 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactuality Matters: When Image Generation and Editing Meet Structured Visuals
Oct 06, 2025While modern visual generation models excel at creating aesthetically pleasing natural images, they struggle with producing or editing structured visuals like charts, diagrams, and mathematical figures, which demand composition planning, text rendering, and multimodal reasoning for factual fidelity. To address this, we present the first comprehensive, systematic investigation of this domain, encompassing data construction, model training, and an evaluation benchmark. First, we construct a large-scale dataset of 1.3 million high-quality structured image pairs derived from executable drawing programs and augmented with chain-of-thought reasoning annotations. Building on it, we train a unified model that integrates a VLM with FLUX.1 Kontext via a lightweight connector for enhanced multimodal understanding. A three-stage training curriculum enables progressive feature alignment, knowledge infusion, and reasoning-augmented generation, further boosted by an external reasoner at inference time. Finally, we introduce StructBench, a novel benchmark for generation and editing with over 1,700 challenging instances, and an accompanying evaluation metric, StructScore, which employs a multi-round Q\&A protocol to assess fine-grained factual accuracy. Evaluations of 15 models reveal that even leading closed-source systems remain far from satisfactory. Our model attains strong editing performance, and inference-time reasoning yields consistent gains across diverse architectures. By releasing the dataset, model, and benchmark, we aim to advance unified multimodal foundations for structured visuals.
RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation
Jun 07, 2025Recent advances in vision-language models (VLMs) have enabled instruction-conditioned robotic systems with improved generalization. However, most existing work focuses on reactive System 1 policies, underutilizing VLMs' strengths in semantic reasoning and long-horizon planning. These System 2 capabilities-characterized by deliberative, goal-directed thinking-remain under explored due to the limited temporal scale and structural complexity of current benchmarks. To address this gap, we introduce RoboCerebra, a benchmark for evaluating high-level reasoning in long-horizon robotic manipulation. RoboCerebra includes: (1) a large-scale simulation dataset with extended task horizons and diverse subtask sequences in household environments; (2) a hierarchical framework combining a high-level VLM planner with a low-level vision-language-action (VLA) controller; and (3) an evaluation protocol targeting planning, reflection, and memory through structured System 1-System 2 interaction. The dataset is constructed via a top-down pipeline, where GPT generates task instructions and decomposes them into subtask sequences. Human operators execute the subtasks in simulation, yielding high-quality trajectories with dynamic object variations. Compared to prior benchmarks, RoboCerebra features significantly longer action sequences and denser annotations. We further benchmark state-of-the-art VLMs as System 2 modules and analyze their performance across key cognitive dimensions, advancing the development of more capable and generalizable robotic planners.
