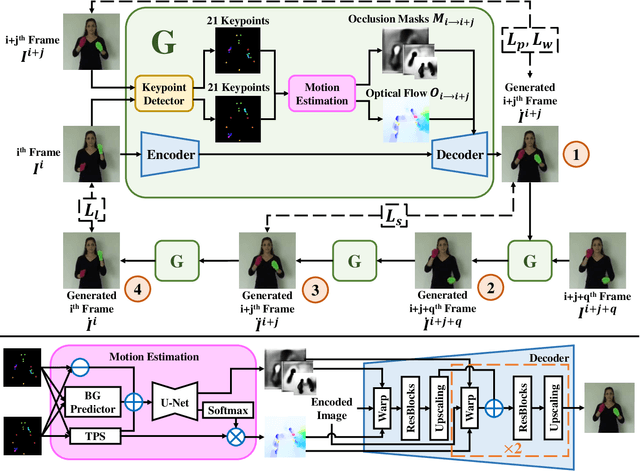

Sign language is the window for people differently-abled to express their feelings as well as emotions. However, it remains challenging for people to learn sign language in a short time. To address this real-world challenge, in this work, we study the motion transfer system, which can transfer the user photo to the sign language video of specific words. In particular, the appearance content of the output video comes from the provided user image, while the motion of the video is extracted from the specified tutorial video. We observe two primary limitations in adopting the state-of-the-art motion transfer methods to sign language generation:(1) Existing motion transfer works ignore the prior geometrical knowledge of the human body. (2) The previous image animation methods only take image pairs as input in the training stage, which could not fully exploit the temporal information within videos. In an attempt to address the above-mentioned limitations, we propose Structure-aware Temporal Consistency Network (STCNet) to jointly optimize the prior structure of human with the temporal consistency for sign language video generation. There are two main contributions in this paper. (1) We harness a fine-grained skeleton detector to provide prior knowledge of the body keypoints. In this way, we ensure the keypoint movement in a valid range and make the model become more explainable and robust. (2) We introduce two cycle-consistency losses, i.e., short-term cycle loss and long-term cycle loss, which are conducted to assure the continuity of the generated video. We optimize the two losses and keypoint detector network in an end-to-end manner.