 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLSNR:Vision-Linguistics Coordination Time Sequence-aware News Recommendation
Oct 06, 2022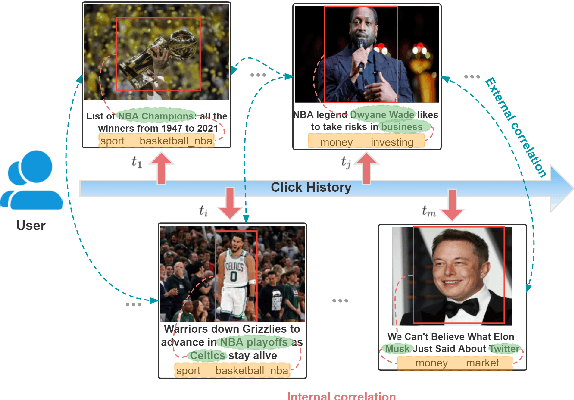

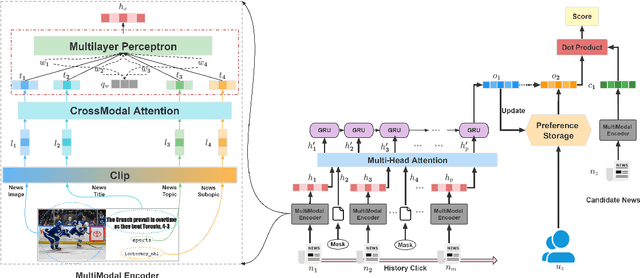
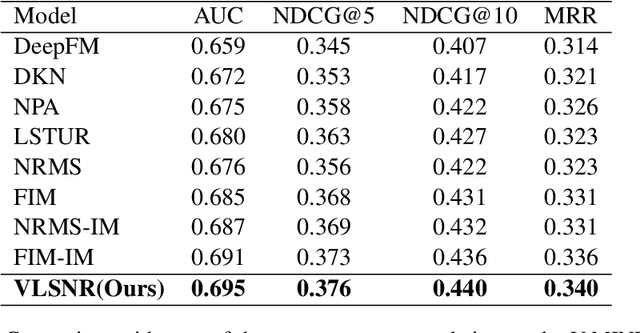
News representation and user-oriented modeling are both essential for news recommendation. Most existing methods are based on textual information but ignore the visual information and users' dynamic interests. However, compared to textual only content, multimodal semantics is beneficial for enhancing the comprehension of users' temporal and long-lasting interests. In our work, we propose a vision-linguistics coordinate time sequence news recommendation. Firstly, a pretrained multimodal encoder is applied to embed images and texts into the same feature space. Then the self-attention network is used to learn the chronological sequence. Additionally, an attentional GRU network is proposed to model user preference in terms of time adequately. Finally, the click history and user representation are embedded to calculate the ranking scores for candidate news. Furthermore, we also construct a large scale multimodal news recommendation dataset V-MIND. Experimental results show that our model outperforms baselines and achieves SOTA on our independently constructed dataset.