VideoEspresso: A Large-Scale Chain-of-Thought Dataset for Fine-Grained Video Reasoning via Core Frame Selection
Nov 22, 2024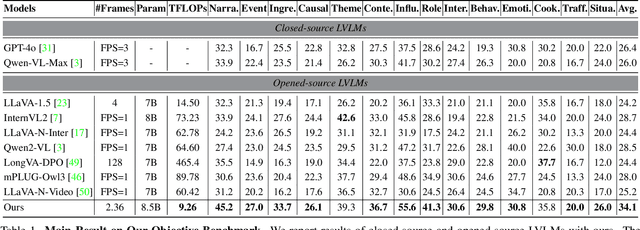
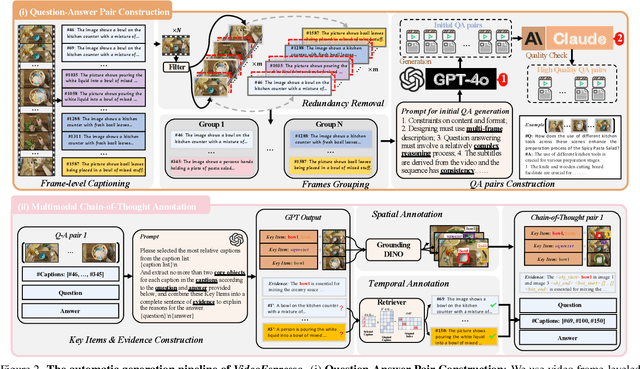
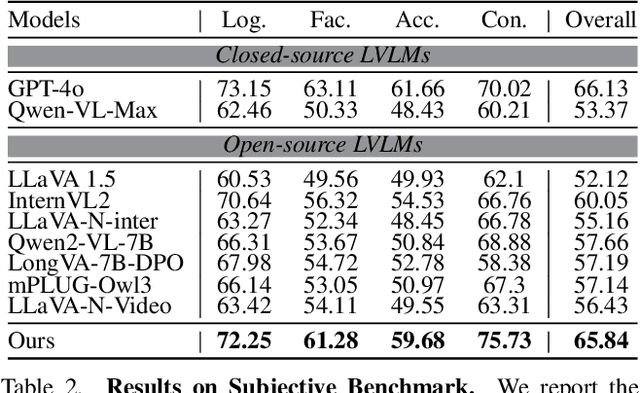
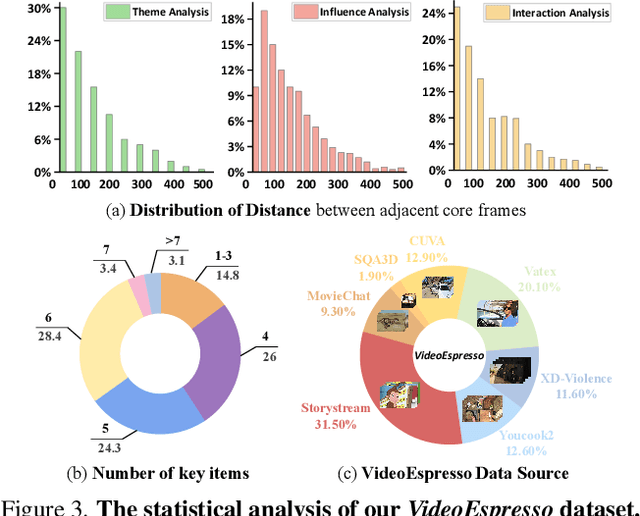
The advancement of Large Vision Language Models (LVLMs) has significantly improved multimodal understanding, yet challenges remain in video reasoning tasks due to the scarcity of high-quality, large-scale datasets. Existing video question-answering (VideoQA) datasets often rely on costly manual annotations with insufficient granularity or automatic construction methods with redundant frame-by-frame analysis, limiting their scalability and effectiveness for complex reasoning. To address these challenges, we introduce VideoEspresso, a novel dataset that features VideoQA pairs preserving essential spatial details and temporal coherence, along with multimodal annotations of intermediate reasoning steps. Our construction pipeline employs a semantic-aware method to reduce redundancy, followed by generating QA pairs using GPT-4o. We further develop video Chain-of-Thought (CoT) annotations to enrich reasoning processes, guiding GPT-4o in extracting logical relationships from QA pairs and video content. To exploit the potential of high-quality VideoQA pairs, we propose a Hybrid LVLMs Collaboration framework, featuring a Frame Selector and a two-stage instruction fine-tuned reasoning LVLM. This framework adaptively selects core frames and performs CoT reasoning using multimodal evidence. Evaluated on our proposed benchmark with 14 tasks against 9 popular LVLMs, our method outperforms existing baselines on most tasks, demonstrating superior video reasoning capabilities. Our code and dataset will be released at: https://github.com/hshjerry/VideoEspresso
Mask-Enhanced Segment Anything Model for Tumor Lesion Semantic Segmentation
Mar 09, 2024Tumor lesion segmentation on CT or MRI images plays a critical role in cancer diagnosis and treatment planning. Considering the inherent differences in tumor lesion segmentation data across various medical imaging modalities and equipment, integrating medical knowledge into the Segment Anything Model (SAM) presents promising capability due to its versatility and generalization potential. Recent studies have attempted to enhance SAM with medical expertise by pre-training on large-scale medical segmentation datasets. However, challenges still exist in 3D tumor lesion segmentation owing to tumor complexity and the imbalance in foreground and background regions. Therefore, we introduce Mask-Enhanced SAM (M-SAM), an innovative architecture tailored for 3D tumor lesion segmentation. We propose a novel Mask-Enhanced Adapter (MEA) within M-SAM that enriches the semantic information of medical images with positional data from coarse segmentation masks, facilitating the generation of more precise segmentation masks. Furthermore, an iterative refinement scheme is implemented in M-SAM to refine the segmentation masks progressively, leading to improved performance. Extensive experiments on seven tumor lesion segmentation datasets indicate that our M-SAM not only achieves high segmentation accuracy but also exhibits robust generalization.
