 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Harnessing Prior Structures and Temporal Consistency for Sign Language Video Generation
Paper and Code
Jul 08, 2022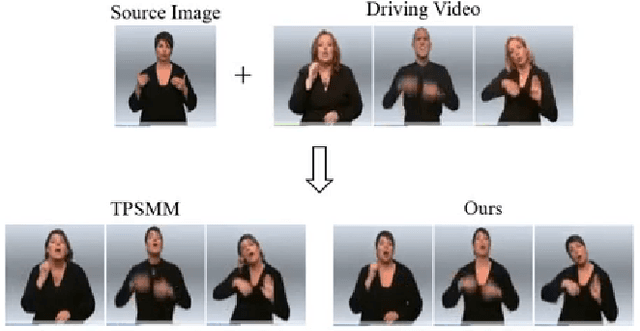

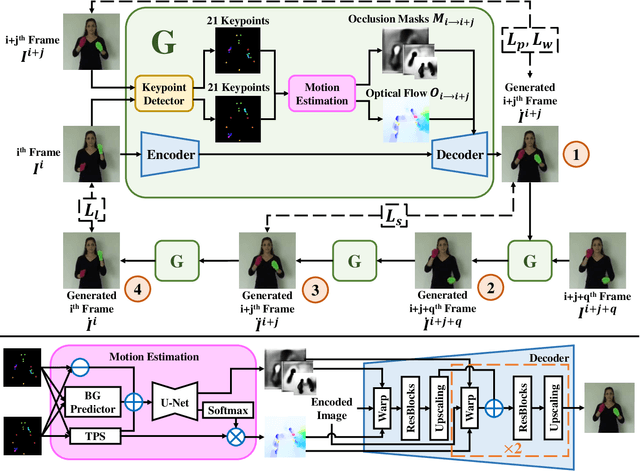

Sign language is the window for people differently-abled to express their feelings as well as emotions. However, it remains challenging for people to learn sign language in a short time. To address this real-world challenge, in this work, we study the motion transfer system, which can transfer the user photo to the sign language video of specific words. In particular, the appearance content of the output video comes from the provided user image, while the motion of the video is extracted from the specified tutorial video. We observe two primary limitations in adopting the state-of-the-art motion transfer methods to sign language generation:(1) Existing motion transfer works ignore the prior geometrical knowledge of the human body. (2) The previous image animation methods only take image pairs as input in the training stage, which could not fully exploit the temporal information within videos. In an attempt to address the above-mentioned limitations, we propose Structure-aware Temporal Consistency Network (STCNet) to jointly optimize the prior structure of human with the temporal consistency for sign language video generation. There are two main contributions in this paper. (1) We harness a fine-grained skeleton detector to provide prior knowledge of the body keypoints. In this way, we ensure the keypoint movement in a valid range and make the model become more explainable and robust. (2) We introduce two cycle-consistency losses, i.e., short-term cycle loss and long-term cycle loss, which are conducted to assure the continuity of the generated video. We optimize the two losses and keypoint detector network in an end-to-end manner.