LLMs as Visual Explainers: Advancing Image Classification with Evolving Visual Descriptions
Nov 20, 2023



Vision-language models (VLMs) offer a promising paradigm for image classification by comparing the similarity between images and class embeddings. A critical challenge lies in crafting precise textual representations for class names. While previous studies have leveraged recent advancements in large language models (LLMs) to enhance these descriptors, their outputs often suffer from ambiguity and inaccuracy. We identify two primary causes: 1) The prevalent reliance on textual interactions with LLMs, leading to a mismatch between the generated text and the visual content in VLMs' latent space - a phenomenon we term the "explain without seeing" dilemma. 2) The oversight of the inter-class relationships, resulting in descriptors that fail to differentiate similar classes effectively. To address these issues, we propose a novel image classification framework combining VLMs with LLMs, named Iterative Optimization with Visual Feedback. In particular, our method develops an LLM-based agent, employing an evolutionary optimization strategy to refine class descriptors. Crucially, we incorporate visual feedback from VLM classification metrics, thereby guiding the optimization process with concrete visual data. Our method leads to improving accuracy on a wide range of image classification benchmarks, with 3.47\% average gains over state-of-the-art methods. We also highlight the resulting descriptions serve as explainable and robust features that can consistently improve the performance across various backbone models.
VLSNR:Vision-Linguistics Coordination Time Sequence-aware News Recommendation
Oct 06, 2022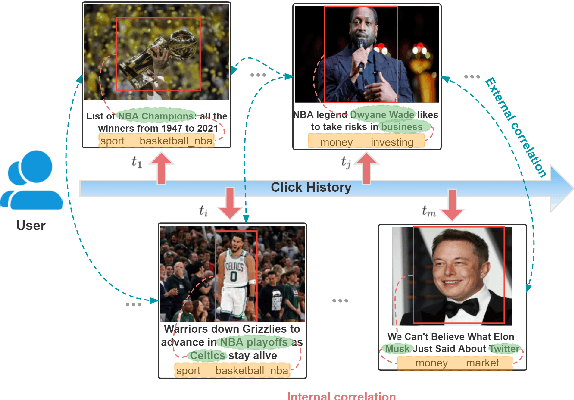

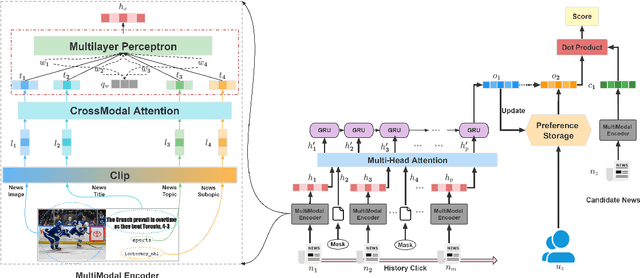
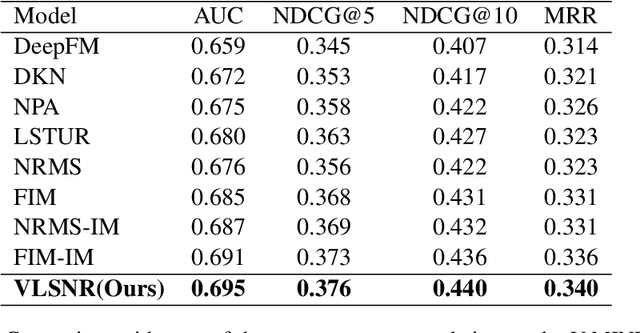
News representation and user-oriented modeling are both essential for news recommendation. Most existing methods are based on textual information but ignore the visual information and users' dynamic interests. However, compared to textual only content, multimodal semantics is beneficial for enhancing the comprehension of users' temporal and long-lasting interests. In our work, we propose a vision-linguistics coordinate time sequence news recommendation. Firstly, a pretrained multimodal encoder is applied to embed images and texts into the same feature space. Then the self-attention network is used to learn the chronological sequence. Additionally, an attentional GRU network is proposed to model user preference in terms of time adequately. Finally, the click history and user representation are embedded to calculate the ranking scores for candidate news. Furthermore, we also construct a large scale multimodal news recommendation dataset V-MIND. Experimental results show that our model outperforms baselines and achieves SOTA on our independently constructed dataset.